Eccoci qui. Sono passati quasi due decenni dall'inizio del 21° secolo e la necessità di una maggiore potenza di calcolo è ancora un problema. Le aziende tecnologiche stanno martellando il marciapiede per affrontare questo enorme problema frontalmente. Gli ingegneri hardware hanno trovato una soluzione alterando il modo in cui progettano e producono l'unità di elaborazione centrale (CPU) di un computer. Ora contengono più core, il che consente la concorrenza. A loro volta, gli sviluppatori di software hanno adattato il modo in cui scrivono i programmi per adattarsi a questo cambiamento nell'hardware.
La comunità di PostgreSQL ha sfruttato appieno queste CPU multi-core per migliorare le prestazioni delle query. Semplicemente aggiornando alle versioni 9.6 o successive, è possibile utilizzare una funzionalità chiamata parallelismo delle query per eseguire varie operazioni. Suddivide le attività in parti più piccole e distribuisce ciascuna attività su più core della CPU. Ogni core può elaborare le attività contemporaneamente. A causa delle limitazioni hardware, questo è l'unico modo per migliorare le prestazioni del computer mentre ci spostiamo nel futuro.
Prima di utilizzare la funzionalità di parallelismo nel database PostgreSQL, è essenziale riconoscere come rende parallela una query. Sarai in grado di eseguire il debug e risolvere eventuali problemi che si presentano.
Come funziona il parallelismo delle query?
Per avere una migliore comprensione di come viene eseguito il parallelismo, è una buona idea iniziare a livello di cliente. Per accedere a PostgreSQL, un client deve inviare una richiesta di connessione al server del database chiamato postmaster. Il postmaster completerà l'autenticazione e quindi eseguirà il fork per creare un nuovo processo server per ogni connessione. È anche responsabile della creazione di un'area di memoria condivisa che contiene un pool di buffer. Il pool di buffer sovrintende al trasferimento dei dati tra la memoria condivisa e lo storage. Pertanto, nel momento in cui viene stabilita una connessione, il pool di buffer trasferirà i dati e consentirà il parallelismo delle query.
Non è necessario che tutte le query siano parallele. Ci sono casi in cui è necessaria solo una piccola quantità di dati e può essere rapidamente elaborata da un solo core. Questa funzione viene utilizzata solo quando una query richiederà molto tempo per essere completata. L'ottimizzatore del database determina se eseguire il parallelismo. Se necessario, il database utilizzerà una porzione aggiuntiva di memoria denominata memoria condivisa dinamica (DSM). Ciò consente al processo leader e ai processi di lavoro paralleli di dividere la query tra più core e raccogliere dati pertinenti.
