Nella parte 2 di questa serie, è stata aggiunta la possibilità di salvare le modifiche apportate tramite l'API REST a un database utilizzando SQLAlchemy e si è appreso come serializzare tali dati per l'API REST utilizzando Marshmallow. La connessione dell'API REST a un database in modo che l'applicazione possa apportare modifiche ai dati esistenti e creare nuovi dati è eccezionale e rende l'applicazione molto più utile e robusta.
Questa è solo una parte della potenza offerta da un database, tuttavia. Una funzione ancora più potente è la R parte di RDBMS sistemi:relazioni . In un database, una relazione è la capacità di connettere due o più tabelle insieme in modo significativo. In questo articolo imparerai come implementare relazioni e trasformare la tua Person database in un'applicazione web di mini-blogging.
In questo articolo imparerai:
- Perché più di una tabella in un database è utile e importante
- Come le tabelle sono correlate tra loro
- Come SQLAlchemy può aiutarti a gestire le relazioni
- Come le relazioni ti aiutano a creare un'applicazione di mini-blogging
A chi è rivolto questo articolo
La parte 1 di questa serie ti ha guidato nella creazione di un'API REST e la parte 2 ti ha mostrato come connettere quell'API REST a un database.
Questo articolo espande ulteriormente la cintura degli strumenti di programmazione. Imparerai come creare strutture di dati gerarchiche rappresentate come relazioni uno-a-molti da SQLAlchemy. Inoltre, estenderai l'API REST che hai già creato per fornire il supporto CRUD (Crea, Leggi, Aggiorna ed Elimina) per gli elementi in questa struttura gerarchica.
L'applicazione web presentata nella parte 2 avrà i suoi file HTML e JavaScript modificati in modi importanti per creare un'applicazione di mini-blogging più completamente funzionale. Puoi rivedere la versione finale del codice dalla Parte 2 nel repository GitHub per quell'articolo.
Aspetta mentre inizi a creare relazioni e la tua applicazione di mini-blogging!
Ulteriori dipendenze
Non ci sono nuove dipendenze Python oltre a quanto richiesto per l'articolo della Parte 2. Tuttavia, utilizzerai due nuovi moduli JavaScript nell'applicazione web per rendere le cose più semplici e coerenti. I due moduli sono i seguenti:
- Manubri.js è un motore di template per JavaScript, proprio come Jinja2 per Flask.
- Moment.js è un modulo di analisi e formattazione della data e dell'ora che semplifica la visualizzazione dei timestamp UTC.
Non devi scaricare nessuno dei due, in quanto l'applicazione web li riceverà direttamente dalla CDN (Content Delivery Network) di Cloudflare, come stai già facendo per il modulo jQuery.
Dati delle persone estesi per i blog
Nella parte 2, le People i dati esistevano come dizionario in build_database.py codice Python. Questo è ciò che hai usato per popolare il database con alcuni dati iniziali. Stai per modificare le People struttura dati per fornire a ciascuna persona un elenco di note ad essa associate. Le nuove People la struttura dei dati sarà simile a questa:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Ogni persona in People il dizionario ora include una chiave chiamata notes , che è associato a un elenco contenente tuple di dati. Ogni tupla nelle notes list rappresenta una singola nota contenente il contenuto e un timestamp. I timestamp vengono inizializzati (anziché creati dinamicamente) per dimostrare l'ordine in un secondo momento nell'API REST.
Ogni singola persona è associata a più note e ogni singola nota è associata a una sola persona. Questa gerarchia di dati è nota come relazione uno-a-molti, in cui un singolo oggetto padre è correlato a molti oggetti figlio. Vedrai come viene gestita questa relazione uno-a-molti nel database con SQLAlchemy.
