Questo blog è una breve presentazione di Jenkins e ti mostra come utilizzare questo strumento per aiutarti con alcune delle tue attività quotidiane di amministrazione e gestione di PostgreSQL.
Informazioni su Jenkins
Jenkins è un software open source per l'automazione. È sviluppato in Java ed è uno degli strumenti più popolari per l'integrazione continua (CI) e la distribuzione continua (CD).
Nel 2010, dopo l'acquisizione di Sun Microsystems da parte di Oracle, il software "Hudson" era in disputa con la sua comunità open source. Questa disputa è diventata la base per il lancio del progetto Jenkins.
Al giorno d'oggi, "Hudson" (licenza pubblica Eclipse) e "Jenkins" (licenza MIT) sono due progetti attivi e indipendenti con uno scopo molto simile.
Jenkins ha migliaia di plugin che puoi utilizzare per accelerare la fase di sviluppo attraverso l'automazione per l'intero ciclo di vita dello sviluppo; costruire, documentare, testare, creare pacchetti, creare fasi e distribuire.
Cosa fa Jenkins?
Sebbene l'uso principale di Jenkins possa essere Continuous Integration (CI) e Continuous Delivery (CD), questo open source ha una serie di funzionalità e può essere utilizzato senza alcun impegno o dipendenza da CI o CD, quindi Jenkins presenta alcune funzionalità interessanti per esplora:
- Programmazione dei lavori del periodo (invece di utilizzare il tradizionale crontab )
- Monitoraggio dei lavori, dei relativi registri e attività da una vista pulita (poiché hanno un'opzione per il raggruppamento)
- La manutenzione dei lavori potrebbe essere eseguita facilmente; supponendo che Jenkins abbia una serie di opzioni per questo
- Impostazione e pianificazione dell'installazione del software (tramite Puppet) nello stesso host o in un altro.
- Pubblicazione di rapporti e invio di notifiche e-mail
Esecuzione di attività PostgreSQL in Jenkins
Ci sono tre attività comuni che uno sviluppatore PostgreSQL o un amministratore di database deve svolgere quotidianamente:
- Pianificazione ed esecuzione di script PostgreSQL
- Eseguire un processo PostgreSQL composto da tre o più script
- Integrazione continua (CI) per sviluppi PL/pgSQL
Per l'esecuzione di questi esempi, si presume che i server Jenkins e PostgreSQL (almeno la versione 9.5) siano installati e funzionino correttamente.
Pianificazione ed esecuzione di uno script PostgreSQL
Nella maggior parte dei casi l'implementazione di script PostgreSQL giornalieri (o periodici) per l'esecuzione di un'attività usuale come...
- Generazione di backup
- Testa il ripristino di un backup
- Esecuzione di una query a fini di reporting
- Pulisci e archivia i file di registro
- Richiamo di una procedura PL/pgSQL per eliminare le tabelle
È definito su crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shCome crontab non è il miglior strumento facile da usare per gestire questo tipo di pianificazione, può essere fatto su Jenkins con i seguenti vantaggi...
- Interfaccia molto intuitiva per monitorare i loro progressi e lo stato attuale
- I log sono immediatamente disponibili e non è necessaria alcuna concessione speciale per accedervi
- Il lavoro potrebbe essere eseguito manualmente su Jenkins invece di avere una pianificazione
- Per alcuni tipi di lavori, non è necessario definire utenti e password in file di testo normale poiché Jenkins lo fa in modo sicuro
- I lavori possono essere definiti come un'esecuzione API
Quindi, potrebbe essere una buona soluzione migrare i lavori relativi alle attività PostgreSQL su Jenkins anziché su crontab.
D'altra parte, la maggior parte degli amministratori di database e degli sviluppatori ha forti competenze nei linguaggi di scripting e sarebbe facile per loro sviluppare piccole interfacce per gestire questi script per implementare i processi automatizzati con l'obiettivo di migliorare i propri compiti. Ma ricorda, molto probabilmente Jenkins ha già una serie di funzioni per farlo e queste funzionalità possono semplificare la vita agli sviluppatori che scelgono di usarle.