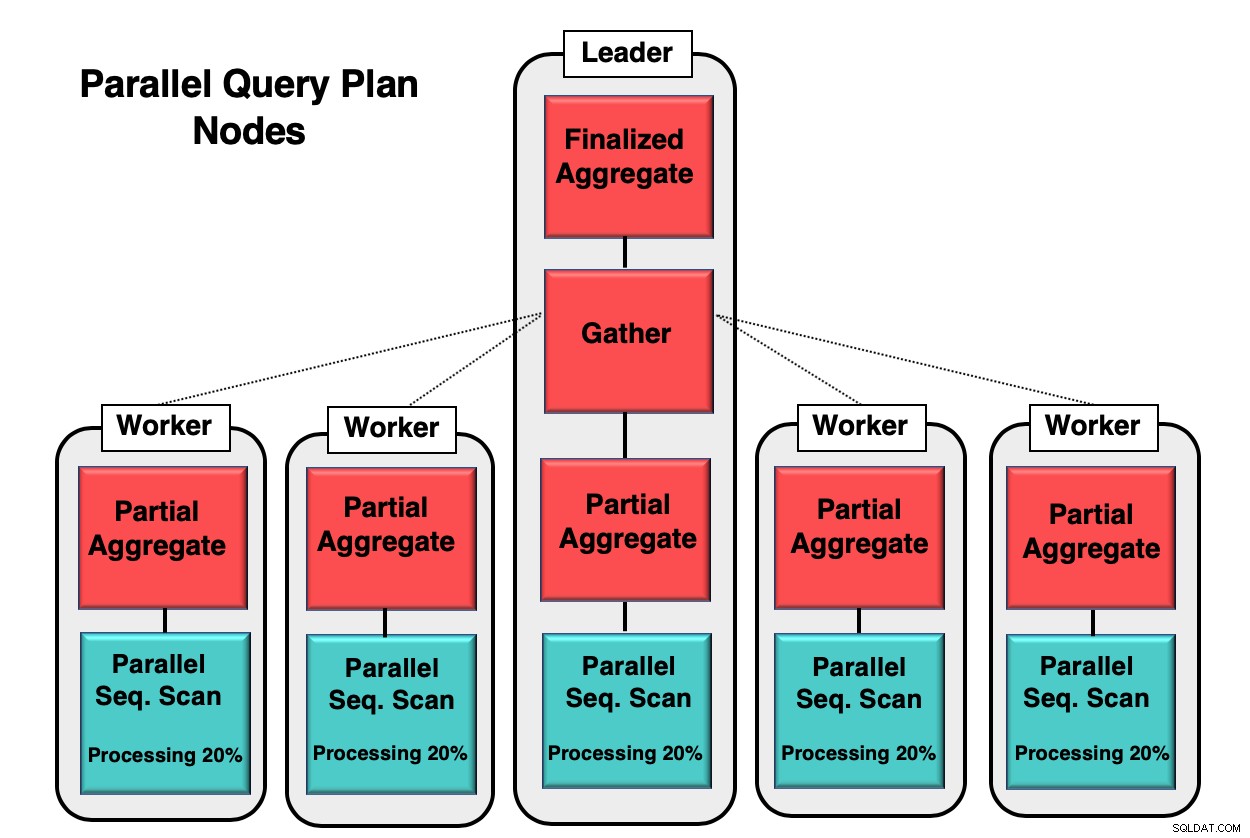
La figura 1 fornisce un esempio di come avviene il parallelismo all'interno del database. Il processo leader esegue la query iniziale, mentre i singoli processi di lavoro avviano una copia dello stesso processo. Il nodo aggregato parziale, o CPU core, è responsabile dell'implementazione della scansione sequenziale parallela della tabella del database.
In questo caso, ogni nodo di scansione sequenziale elabora il 20% dei dati in blocchi da 8 kb. Questi stessi nodi possono coordinare la loro attività utilizzando una tecnica chiamata parallela consapevole. Ogni nodo ha una conoscenza completa di quali dati sono già stati elaborati e di quali dati devono essere scansionati nella tabella per completare la query. Una volta che le tuple sono state raccolte per intero, vengono inviate al nodo di raccolta per essere compilate e finalizzate.
Operazioni parallele
Vari tipi di query possono essere utilizzati per recuperare dati da un database per produrre set di risultati. Ecco le operazioni specifiche che ti danno la possibilità di sfruttare in modo efficace l'uso di più core.
Scansione sequenziale
Questa è un'operazione che legge i dati in una tabella dall'inizio alla fine per raccogliere i dati. Distribuisce uniformemente il carico di lavoro tra più core per aumentare la velocità di elaborazione delle query. È a conoscenza di ogni attività dei core, rendendo più semplice determinare se l'intera query è stata completata. Il nodo di raccolta riceve quindi i dati estratti in base alla query.
Aggregazione
Un'operazione standard, che richiede una grande quantità di dati e la condensa in un numero inferiore di righe. Ciò avviene durante l'elaborazione parallela solo estraendo da una tabella o da indici le informazioni appropriate in base alla query. L'esecuzione di una media di dati specifici è un ottimo esempio di aggregazione.
Unisciti all'hash
Una tecnica utilizzata per unire i dati tra due tabelle. È l'algoritmo di join più veloce, che viene in genere eseguito con una tabella piccola e una grande. Per prima cosa crei una tabella hash e carichi tutti i dati da una tabella lì. Quindi puoi scansionare tutti i dati dall'hash e dalla seconda tabella, usando la scansione sequenziale parallela. Ogni tupla estratta dalla scansione viene confrontata con la tabella hash per vedere se c'è una corrispondenza. Se viene identificata una corrispondenza, i dati vengono uniti. Con il rilascio di PostgreSQL 11, l'utilizzo del parallelismo per completare un hash join richiede circa un terzo del tempo di elaborazione precedente.