Approccio a forza bruta
Il database che hai creato ha archiviato i dati in una tabella e una tabella è una matrice bidimensionale di righe e colonne. Possono le People dizionario sopra essere rappresentato in un'unica tabella di righe e colonne? Può essere, nel modo seguente, nella tua person tabella del database. Sfortunatamente, l'inclusione di tutti i dati effettivi nell'esempio crea una barra di scorrimento per la tabella, come vedrai di seguito:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Cool, un'applicazione per mini-blogging! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Questo potrebbe essere utile | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Beh, abbastanza utile | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Farò osservazioni davvero profonde | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Forse saranno più ovvi di quanto pensassi | 2019-02-06 22:17:54 |
| 6 | Pasqua | Coniglietto | 2018-08-08 21:16:01 | Qualcuno ha visto le mie uova di Pasqua? | 2019-01-07 22:47:54 |
| 7 | Pasqua | Coniglietto | 2018-08-08 21:16:01 | Sono davvero in ritardo con la consegna di questi! | 2019-04-06 22:17:54 |
La tabella sopra funzionerebbe davvero. Tutti i dati sono rappresentati e una singola persona è associata a una raccolta di note diverse.
Vantaggi
Concettualmente, la struttura della tabella sopra ha il vantaggio di essere relativamente semplice da capire. Potresti anche sostenere che i dati potrebbero essere mantenuti in un file flat anziché in un database.
A causa della struttura della tabella bidimensionale, è possibile archiviare e utilizzare questi dati in un foglio di calcolo. I fogli di calcolo sono stati messi in servizio come archiviazione dei dati per un bel po'.
Svantaggi
Sebbene la struttura della tabella sopra funzioni, presenta alcuni svantaggi reali.
Per rappresentare la raccolta di note, tutti i dati per ogni persona vengono ripetuti per ogni singola nota, i dati della persona sono quindi ridondanti. Questo non è un grosso problema per i tuoi dati personali in quanto non ci sono molte colonne. Ma immagina se una persona avesse molte più colonne. Anche con unità disco di grandi dimensioni, questo può diventare un problema di archiviazione se hai a che fare con milioni di righe di dati.
Avere dati ridondanti come questo può portare a problemi di manutenzione con il passare del tempo. Ad esempio, cosa succederebbe se il coniglietto di Pasqua avesse deciso che un cambio di nome fosse una buona idea. Per fare ciò, ogni record contenente il nome del coniglietto di Pasqua dovrebbe essere aggiornato in modo da mantenere coerenti i dati. Questo tipo di lavoro sul database può portare a un'incoerenza dei dati, in particolare se il lavoro viene svolto da una persona che esegue manualmente una query SQL.
La denominazione delle colonne diventa imbarazzante. Nella tabella sopra, c'è un timestamp colonna utilizzata per tenere traccia del tempo di creazione e aggiornamento di una persona nella tabella. Vuoi anche avere funzionalità simili per la creazione e l'ora di aggiornamento di una nota, ma perché timestamp è già utilizzato, un nome inventato di note_timestamp viene utilizzato.
E se volessi aggiungere ulteriori relazioni uno-a-molti alla person tavolo? Ad esempio, per includere i bambini o i numeri di telefono di una persona. Ogni persona può avere più figli e più numeri di telefono. Questo potrebbe essere fatto in modo relativamente semplice con Python People dizionario sopra aggiungendo children e phone_numbers chiavi con nuove liste contenenti i dati.
Tuttavia, rappresentare quelle nuove relazioni uno-a-molti nella tua person la tabella del database sopra diventa significativamente più difficile. Ogni nuova relazione uno-a-molti aumenta notevolmente il numero di righe necessarie per rappresentarla per ogni singola voce nei dati figlio. Inoltre, i problemi associati alla ridondanza dei dati diventano più grandi e più difficili da gestire.
Infine, i dati che otterresti dalla struttura della tabella sopra non sarebbero molto Pythonici:sarebbe solo un grande elenco di elenchi. SQLAlchemy non sarebbe in grado di aiutarti molto perché la relazione non c'è.
Approccio al database relazionale
Sulla base di ciò che hai visto sopra, diventa chiaro che cercare di rappresentare anche un set di dati moderatamente complesso in una singola tabella diventa ingestibile abbastanza rapidamente. Detto questo, quale alternativa offre un database? Qui è dove la R parte di RDBMS entrano in gioco le banche dati. La rappresentazione delle relazioni rimuove gli svantaggi sopra delineati.