Quindi per definire l'esecuzione dello script è necessario creare un nuovo lavoro, selezionando l'opzione “Nuovo elemento”.
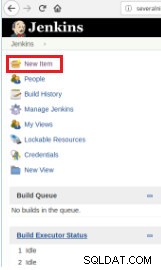 Figura 1 – "Nuovo elemento" per definire un lavoro per eseguire uno script PostgreSQL
Figura 1 – "Nuovo elemento" per definire un lavoro per eseguire uno script PostgreSQL Quindi, dopo averlo nominato, scegli il tipo "Progetti FreeStyle" e fai clic su OK.
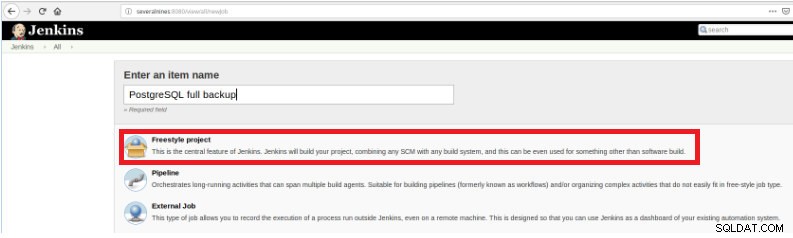 Figura 2 – Selezione del tipo di lavoro (elemento)
Figura 2 – Selezione del tipo di lavoro (elemento) Per terminare la creazione di questo nuovo job, nella sezione “Build” deve essere selezionata l'opzione “Execute script” e nella casella della riga di comando il percorso e la parametrizzazione dello script che verrà eseguito:
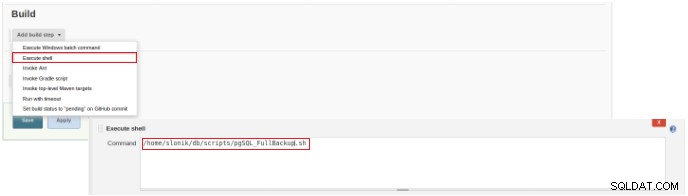 Figura 3 – Specifica del comando da eseguire
Figura 3 – Specifica del comando da eseguire Per questo tipo di lavoro è consigliabile verificare i permessi degli script, perché è necessario impostare almeno l'esecuzione per il gruppo di appartenenza del file e per tutti.
In questo esempio, lo script query.sh ha le autorizzazioni di lettura ed esecuzione per tutti, le autorizzazioni di lettura ed esecuzione per il gruppo e le autorizzazioni di lettura ed esecuzione per l'utente:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Questo script ha un set di istruzioni molto semplice, in pratica chiama solo l'utilità psql per eseguire query:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datEsecuzione di un processo PostgreSQL composto da tre o più script
In questo esempio, descriverò ciò di cui hai bisogno per eseguire tre diversi script al fine di nascondere i dati sensibili e per questo seguiremo i passaggi seguenti...
- Importa dati da file
- Prepara i dati da mascherare
- Backup del database con dati mascherati
Quindi, per definire questo nuovo lavoro è necessario selezionare l'opzione “Nuovo articolo” nella pagina principale di Jenkins e poi, dopo aver assegnato un nome, si deve scegliere l'opzione “Pipeline”:
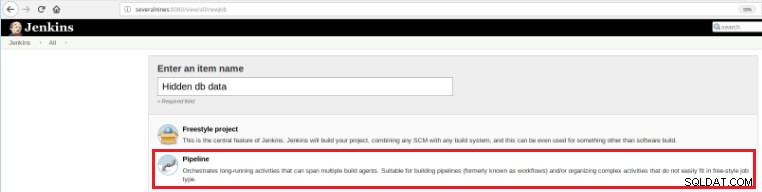 Figura 5 - Elemento della pipeline in Jenkins
Figura 5 - Elemento della pipeline in Jenkins Una volta salvato il lavoro nella sezione "Pipeline", nella scheda "Opzioni avanzate di progetto", il campo "Definizione" deve essere impostato su "Script Pipeline", come mostrato di seguito:
