Introduzione
Una tabella è una struttura logica. Quando crei una tabella, in genere non ti interessano le unità su cui si trova a livello di archiviazione. Tuttavia, se sei un amministratore di database, questa conoscenza può diventare essenziale se devi spostare determinate porzioni di database in uno spazio di archiviazione o volume alternativo. Quindi, potresti voler che le tabelle definite si trovino su un particolare volume o set di dischi.
I filegroup in SQL Server offrono quel livello di astrazione che ci consente di controllare la posizione fisica delle nostre strutture logiche:tabelle, indici, ecc.
Filegroup
Un filegroup è una struttura logica per il raggruppamento di file di dati in SQL Server. Se creiamo un filegroup e lo associamo a un set di file di dati, qualsiasi oggetto logico creato su quel filegroup si troverà fisicamente su quel set di file fisici.
Lo scopo principale di tale raggruppamento di file fisici è l'allocazione e il posizionamento dei dati. Ad esempio, vogliamo che i nostri dati di transazione siano archiviati su un set di dischi veloci. Allo stesso tempo, abbiamo bisogno dei dati storici archiviati su un altro set di dischi meno costosi. In uno scenario del genere, creeremmo il Tran tabella sul filegroup TXN e su TranHist tabella su un filegroup HIST diverso. Più avanti in questo articolo, vedremo come questo si traduce nell'avere i dati su dischi diversi.
Creazione di filegroup
La sintassi per la creazione di filegroup è mostrata nel Listato 1 . Nota :Il contesto del database è il master Banca dati. Nell'emettere le istruzioni, stiamo alterando il database DB2 aggiungendo nuovi filegroup ad esso. In sostanza, questi filegroup sono semplicemente costrutti logici a questo punto. Non contengono alcun dato.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Aggiunta di file ai filegroup
Il passaggio successivo consiste nell'aggiungere un file a ciascuno dei filegroup. Possiamo aggiungere più di un file, ma lo manteniamo semplice a scopo dimostrativo. Nota che ogni file si trova su un'unità completamente diversa e la sintassi ci consente di specificare il filegroup previsto.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Creazione di tabelle in filegroup
Qui assicuriamo che le tabelle siano sui dischi desiderati. La sintassi per la creazione di tabelle ci permette di specificare il filegroup che vogliamo.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Facendo un passo indietro, notiamo che ora abbiamo ottenuto quanto segue:
- Creato due filegroup.
- Determinati i file di dati (ei dischi) associati a ciascun filegroup.
- Determinate le tabelle associate a ciascun filegroup.
In sostanza, il filegroup è il livello di astrazione .
Controllare su quali filegroup si trovano le nostre tabelle
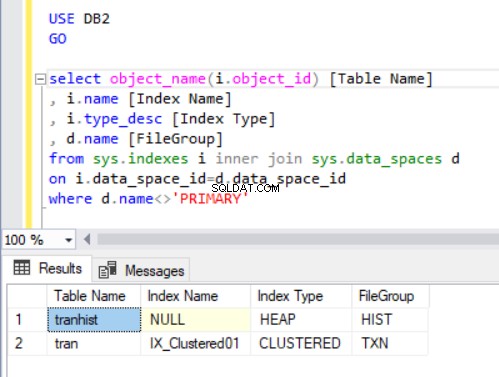
Per verificare a quale filegroup appartiene ciascuna tabella, eseguiremo il codice nel Listato 4. Utilizziamo due viste principali del catalogo di sistema:sys.indexes e sys.data_spaces . Gli sys.data_spaces la vista catalogo contiene informazioni su filegroup e partizioni e le principali strutture logiche in cui sono archiviate tabelle e indici.
Nota:non abbiamo utilizzato sys.tables . SQL Server associa gli indici in una tabella a spazi dati anziché a tabelle, come si potrebbe pensare intuitivamente.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
L'output della query nel Listato 4 mostra due tabelle che abbiamo appena creato. Nota che il tranista la tabella non ha un indice. Tuttavia, viene visualizzato nel set di risultati, identificato come un heap .