Invece di cercare di rappresentare i dati gerarchici in un'unica tabella, i dati vengono suddivisi in più tabelle, con un meccanismo per metterli in relazione tra loro. Le tabelle sono suddivise lungo linee di raccolta, quindi per le tue People dizionario sopra, questo significa che ci sarà una tabella che rappresenta le persone e un'altra che rappresenta le note. Questo riporta la tua person originale tabella, che assomiglia a questa:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pasqua | Coniglietto | 2018-08-08 21:16:01.886834 |
Per rappresentare le nuove informazioni sulla nota, creerai una nuova tabella chiamata notes . (Ricorda la nostra convenzione di denominazione delle tabelle singolari.) La tabella si presenta così:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Cool, un'applicazione per mini-blogging! | 2019-01-06 22:17:54 |
| 2 | 1 | Questo potrebbe essere utile | 2019-01-08 22:17:54 |
| 3 | 1 | Beh, abbastanza utile | 2019-03-06 22:17:54 |
| 4 | 2 | Farò osservazioni davvero profonde | 2019-01-07 22:17:54 |
| 5 | 2 | Forse saranno più ovvi di quanto pensassi | 2019-02-06 22:17:54 |
| 6 | 3 | Qualcuno ha visto le mie uova di Pasqua? | 2019-01-07 22:47:54 |
| 7 | 3 | Sono davvero in ritardo con la consegna di questi! | 2019-04-06 22:17:54 |
Nota che, come la person tabella, la notes la tabella ha un identificatore univoco chiamato note_id , che è la chiave primaria per la notes tavolo. Una cosa che non è ovvia è l'inclusione di person_id valore nella tabella. A cosa serve? Questo è ciò che crea la relazione con la person tavolo. Mentre note_id è la chiave primaria per la tabella, person_id è ciò che è noto come chiave esterna.
La chiave esterna fornisce ogni voce nella notes tabella la chiave primaria della person record a cui è associato. Utilizzando questo, SQLAlchemy può raccogliere tutte le note associate a ciascuna persona collegando il person.person_id chiave primaria al note.person_id chiave esterna, creando una relazione.
Vantaggi
Suddividendo il set di dati in due tabelle e introducendo il concetto di chiave esterna, hai reso i dati un po' più complessi su cui riflettere, hai risolto gli svantaggi di una rappresentazione di una singola tabella. SQLAlchemy ti aiuterà a codificare la maggiore complessità abbastanza facilmente.
I dati non sono più ridondanti nel database. C'è solo una voce persona per ogni persona che si desidera memorizzare nel database. Ciò risolve immediatamente i problemi di archiviazione e semplifica notevolmente i problemi di manutenzione.
Se il coniglietto pasquale volesse ancora cambiare nome, dovresti cambiare solo una riga nella person tabella e qualsiasi altra cosa relativa a quella riga (come la notes tabella) trarrebbe immediatamente vantaggio dalla modifica.
La denominazione delle colonne è più coerente e significativa. Poiché i dati di persona e nota esistono in tabelle separate, il timestamp di creazione e aggiornamento può essere denominato in modo coerente in entrambe le tabelle, poiché non vi è alcun conflitto per i nomi tra le tabelle.
Inoltre, non dovresti più creare permutazioni di ogni riga per nuove relazioni uno-a-molti che potresti voler rappresentare. Prendi i nostri children e phone_numbers esempio di prima. L'implementazione richiederebbe child e phone_number tavoli. Ogni tabella conterrebbe una chiave esterna di person_id ricollegandolo alla person tabella.
Usando SQLAlchemy, i dati che otterresti dalle tabelle precedenti sarebbero più immediatamente utili, poiché quello che otterresti è un oggetto per ogni riga di persona. Quell'oggetto ha attributi denominati equivalenti alle colonne della tabella. Uno di questi attributi è un elenco Python contenente gli oggetti nota correlati.