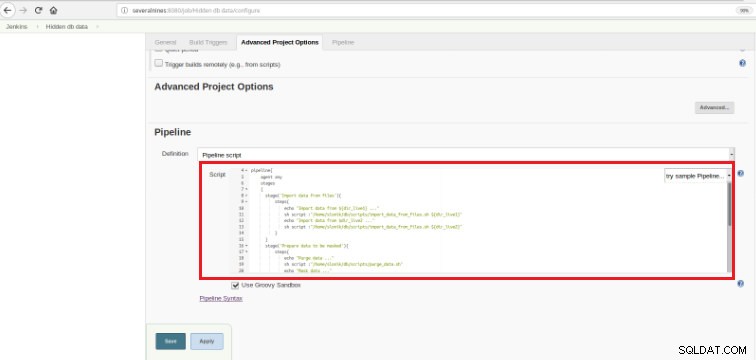 Figura 6 - Script Groovy nella sezione pipeline
Figura 6 - Script Groovy nella sezione pipeline Come ho accennato all'inizio del capitolo, lo script Groovy utilizzato è composto da tre fasi, ovvero tre parti (fasi) distinte, come presentato nel seguente script:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy è un linguaggio di programmazione orientato agli oggetti compatibile con la sintassi Java per la piattaforma Java. È un linguaggio sia statico che dinamico con caratteristiche simili a quelle di Python, Ruby, Perl e Smalltalk.
È facile da capire poiché questo tipo di script si basa su poche affermazioni...
Fase
Indica i 3 processi che verranno eseguiti:“Importa dati da file”, “Prepara dati da mascherare”
e “Backup del database con dati mascherati”.
Passo
Una "fase" (spesso chiamata "fase di compilazione") è un'attività singola che fa parte di una sequenza. Ogni fase può essere composta da più fasi. In questo esempio, la prima fase ha due passaggi.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'I dati vengono importati da due fonti distinte.
Nell'esempio precedente, è importante notare che ci sono due variabili definite all'inizio e con un ambito globale:
dir_live1
dir_live2Gli script utilizzati in questi tre passaggi chiamano psql , pg_restore e pg_dump utilità.
Una volta definito il lavoro, è il momento di eseguirlo e per questo è sufficiente fare clic sull'opzione "Costruisci ora":
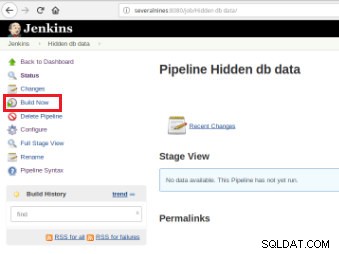 Figura 7 – Processo di esecuzione
Figura 7 – Processo di esecuzione Dopo l'avvio della costruzione è possibile verificarne lo stato di avanzamento.
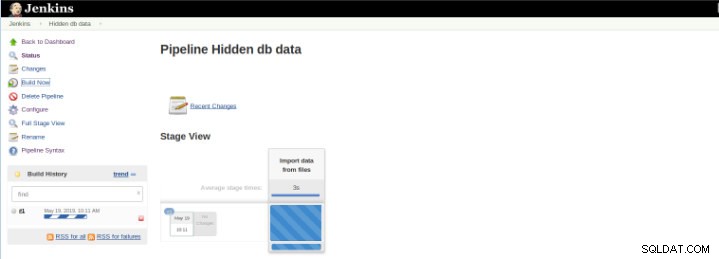 Figura 8 – Avvio di "Build"
Figura 8 – Avvio di "Build" Il plug-in Pipeline Stage View include una visualizzazione estesa della cronologia di compilazione della pipeline nella pagina dell'indice di un progetto di flusso in Stage View. Questa visualizzazione viene creata non appena le attività vengono completate e ciascuna attività è rappresentata da una colonna da sinistra a destra ed è possibile visualizzare e confrontare il tempo trascorso per le esecuzioni serval (noto come Build in Jenkins).
Una volta terminata l'esecuzione (detta anche Build), è possibile ottenere ulteriori dettagli, cliccando sul thread finito (riquadro rosso).
