Ti sei mai imbattuto in una situazione in cui devi gestire lo stato di un'entità che cambia nel tempo? Ci sono molti esempi là fuori. Cominciamo con uno facile:unire i record dei clienti.
Supponiamo di unire elenchi di clienti provenienti da due fonti diverse. È possibile che si verifichi uno dei seguenti stati:Identificati duplicati – il sistema ha rilevato due entità potenzialmente duplicate; Duplicati confermati – un utente convalida che le due entità siano effettivamente duplicate; o Unico confermato – l'utente decide che le due entità sono uniche. In una qualsiasi di queste situazioni, l'utente ha solo una decisione sì-no da prendere.
Ma che dire di situazioni più complesse? C'è un modo per definire il flusso di lavoro effettivo tra gli stati? Continua a leggere...
Come le cose possono facilmente andare storte
Molte organizzazioni devono gestire le domande di lavoro. In un modello semplice, potresti avere una tabella chiamata JOB_APPLICATION e potresti tenere traccia dello stato dell'applicazione utilizzando una tabella di dati di riferimento contenente valori come questi:
| Stato della domanda |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Questi valori possono essere selezionati in qualsiasi ordine in qualsiasi momento. Si affida agli utenti finali per garantire che venga effettuata una selezione logica e corretta in ogni fase. Nulla vieta una sequenza illogica di stati.
Ad esempio, diciamo che una domanda è stata respinta. Lo stato attuale sarebbe ovviamente APPLICATION_REJECTED . Non c'è nulla che si possa fare a livello di applicazione per impedire a un utente inesperto di selezionare successivamente INVITED_TO_INTERVIEW o qualche altro stato illogico.
Ciò che serve è qualcosa che guidi l'utente nella selezione dello stato logico successivo, qualcosa che definisca un flusso di lavoro logico .
E se hai requisiti diversi per diversi tipi di domande di lavoro? Ad esempio, alcuni lavori potrebbero richiedere al candidato di sostenere un test attitudinale. Certo, puoi aggiungere più valori all'elenco per coprirli, ma non c'è nulla nel design attuale che impedisca all'utente finale di effettuare una selezione errata per il tipo di applicazione in questione. La realtà è che esistono diversi flussi di lavoro per contesti diversi .
Un altro punto su cui riflettere:le opzioni elencate sono davvero tutti gli stati ? Oppure alcuni sono effettivamente risultati ? Ad esempio, l'offerta di lavoro può essere accettata o rifiutata dal richiedente. Pertanto, JOB_OFFER_MADE ha davvero due risultati:JOB_OFFER_ACCEPTED e JOB_OFFER_DECLINED .
Un altro risultato potrebbe essere il ritiro di un'offerta di lavoro. Potresti voler registrare il motivo per cui è stato ritirato utilizzando un qualificatore. Se si aggiungono solo questi motivi all'elenco sopra, nulla guida l'utente finale nell'effettuare selezioni logiche.
Quindi, in realtà, più complessi diventano gli stati, i risultati e le qualificazioni, più è necessario definire il flusso di lavoro di un processo .
Organizzazione di processi, stati e risultati
È importante capire cosa sta succedendo con i tuoi dati prima di tentare di modellarli. All'inizio potresti essere incline a pensare che qui ci sia una rigida gerarchia di tipi:
Quando osserviamo più da vicino l'esempio sopra, vediamo che il INVITED_TO_INTERVIEW e il JOB_OFFER_MADE gli stati condividono gli stessi possibili risultati, vale a dire ACCEPTED e DECLINED . Questo ci dice che esiste una relazione molti-a-molti tra stati e risultati. Questo è spesso vero per altri stati, risultati e qualificazioni.
A livello concettuale, quindi, questo è ciò che sta effettivamente accadendo con i nostri metadati:
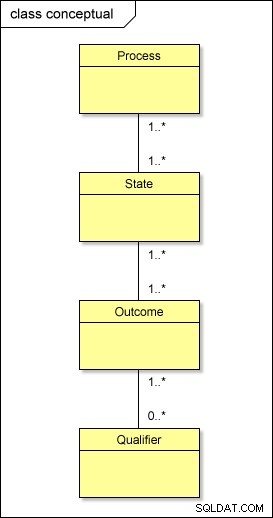
Se dovessi trasformare questo modello nel mondo fisico usando l'approccio standard, avresti tabelle chiamate PROCESS , STATE , OUTCOME e QUALIFIER; dovresti anche avere tabelle intermedie tra di loro – PROCESS_STATE , STATE_OUTCOME e OUTCOME_QUALIFIER – risolvere le relazioni molti-a-molti . Questo complica il design.