Svantaggi
Laddove l'approccio della forza bruta era più semplice da capire, il concetto di chiavi esterne e relazioni rende il pensiero sui dati un po' più astratto. Questa astrazione deve essere pensata per ogni relazione che stabilisci tra le tabelle.
Fare uso delle relazioni significa impegnarsi a utilizzare un sistema di database. Questo è un altro strumento per installare, apprendere e mantenere al di là dell'applicazione che utilizza effettivamente i dati.
Modelli SQLAlchemy
Per utilizzare le due tabelle precedenti e la relazione tra loro, dovrai creare modelli SQLAlchemy che siano a conoscenza di entrambe le tabelle e della relazione tra loro. Ecco la Person di SQLAlchemy modello della Parte 2, aggiornato per includere una relazione con una raccolta di notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Le righe da 1 a 8 della classe Python sopra sono esattamente come quelle che hai creato prima nella Parte 2. Le righe da 9 a 16 creano un nuovo attributo nella Person classe chiamata notes . Queste nuove notes attributi è definito nelle seguenti righe di codice:
-
Riga 9: Come gli altri attributi della classe, questa riga crea un nuovo attributo chiamato
notese lo imposta uguale a un'istanza di un oggetto chiamatodb.relationship. Questo oggetto crea la relazione che stai aggiungendo allaPersonclass e viene creato con tutti i parametri definiti nelle righe che seguono. -
Riga 10: Il parametro stringa
'Note'definisce la classe SQLAlchemy che laPersonla classe sarà collegata. LaNotela classe non è ancora definita, motivo per cui è una stringa qui. Questo è un riferimento diretto e aiuta a gestire i problemi che l'ordine delle definizioni potrebbe causare quando è necessario qualcosa che non è definito fino a più tardi nel codice. Il'Note'string consente allaPersonclasse per trovare laNoteclass in fase di esecuzione, che segue siaPersoneNotesono stati definiti. -
Riga 11: Il
backref='person'parametro è più complicato. Crea quello che è noto come riferimento a ritroso inNoteoggetti. Ogni istanza di unaNotel'oggetto conterrà un attributo chiamatoperson. Lapersonl'attributo fa riferimento all'oggetto padre che un particolareNotel'istanza è associata a. Avere un riferimento all'oggetto padre (personin questo caso) nel figlio può essere molto utile se il codice scorre sulle note e deve includere informazioni sul genitore. Questo accade sorprendentemente spesso nel codice di rendering del display. -
Riga 12: Il
cascade='all, delete, delete-orphan'parametro determina come trattare le istanze degli oggetti note quando vengono apportate modifiche allaPersonprincipale esempio. Ad esempio, quando unaPersonoggetto viene eliminato, SQLAlchemy creerà l'SQL necessario per eliminare laPersondalla banca dati. Inoltre, questo parametro gli dice di eliminare anche tutte leNoteistanze ad esso associate. Puoi leggere ulteriori informazioni su queste opzioni nella documentazione di SQLAlchemy. -
Riga 13: Il
single_parent=Trueparametro è richiesto sedelete-orphanfa parte della precedentecascadeparametro. Questo dice a SQLAlchemy di non consentireNoteorfane istanze (unaNotesenza un genitorePersonoggetto) esistere perché ogniNoteha un solo genitore. -
Riga 14: Il
order_by='desc(Note.timestamp)'Il parametro indica a SQLAlchemy come ordinare laNoteistanze associate a unaPerson. Quando unaPersonviene recuperato l'oggetto, per impostazione predefinita lenotesl'elenco degli attributi conterràNoteoggetti in un ordine sconosciuto. Ildesc(...)di SQLAlchemy la funzione ordina le note in ordine decrescente dal più recente al più vecchio. Se questa riga fosse inveceorder_by='Note.timestamp', SQLAlchemy utilizzerà per impostazione predefinitaasc(...)funzione e ordina le note in ordine crescente, dalla meno recente alla più recente.