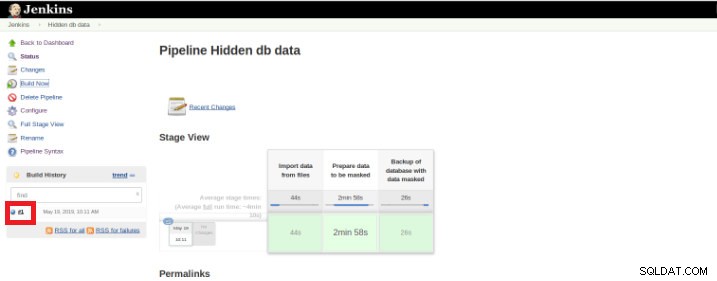 Figura 9 – Avvio di "Build"
Figura 9 – Avvio di "Build" e poi nell'opzione "Uscita console".
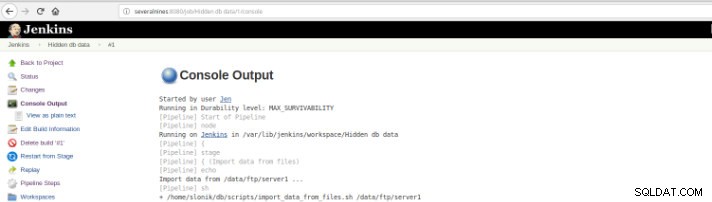 Figura 10 – Output della console
Figura 10 – Output della console Le viste precedenti sono di estrema utilità in quanto consentono di avere una percezione del tempo di esecuzione richiesto per ogni fase.
Pipelines, noto anche come flusso di lavoro, è un plug-in che consente la definizione del ciclo di vita dell'applicazione ed è una funzionalità utilizzata in Jenkins per la distribuzione continua (CD).vQuesto plug-in è stato creato con i requisiti per una capacità di flusso di lavoro CD flessibile, estensibile e basata su script in mente.
Questo esempio serve per nascondere i dati sensibili, ma sicuramente ci sono molti altri esempi su base giornaliera di amministratore di database PostgreSQL che possono essere eseguiti su un lavoro di pipeline.
Pipeline è disponibile su Jenkins dalla versione 2.0 ed è una soluzione incredibile!

Integrazione continua (CI) per sviluppi PL/pgSQL
L'integrazione continua per lo sviluppo del database non è facile come in altri linguaggi di programmazione a causa dei dati che possono andare persi, quindi non è facile mantenere il database sotto il controllo del codice sorgente e distribuirlo su un server dedicato soprattutto quando ci sono gli script che contengono istruzioni DDL (Data Definition Language) e DML (Data Manipulation Language). Questo perché questo tipo di istruzioni modifica lo stato corrente del database e, a differenza di altri linguaggi di programmazione, non c'è codice sorgente da compilare.
Esistono invece un insieme di istruzioni di database per le quali è possibile l'integrazione continua come per altri linguaggi di programmazione.
Questo esempio si basa solo sullo sviluppo di procedure e illustrerà l'attivazione di una serie di test (scritti in Python) da Jenkins una volta che gli script PostgreSQL, su cui è memorizzato il codice delle seguenti funzioni, sono stati impegnati in un repository di codice.
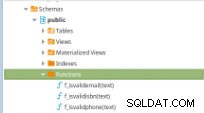 Figura 11 – Funzioni PLpg/SQL
Figura 11 – Funzioni PLpg/SQL Queste funzioni sono semplici e il loro contenuto ha solo poche logiche o una query in PLpg/SQL o plperlu lingua come la funzione f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Tutte le funzioni qui presentate non dipendono l'una dall'altra e quindi non c'è precedenza né nel suo sviluppo né nel suo impiego. Inoltre, poiché verrà verificato in seguito, non vi è alcuna dipendenza dalle loro convalide.