Un mucchio è una tabella che non ha un indice cluster che determina i dati dell'ordine fisicamente archiviati in una tabella. Può esserci un solo indice cluster in una tabella.
Popolare la tabella Tran
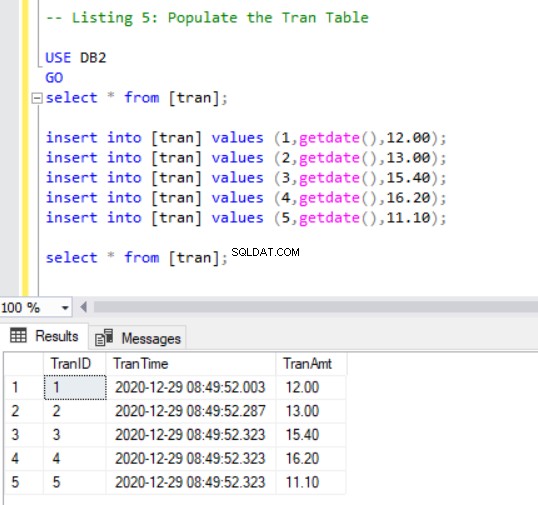
Ora dobbiamo aggiungere alcuni record a tran tabella utilizzando il seguente codice:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Spostare una tabella in un altro filegroup
Per spostare il tran tabella in un altro filegroup, dobbiamo solo ricompilare l'indice cluster e specifica il nuovo filegroup mentre esegui questa ricostruzione. Il Listato 5 mostra questo approccio.
Eseguiamo due passaggi:prima, rilascia l'indice, quindi ricrealo. Nel frattempo, controlliamo per confermare che i dati e la posizione delle due tabelle che abbiamo creato in precedenza rimangano intatti.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Eliminando l'indice cluster da tran tabella, l'abbiamo convertita in un heap :
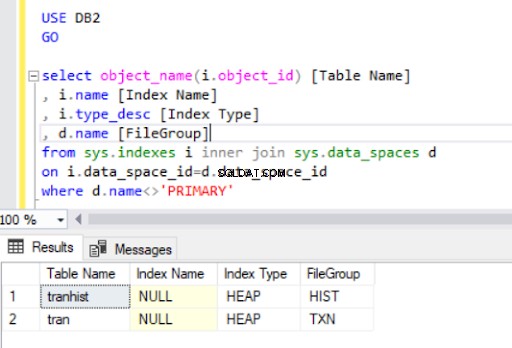
Quando ricreiamo l'indice cluster, viene indicato anche nell'output del Listato 4.
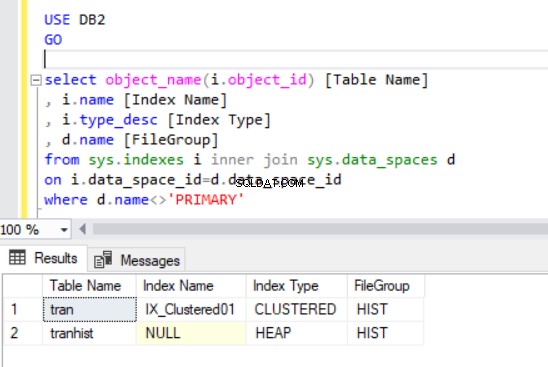
Ora abbiamo il tran tabella nel filegroup HIST.
Conclusione
Questo articolo ha dimostrato la relazione tra tabelle, indici, file e filegroup in termini di archiviazione dei dati di SQL Server. Abbiamo anche spiegato lo spostamento di una tabella da un filegroup all'altro ricreando l'indice cluster.
Questa abilità sarà utile quando è necessario migrare i dati in un nuovo spazio di archiviazione (dischi più veloci o dischi più lenti per l'archiviazione). In scenari più avanzati, puoi utilizzare i filegroup per gestire il ciclo di vita dei dati implementando le partizioni di tabelle.
Riferimenti
- File di database e filegroup
- Spegnere le partizioni di una tabella:una procedura dettagliata