Ora che la tua Person il modello ha le nuove notes attributo, e questo rappresenta la relazione uno-a-molti con Note oggetti, dovrai definire un modello SQLAlchemy per una Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
La Note class definisce gli attributi che compongono una nota come visto nel nostro esempio notes tabella del database dall'alto. Gli attributi sono definiti qui:
-
Riga 1 crea la
Noteclass, ereditando dadb.Model, esattamente come hai fatto prima durante la creazione dellaPersonclasse. -
Riga 2 dice alla classe quale tabella del database usare per memorizzare
Noteoggetti. -
Riga 3 crea il
note_idattributo, definendolo come un valore intero e come chiave primaria per laNoteoggetto. -
Riga 4 crea il
person_idattributo, e la definisce come chiave esterna, mettendo in relazione laNoteclasse allaPersonclasse utilizzando ilperson.person_idchiave primaria. Questo e ilPerson.notesattributo, sono come SQLAlchemy sa cosa fare quando interagisce conPersoneNoteoggetti. -
Riga 5 crea il
contentattributo, che contiene il testo effettivo della nota. Ilnullable=Falseparametro indica che è possibile creare nuove note senza contenuto. -
Riga 6 crea il
timestampattributo, ed esattamente come laPersonclasse, questo contiene il tempo di creazione o aggiornamento per qualsiasi particolareNoteesempio.
Inizializza il database
Ora che hai aggiornato la Person e creato la Note modelli, li utilizzerai per ricostruire il database di test people.db . Lo farai aggiornando il build_database.py codice dalla parte 2. Ecco come apparirà il codice:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Il codice sopra proveniva dalla Parte 2, con alcune modifiche per creare la relazione uno-a-molti tra Person e Note . Ecco le righe aggiornate o nuove aggiunte al codice:
-
Riga 4 è stato aggiornato per importare la
Noteclasse definita in precedenza. -
Righe da 7 a 39 contengono le
PEOPLEaggiornate dizionario contenente i nostri dati personali, insieme all'elenco delle note associate a ciascuna persona. Questi dati verranno inseriti nel database. -
Righe da 49 a 61 scorrere su
PEOPLEdizionario, ottenendo ognipersona sua volta e utilizzandolo per creare unaPersonoggetto. -
Riga 53 scorre su
person.noteslist, ottenendo ogninotesa sua volta. -
Riga 54 decomprime il
contentetimestampda ogninotestupla. -
Riga da 55 a 60 crea una
Noteoggetto e lo aggiunge alla raccolta di note personali utilizzandop.notes.append(). -
Riga 61 aggiunge la
Personoggettopalla sessione del database. -
Riga 63 impegna tutte le attività della sessione nel database. È a questo punto che tutti i dati vengono scritti nella
personenotestabelle inpeople.dbfile di database.
Puoi vederlo lavorando con le notes raccolta nella Person istanza dell'oggetto p è proprio come lavorare con qualsiasi altro elenco in Python. SQLAlchemy si occupa delle informazioni sulla relazione uno-a-molti sottostanti quando db.session.commit() viene effettuata la chiamata.
Ad esempio, proprio come una Person l'istanza ha il suo campo chiave primaria person_id inizializzato da SQLAlchemy quando viene eseguito il commit nel database, istanze di Note avranno i loro campi chiave primaria inizializzati. Inoltre, la Note chiave esterna person_id verrà inizializzato anche con il valore della chiave primaria della Person istanza a cui è associato.
Ecco un esempio di una Person oggetto prima di db.session.commit() in una specie di pseudocodice:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Ecco l'esempio Person oggetto dopo db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
L'importante differenza tra i due è che la chiave primaria della Person e Note oggetti è stato inizializzato. Il motore di database si è occupato di questo poiché gli oggetti sono stati creati a causa della funzione di incremento automatico delle chiavi primarie discussa nella Parte 2.
Inoltre, il person_id chiave esterna in tutte le Note istanze è stato inizializzato per fare riferimento al suo genitore. Ciò accade a causa dell'ordine in cui la Person e Note gli oggetti vengono creati nel database.