Quindi, per eseguire una serie di script di validazione una volta eseguito un commit in un repository di codice è necessaria la creazione di un build job (nuovo elemento) in Jenkins:
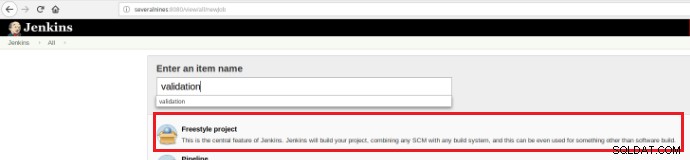 Figura 12 – Progetto "Freestyle" per l'integrazione continua
Figura 12 – Progetto "Freestyle" per l'integrazione continua Questo nuovo lavoro di build deve essere creato come progetto "Freestyle" e nella sezione "Repository del codice sorgente" deve essere definito l'URL del repository e le sue credenziali (riquadro arancione):
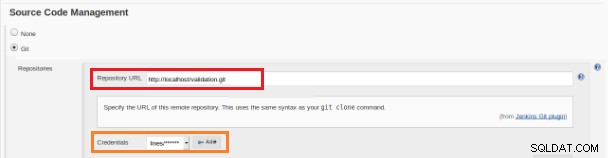 Figura 13 – Repository del codice sorgente
Figura 13 – Repository del codice sorgente Nella sezione "Build Triggers" è necessario selezionare l'opzione "GitHub hook trigger for GITScm polling":
 Figura 14 – Sezione "Crea trigger"
Figura 14 – Sezione "Crea trigger" Infine, nella sezione “Build”, deve essere selezionata l'opzione “Execute Shell” e nella casella di comando gli script che faranno la validazione delle funzioni sviluppate:
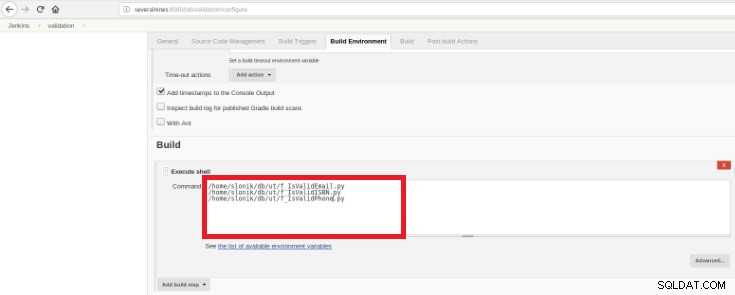 Figura 15 – Sezione "Ambiente di costruzione"
Figura 15 – Sezione "Ambiente di costruzione" Lo scopo è avere uno script di convalida per ogni funzione sviluppata.
Questo script Python ha un semplice insieme di istruzioni che chiamerà queste procedure da un database con alcuni risultati previsti predefiniti:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Questo script testerà il PLpg/SQL presentato o plperlu funzioni e verrà eseguito dopo ogni commit nel repository di codice per evitare regressioni sugli sviluppi.
Una volta eseguita questa creazione del lavoro, è possibile verificare le esecuzioni del registro.
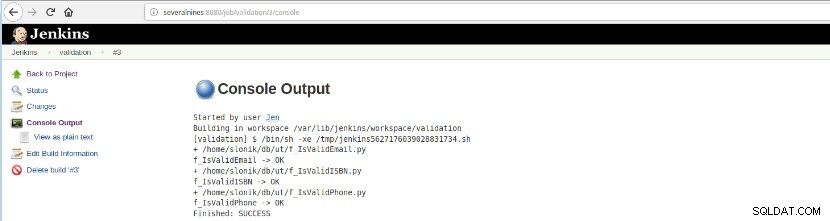 Figura 16 – "Uscita della console"
Figura 16 – "Uscita della console" Questa opzione presenta lo stato finale:SUCCESS o FAILURE, l'area di lavoro, i file/script eseguiti, i file temporanei creati e i messaggi di errore (per quelli falliti)!
Conclusione
In sintesi, Jenkins è noto come un ottimo strumento per l'integrazione continua (CI) e la distribuzione continua (CD), tuttavia può essere utilizzato per varie funzionalità come,
- Programmazione delle attività
- Esecuzione di script
- Processi di monitoraggio
Per tutti questi scopi su ogni esecuzione (costruire sul vocabolario Jenkins) è possibile analizzare i log e il tempo trascorso.
A causa dell'elevato numero di plugin disponibili potrebbe evitare alcuni sviluppi con uno scopo specifico, probabilmente c'è un plugin che fa esattamente quello che stai cercando, è solo questione di cercare nel centro aggiornamenti o Gestisci Jenkins>>Gestisci plugin all'interno l'applicazione web.