Sebbene la gerarchia logica dei livelli (processo → stato → risultato → qualificatore) debba essere mantenuta, esiste un modo più semplice per organizzare fisicamente i nostri metadati.
Il modello del flusso di lavoro
Il diagramma seguente definisce i componenti principali di un modello di database del flusso di lavoro:
Le tabelle gialle a sinistra contengono metadati del flusso di lavoro e le tabelle blu a destra contengono dati aziendali.
La prima cosa da sottolineare è che qualsiasi entità può essere gestita senza richiedere modifiche sostanziali a questo modello. Il YOUR_ENTITIY_TO_MANAGE la tabella è quella sotto la gestione del flusso di lavoro. Nei termini del nostro esempio, questo sarebbe il JOB_APPLICATION tavolo.
Successivamente, dobbiamo semplicemente aggiungere il wf_state_type_process_id colonna a qualsiasi tabella che vogliamo gestire. Questa colonna punta al processo del flusso di lavoro effettivo utilizzato per gestire l'entità. Questa non è strettamente una colonna di chiave esterna, ma ci consente di interrogare rapidamente WORKFLOW_STATE_TYPE per il processo corretto. La tabella che conterrà la cronologia dello stato è MANAGED_ENTITY_STATE . Anche in questo caso, sceglieresti qui il tuo nome di tabella specifico e lo modificheresti in base alle tue esigenze.
I metadati
I diversi livelli di flusso di lavoro sono definiti in WORKFLOW_LEVEL_TYPE . Questa tabella contiene quanto segue:
| Digita la chiave | Descrizione |
|---|---|
| PROCESSO | Processo di flusso di lavoro di alto livello. |
| STATO | Uno stato nel processo. |
| RISULTATO | Come finisce uno stato, il suo risultato. |
| QUALIFICATORE | Un qualificatore opzionale e più dettagliato per un risultato. |
WORKFLOW_STATE_TYPE e WORKFLOW_STATE_HIERARCHY formare una classica struttura della distinta base (BOM) . Questa struttura, che è molto descrittiva di una distinta base di produzione effettiva, è abbastanza comune nella modellazione dei dati. Può definire gerarchie o essere applicato a molte situazioni ricorsive. Ne faremo uso qui per definire la nostra gerarchia logica di processi, stati, risultati e qualificatori opzionali.
Prima di poter definire una gerarchia, dobbiamo definire i singoli componenti. Questi sono i nostri mattoni di base. Farò solo riferimento a questi con TYPE_KEY (che è unico) per brevità. Per il nostro esempio, abbiamo:
| Tipo di livello di flusso di lavoro | Chiave tipo.tipo stato flusso di lavoro |
|---|---|
| RISULTATO | PASSATO |
| RISULTATO | FALLITO |
| RISULTATO | ACCETTATO |
| RISULTATO | DECLINATA |
| RISULTATO | CANDIDATO_CANCELLED |
| RISULTATO | EMPLOYER_CANCELLED |
| RISULTATO | REGETTATO |
| RISULTATO | EMPLOYER_WITHDRAWN |
| RISULTATO | NO_SHOW |
| RISULTATO | ASSUNTO |
| RISULTATO | NON_ASSUNTO |
| STATO | APPLICATION_RECEIVED |
| STATO | APPLICATION_REVIEW |
| STATO | INVITED_TO_INTERVIEW |
| STATO | INTERVISTA |
| STATO | TEST_APTITUDE |
| STATO | CERCA_REFERENZE |
| STATO | MAKE_OFFER |
| STATO | APPLICATION_CLOSED |
| PROCESSO | STANDARD_JOB_APPLICATION |
| PROCESSO | APPLICAZIONE_LAVORO_TECNICA |
Ora possiamo iniziare a definire la nostra gerarchia. È qui che prendiamo i nostri mattoni e definiamo la nostra struttura. Per ogni stato, definiamo i possibili risultati. In effetti, è una regola di questo sistema di flusso di lavoro che ogni stato deve terminare con un risultato:
| Tipo di genitore – STATI | Tipo figlio – RISULTATI |
|---|---|
| APPLICATION_RECEIVED | ACCETTATO |
| APPLICAZIONE_RICEVUTA | REGETTATO |
| APPLICATION_REVIEW | PASSATO |
| APPLICATION_REVIEW | FALLITO |
| INVITED_TO_INTERVIEW | ACCETTATO |
| INVITED_TO_INTERVIEW | DECLINATA |
| INTERVISTA | PASSATO |
| INTERVISTA | FALLITO |
| INTERVISTA | CANDIDATO_CANCELLED |
| INTERVISTA | NO_SHOW |
| FARE_OFFERTA | ACCETTATO |
| FARE_OFFERTA | DECLINATA |
| CERCA_REFERENZE | PASSATO |
| CERCA_REFERENZE | FALLITO |
| APPLICATION_CLOSED | ASSUNTO |
| APPLICATION_CLOSED | NON_ASSUNTO |
| TEST_APTITUDE | PASSATO |
| TEST_APTITUDE | FALLITO |
I nostri processi sono semplicemente un insieme di stati che esistono ciascuno per un periodo di tempo. Nella tabella sottostante sono presentati in un ordine logico, ma questo non definisce l'effettivo ordine di elaborazione.
| Tipo padre – PROCESSI | Tipo figlio – STATI |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | INTERVISTA |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | CERCA_REFERENZE |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| APPLICAZIONE_LAVORO_TECNICA | APPLICATION_RECEIVED |
| APPLICAZIONE_LAVORO_TECNICA | APPLICATION_REVIEW |
| APPLICAZIONE_LAVORO_TECNICA | INVITED_TO_INTERVIEW |
| APPLICAZIONE_LAVORO_TECNICA | TEST_APTITUDE |
| APPLICAZIONE_LAVORO_TECNICA | INTERVISTA |
| APPLICAZIONE_LAVORO_TECNICA | MAKE_OFFER |
| APPLICAZIONE_LAVORO_TECNICA | CERCA_REFERENZE |
| APPLICAZIONE_LAVORO_TECNICA | APPLICATION_CLOSED |
C'è un punto importante da sottolineare riguardo a una gerarchia delle distinte base. Proprio come una distinta base fisica definisce assiemi e sottoassiemi fino ai componenti più piccoli, abbiamo una disposizione simile nella nostra gerarchia. Ciò significa che possiamo riutilizzare "assiemi" e "sottoassiemi".
A titolo di esempio:Sia il STANDARD_JOB_APPLICATION e TECHNICAL_JOB_APPLICATION processi avere il INTERVIEW stato . A sua volta, il INTERVIEW stato ha il PASSED , FAILED , CANDIDATE_CANCELLED e NO_SHOW risultati definito per esso.
Quando usi uno stato in un processo, ne ottieni automaticamente i risultati figlio perché è già un assembly. Ciò significa che esistono gli stessi risultati per entrambi i tipi di domanda di lavoro al INTERVIEW fase. Se desideri risultati diversi del colloquio per diversi tipi di domande di lavoro, devi definire, ad esempio, TECHNICAL_INTERVIEW e STANDARD_INTERVIEW afferma che ognuno ha i propri risultati specifici.
In questo esempio, l'unica differenza tra i due tipi di domande di lavoro è che una domanda di lavoro tecnica include un test attitudinale.
Prima di partire
La parte 1 di questo articolo in due parti ha introdotto il modello di database del flusso di lavoro. Ha mostrato come puoi incorporarlo per gestire il ciclo di vita di qualsiasi entità nel tuo database.
La parte 2 ti mostrerà come definire il flusso di lavoro effettivo utilizzando tabelle di configurazione aggiuntive. È qui che all'utente verranno presentati i passaggi successivi consentiti. Dimostreremo anche una tecnica per aggirare il riutilizzo rigoroso di "assiemi" e "sottoassiemi" nelle distinte base.