SQLAlchemy è a conoscenza della relazione tra Person e Note oggetti. Quando una Person l'oggetto è vincolato alla person tabella del database, SQLAlchemy ottiene il person_id valore della chiave primaria. Tale valore viene utilizzato per inizializzare il valore della chiave esterna di person_id in una Note oggetto prima che venga eseguito il commit nel database.
SQLAlchemy si occupa di questo lavoro di pulizia del database a causa delle informazioni che hai passato quando Person.notes l'attributo è stato inizializzato con db.relationship(...) oggetto.
Inoltre, il Person.timestamp l'attributo è stato inizializzato con il timestamp corrente.
Esecuzione di build_database.py programma dalla riga di comando (nell'ambiente virtuale ricreerà il database con le nuove aggiunte, preparandolo per l'uso con l'applicazione web. Questa riga di comando ricostruirà il database:
$ python build_database.py
Il build_database.py programma di utilità non genera alcun messaggio se viene eseguito correttamente. Se genera un'eccezione, sullo schermo verrà visualizzato un errore.
Aggiorna API REST
Hai aggiornato i modelli SQLAlchemy e li hai usati per aggiornare people.db Banca dati. Ora è il momento di aggiornare l'API REST per fornire l'accesso alle nuove informazioni sulle note. Ecco l'API REST che hai creato nella parte 2:
| Azione | Verbo HTTP | Percorso URL | Descrizione |
|---|---|---|---|
| Crea | POST | /api/people | URL per creare una nuova persona |
| Leggi | GET | /api/people | URL per leggere una raccolta di persone |
| Leggi | GET | /api/people/{person_id} | URL per leggere una singola persona tramite person_id |
| Aggiorna | PUT | /api/people/{person_id} | URL per aggiornare una persona esistente tramite person_id |
| Elimina | DELETE | /api/people/{person_id} | URL per eliminare una persona esistente tramite person_id |
L'API REST sopra fornisce percorsi URL HTTP a raccolte di cose e alle cose stesse. Puoi ottenere un elenco di persone o interagire con una singola persona da quell'elenco di persone. Questo stile di percorso perfeziona ciò che viene restituito in modo da sinistra a destra, diventando più granulare man mano che procedi.
Continuerai questo schema da sinistra a destra per diventare più granulare e accedere alle raccolte di note. Ecco l'API REST estesa che creerai per fornire note all'applicazione web del mini-blog:
| Azione | Verbo HTTP | Percorso URL | Descrizione |
|---|---|---|---|
| Crea | POST | /api/people/{person_id}/notes | URL per creare una nuova nota |
| Leggi | GET | /api/people/{person_id}/notes/{note_id} | URL per leggere la singola nota di una singola persona |
| Aggiorna | PUT | api/people/{person_id}/notes/{note_id} | URL per aggiornare la singola nota di una singola persona |
| Elimina | DELETE | api/people/{person_id}/notes/{note_id} | URL per eliminare la singola nota di una singola persona |
| Leggi | GET | /api/notes | URL per ottenere tutte le note per tutte le persone ordinate per note.timestamp |
Ci sono due varianti nelle notes parte dell'API REST rispetto alla convenzione utilizzata in people sezione:
-
Non è stato definito alcun URL per ottenere tutte le
notesassociato a una persona, solo un URL per ottenere una singola nota. Ciò avrebbe reso l'API REST completa in un certo senso, ma l'applicazione Web che creerai in seguito non ha bisogno di questa funzionalità. Pertanto, è stato omesso. -
C'è l'inclusione dell'ultimo URL
/api/notes. Questo è un metodo pratico creato per l'applicazione web. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml file.