Unisci Unisciti
Se l'ottimizzatore determina che un hash join supererà la capacità di memoria, eseguirà invece un merge join. Il processo prevede la scansione di due elenchi ordinati contemporaneamente e unisce gli stessi elementi. Se gli elementi non sono uguali, i dati non verranno uniti.
Unisciti al loop nidificato
Questa operazione viene utilizzata quando è necessario unire due tabelle contenenti diversi linguaggi di programmazione, come Quick Basic, Python, ecc. Ogni tabella viene scansionata ed elaborata utilizzando più core. Se i dati corrispondono, vengono inviati al nodo di raccolta per essere uniti. Anche gli indici vengono scansionati, motivo per cui questo processo contiene più cicli per recuperare i dati. In media, ci vorrà solo un terzo del tempo per completare l'unione utilizzando il processo parallelo.
Scansione indice B-tree
Questa operazione esegue la scansione di un albero di dati ordinati per individuare informazioni specifiche. Questo processo richiede più tempo della tipica scansione sequenziale perché c'è molta attesa durante la ricerca dei record. Tuttavia, il lavoro di scansione dei dati appropriati è suddiviso tra più processori.
Scansione heap bitmap
È possibile unire più indici utilizzando questa operazione. Per prima cosa vuoi creare il numero equivalente di bitmap, poiché hai gli indici. Ad esempio, se hai tre indici, devi prima creare tre bitmap. Ogni bitmap recupererà e compilerà tuple in base alla query.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperParallelismo delle partizioni
Esiste un'altra forma di parallelismo che può aver luogo all'interno del database PostgreSQL. Tuttavia, non deriva dalla scansione delle tabelle e dalla rottura delle attività. È possibile partizionare o dividere i dati per valori specifici. Ad esempio, puoi prendere il valore degli acquirenti e fare in modo che un singolo core elabori i dati solo all'interno di quel valore. In questo modo, sai esattamente cosa sta elaborando ogni core in un dato momento.
Partizionamento hash
Questa operazione viene utilizzata distribuendo le righe della tabella in sottotabelle. Anche in questo caso, la divisione generalmente determinata da un valore distinto o da un elenco di valori da una tabella. Questo è un metodo eccellente da utilizzare se non si dispone di una tecnica di gestione dell'archiviazione efficiente su tutti i dispositivi. Dovresti utilizzare il partizionamento per distribuire i dati in modo casuale per evitare colli di bottiglia di I/O.
Partecipazione a livello di partizione
Una tecnica utilizzata per scomporre le tabelle in partizioni e unirle facendo corrispondere tra loro partizioni simili. Ad esempio, potresti avere una grande tabella di acquirenti provenienti da tutti gli Stati Uniti. Puoi prima suddividere la tabella per città diverse e quindi unire alcune città insieme in base alla regione in ogni stato. L'unione a livello di partizione semplifica i tuoi dati e consente la manipolazione delle tabelle.
In parallelo non sicuro
PostgreSQL 11 esegue automaticamente il parallelismo delle query se l'ottimizzatore determina che questo è il modo più veloce per completare la query. Maggiore è la versione di PostgreSQL che stai utilizzando, maggiore sarà la capacità parallela del tuo database. Sfortunatamente, non tutte le query dovrebbero essere eseguite in modo parallelo, anche se ne ha la capacità. Il tipo di query che stai eseguendo potrebbe avere limitazioni specifiche e richiederà che un solo core completi tutta l'elaborazione. Ciò rallenterà le prestazioni del tuo sistema, ma garantirà che i dati ricevuti siano integri.
Per garantire che le tue query non siano mai messe a rischio, gli sviluppatori hanno creato una funzione chiamata parallel unsafe. È possibile ignorare manualmente l'ottimizzatore di database e richiedere che la query non sia mai parallela. Il processo di parallelismo non verrà eseguito.
Il parallelismo all'interno del database PostgreSQL è una funzionalità che migliora solo con ogni versione del database. Anche se il futuro della tecnologia è incerto, sembra che l'uso di questa funzione sia destinato a durare.
Per ulteriori informazioni, puoi controllare quanto segue...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table