Ora la nostra comunità di analisi dei big data ha iniziato a utilizzare Apache Spark in pieno svolgimento per l'elaborazione dei big data. L'elaborazione potrebbe essere per query ad hoc, query predefinite, elaborazione di grafici, apprendimento automatico e persino per lo streaming di dati.
Quindi la comprensione di Spark Job Submission è molto vitale per la comunità. Estenditi a chi è felice di condividere con te l'apprendimento dei passaggi coinvolti nell'invio di lavori Apache Spark.
Fondamentalmente ha due passaggi,

Invio di lavoro
Il processo Spark viene inviato automaticamente quando un'azione come count() viene eseguita su un RDD.
RunJob() internamente per essere chiamato su SparkContext e quindi richiamare lo scheduler che viene eseguito come parte del derivatore.
Lo scheduler è composto da 2 parti:DAG Scheduler e Task Scheduler.
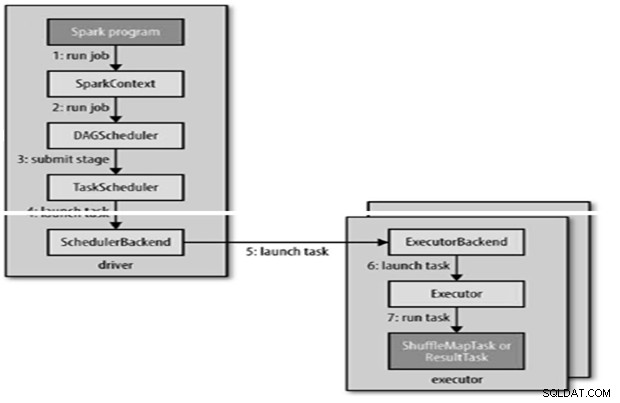
Costruzione DAG
Esistono due tipi di costruzioni DAG,

- Il lavoro Spark semplice è uno che non necessita di un shuffle e quindi ha una sola fase composta da attività di risultato, come il lavoro solo mappa in MapReduce
- Il lavoro Spark complesso prevede operazioni di raggruppamento e richiede una o più fasi di shuffle.
- Lo scheduler DAG di Spark trasforma il lavoro in due fasi.
- L'utilità di pianificazione DAG è responsabile della suddivisione di una fase in attività da inviare all'utilità di pianificazione delle attività.
- A ogni attività viene assegnata una preferenza di posizionamento dallo scheduler DAG per consentire allo scheduler delle attività di sfruttare la località dei dati.
- Le fasi figlio vengono inviate solo dopo che i genitori hanno completato con successo.
Pianificazione delle attività
- L'utilità di pianificazione invierà una serie di attività; utilizza il suo elenco di esecutori in esecuzione per l'applicazione e crea una mappatura delle attività per gli esecutori che tiene conto delle preferenze di posizionamento.
- L'utilità di pianificazione delle attività assegna agli esecutori che dispongono di core liberi, a ogni attività viene assegnato un core per impostazione predefinita. Può essere modificato dal parametro spark.task.cpus.
- Spark utilizza Akka, una piattaforma basata su attori per la creazione di applicazioni distribuite basate su eventi altamente scalabili.
- Spark non utilizza Hadoop RPC per le chiamate remote.
Esecuzione dell'attività
Un esecutore esegue un'attività come segue,
- Si assicura che il JAR e le dipendenze dei file per l'attività siano aggiornati.
- Deserializza il codice attività.
- Il codice dell'attività viene eseguito.
- L'attività restituisce i risultati al driver, che li assembla in un risultato finale da restituire all'utente.
Riferimento
- La guida definitiva di Hadoop
- Community open source di analisi e big data
Questo articolo è apparso originariamente qui. Ripubblicato con autorizzazione. Invia qui i tuoi reclami sul copyright.