Nota:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes relationship. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes elenco. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attributo. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Nota:
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attributo. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no notes rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and notes , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related notes row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or operation. It returns person data even if there is no associated notes data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
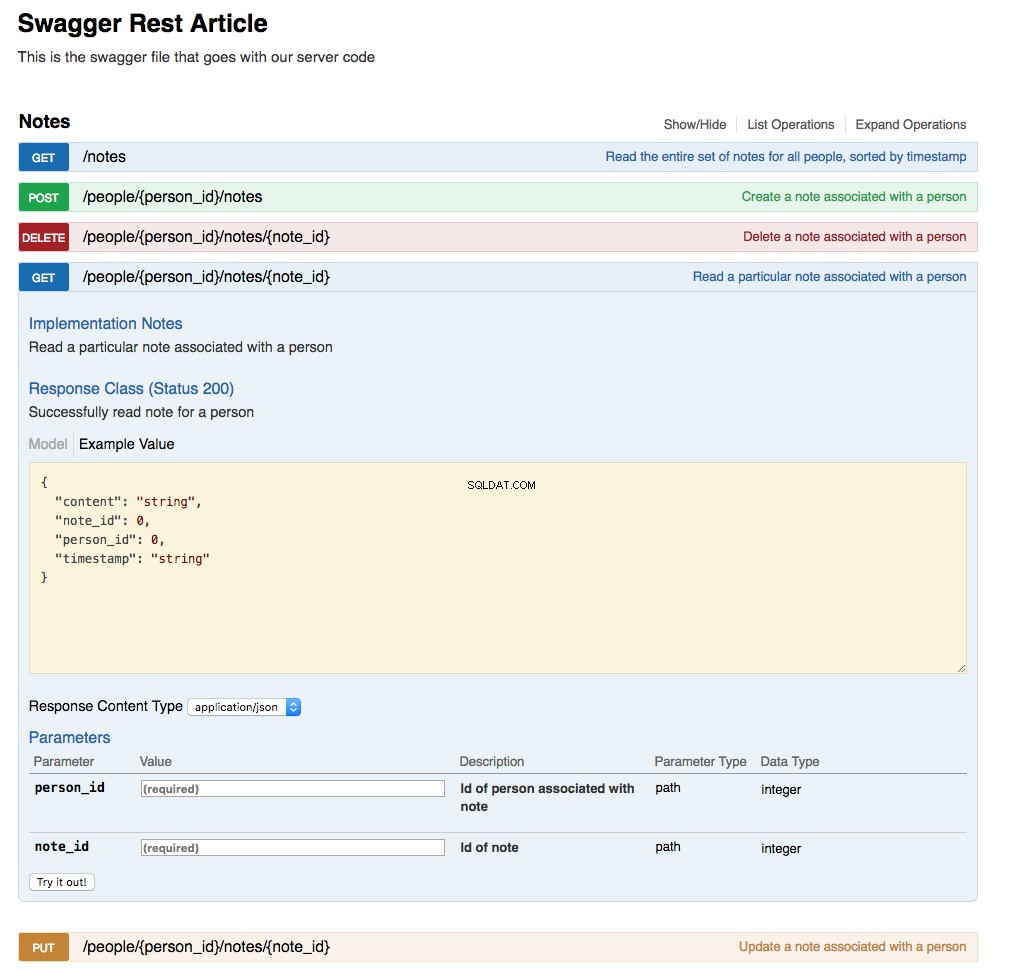
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
Below is a screenshot of the home page showing the initialized database contents:
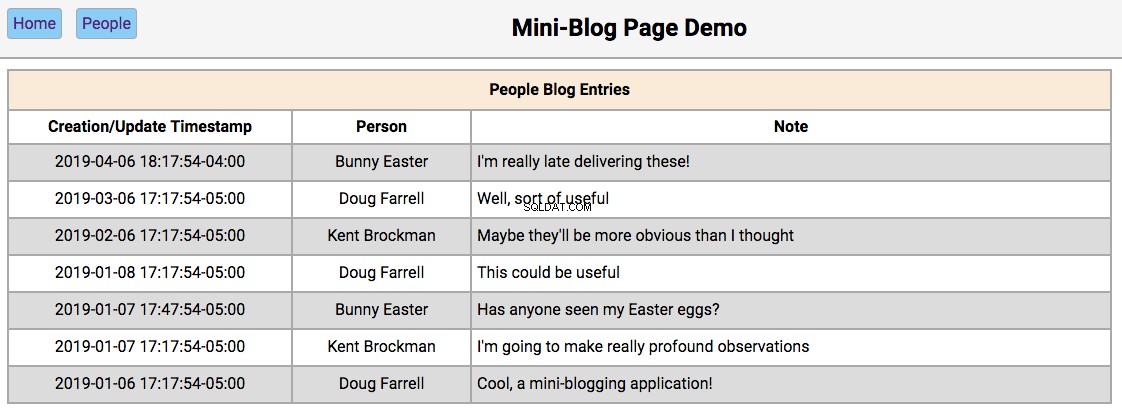
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
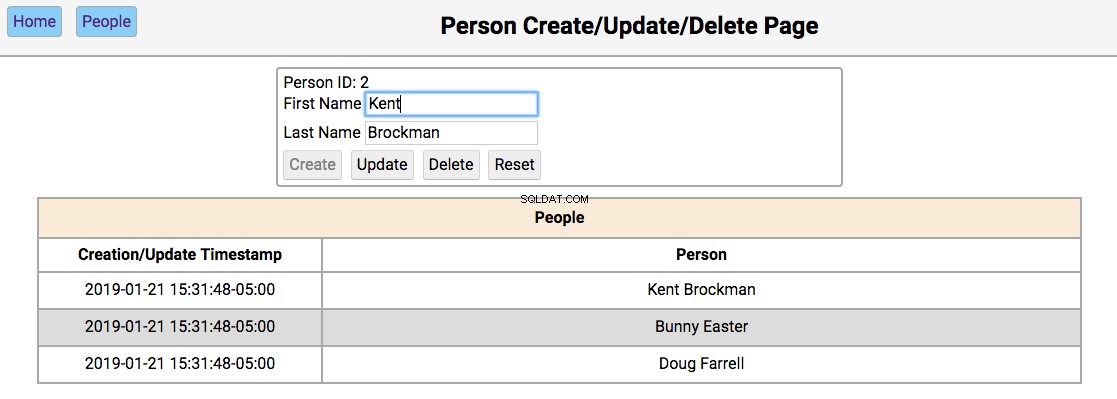
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete buttons.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
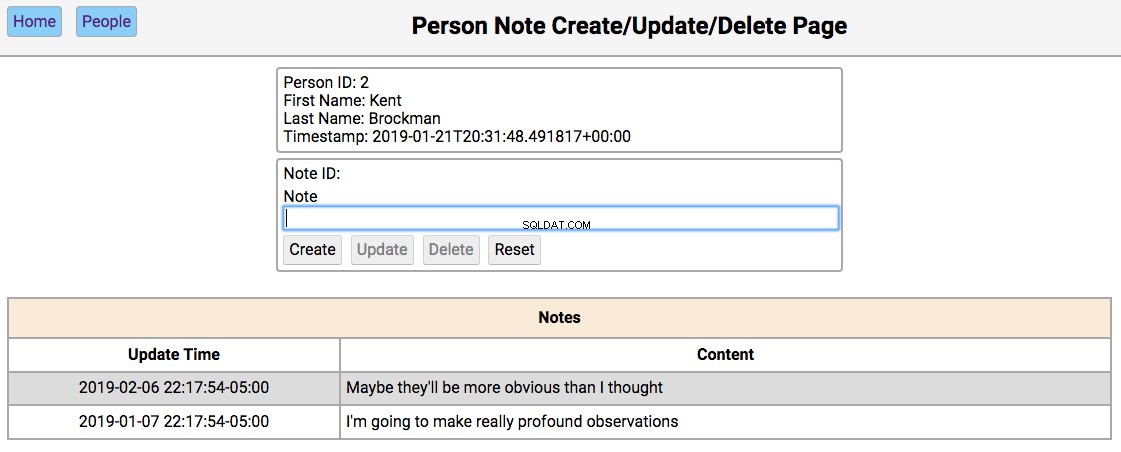
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete buttons.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Conclusione
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »


