I database sono progettati in modi diversi. Il più delle volte possiamo usare "esempi scolastici":normalizza il database e tutto funzionerà bene. Ma ci sono situazioni che richiedono un altro approccio. Possiamo rimuovere i riferimenti per ottenere maggiore flessibilità. Ma cosa accadrebbe se dovessimo migliorare le prestazioni quando tutto è stato fatto secondo le regole? In tal caso, la denormalizzazione è una tecnica che dovremmo considerare. In questo articolo, discuteremo i vantaggi e gli svantaggi della denormalizzazione e quali situazioni potrebbero giustificarla.
Cos'è la denormalizzazione?
La denormalizzazione è una strategia utilizzata su un database precedentemente normalizzato per aumentare le prestazioni. L'idea alla base è quella di aggiungere dati ridondanti dove pensiamo che ci aiuterà di più. Possiamo utilizzare attributi extra in una tabella esistente, aggiungere nuove tabelle o persino creare istanze di tabelle esistenti. L'obiettivo abituale è ridurre il tempo di esecuzione delle query selezionate rendendo i dati più accessibili alle query o generando report riepilogati in tabelle separate. Questo processo può portare alcuni nuovi problemi e ne discuteremo in seguito.
Un database normalizzato è il punto di partenza per il processo di denormalizzazione. È importante differenziare dal database che non è stato normalizzato e dal database che è stato prima normalizzato e poi denormalizzato in seguito. Il secondo va bene; il primo è spesso il risultato di una cattiva progettazione del database o di una mancanza di conoscenza.
Esempio:un modello normalizzato per un CRM molto semplice
Il modello seguente servirà da esempio:
Diamo una rapida occhiata alle tabelle:
- Il
user_accountla tabella memorizza i dati sugli utenti che accedono alla nostra applicazione (semplificando il modello, i ruoli e i diritti degli utenti sono esclusi da essa). - Il
clientla tabella contiene alcuni dati di base sui nostri clienti. - Il
productla tabella elenca i prodotti offerti ai nostri clienti. - Il
tasktabella contiene tutte le attività che abbiamo creato. Puoi pensare a ogni attività come a un insieme di azioni correlate nei confronti dei clienti. Ogni attività ha le relative chiamate, riunioni ed elenchi di prodotti offerti e venduti. - La
callemeetingle tabelle memorizzano i dati su tutte le chiamate e le riunioni e li mettono in relazione con attività e utenti. - I dizionari
task_outcome,meeting_outcomeecall_outcomecontengono tutte le opzioni possibili per lo stato finale di un'attività, riunione o chiamata. - Il
product_offeredmemorizza un elenco di tutti i prodotti offerti ai clienti per determinate attività mentreproduct_soldcontiene un elenco di tutti i prodotti effettivamente acquistati dal cliente. - Il
supply_orderla tabella memorizza i dati su tutti gli ordini che abbiamo effettuato e ilproducts_on_orderla tabella elenca i prodotti e la loro quantità per ordini specifici. - Il
writeoffla tabella è un elenco di prodotti che sono stati cancellati a causa di incidenti o simili (es. specchi rotti).
Il database è semplificato ma è perfettamente normalizzato. Non troverai ridondanze e dovrebbe fare il lavoro. In ogni caso non dovremmo riscontrare problemi di prestazioni, purché lavoriamo con una quantità relativamente piccola di dati.
Quando e perché utilizzare la denormalizzazione
Come per quasi tutto, devi essere sicuro del motivo per cui vuoi applicare la denormalizzazione. Devi anche essere sicuro che il profitto derivante dal suo utilizzo superi qualsiasi danno. Ci sono alcune situazioni in cui dovresti assolutamente pensare alla denormalizzazione:
- Mantenimento della cronologia: I dati possono cambiare nel tempo e dobbiamo memorizzare i valori che erano validi quando è stato creato un record. Che tipo di modifiche intendiamo? Bene, il nome e il cognome di una persona possono cambiare; un cliente può anche cambiare la propria ragione sociale o qualsiasi altro dato. I dettagli dell'attività dovrebbero contenere valori che erano effettivi nel momento in cui è stata generata un'attività. Non saremmo in grado di ricreare correttamente i dati passati se ciò non accadesse. Potremmo risolvere questo problema aggiungendo una tabella contenente la cronologia di queste modifiche. In tal caso, una query di selezione che restituisce l'attività e un nome client valido diventerebbe più complicata. Forse un tavolo in più non è la soluzione migliore.
- Miglioramento delle prestazioni delle query: Alcune delle query possono utilizzare più tabelle per accedere ai dati di cui abbiamo spesso bisogno. Pensa a una situazione in cui dovremmo unire 10 tavoli per restituire il nome del cliente e i prodotti che gli sono stati venduti. Alcune tabelle lungo il percorso potrebbero contenere anche grandi quantità di dati. In tal caso, forse sarebbe saggio aggiungere un
client_idattribuire direttamente alproducts_soldtabella. - Velocità dei rapporti: Abbiamo bisogno di determinate statistiche molto frequentemente. La loro creazione da dati in tempo reale richiede molto tempo e può influire sulle prestazioni complessive del sistema. Diciamo che vogliamo monitorare le vendite dei clienti in determinati anni per alcuni o tutti i clienti. La generazione di tali rapporti da dati in tempo reale "scaverebbe" quasi l'intero database e lo rallenterebbe molto. E cosa succede se usiamo spesso quella statistica?
- Calcolo dei valori comunemente necessari in anticipo: Vogliamo avere alcuni valori già calcolati in modo da non doverli generare in tempo reale.
È importante sottolineare che non è necessario utilizzare la denormalizzazione se non ci sono problemi di prestazioni nell'applicazione. Ma se noti che il sistema sta rallentando – o se sei consapevole che ciò potrebbe accadere – allora dovresti pensare ad applicare questa tecnica. Prima di procedere, tuttavia, considera altre opzioni, come l'ottimizzazione delle query e l'indicizzazione corretta. Puoi anche utilizzare la denormalizzazione se sei già in produzione ma è meglio risolvere i problemi in fase di sviluppo.
Quali sono gli svantaggi della denormalizzazione?
Ovviamente, il più grande vantaggio del processo di denormalizzazione è l'aumento delle prestazioni. Ma dobbiamo pagare un prezzo per questo, e quel prezzo può consistere in:
- Spazio su disco: Questo è previsto, poiché avremo dati duplicati.
- Anomalie dei dati: Dobbiamo essere molto consapevoli del fatto che i dati ora possono essere modificati in più di un luogo. Dobbiamo adeguare di conseguenza ogni dato duplicato. Ciò vale anche per i valori calcolati e i report. Possiamo raggiungere questo obiettivo utilizzando trigger, transazioni e/o procedure per tutte le operazioni che devono essere completate insieme.
- Documentazione: Dobbiamo documentare adeguatamente ogni regola di denormalizzazione che abbiamo applicato. Se modifichiamo la progettazione del database in un secondo momento, dovremo esaminare tutte le nostre eccezioni e prenderle in considerazione ancora una volta. Forse non ne abbiamo più bisogno perché abbiamo risolto il problema. O forse dobbiamo aggiungere alle regole di denormalizzazione esistenti. (Ad esempio:abbiamo aggiunto un nuovo attributo alla tabella client e vogliamo memorizzarne il valore della cronologia insieme a tutto ciò che abbiamo già archiviato. Dovremo modificare le regole di denormalizzazione esistenti per ottenerlo).
- Rallentamento di altre operazioni: Possiamo aspettarci di rallentare le operazioni di inserimento, modifica ed eliminazione dei dati. Se queste operazioni si verificano relativamente di rado, questo potrebbe essere un vantaggio. Fondamentalmente, divideremmo una selezione lenta in un numero maggiore di query di inserimento/aggiornamento/eliminazione più lente. Mentre una query di selezione molto complessa tecnicamente potrebbe rallentare notevolmente l'intero sistema, il rallentamento di più operazioni "più piccole" non dovrebbe danneggiare l'usabilità della nostra applicazione.
- Più codifica: Le regole 2 e 3 richiederanno una codifica aggiuntiva, ma allo stesso tempo semplificheranno molto alcune query selezionate. Se stiamo denormalizzando un database esistente, dovremo modificare queste query selezionate per ottenere i vantaggi del nostro lavoro. Dovremo anche aggiornare i valori negli attributi appena aggiunti per i record esistenti. Anche questo richiederà un po' più di codifica.
Il modello di esempio, denormalizzato
Nel modello seguente, ho applicato alcune delle suddette regole di denormalizzazione. I tavolini rosa sono stati modificati, mentre il tavolo azzurro è completamente nuovo.
Quali modifiche vengono applicate e perché?

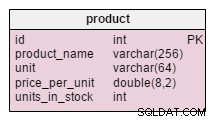
L'unica modifica nel product la tabella è l'aggiunta di units_in_stock attributo. In un modello normalizzato potremmo calcolare questi dati come unità ordinate – unità vendute – (unità offerte) – unità cancellate . Ripetiamo il calcolo ogni volta che un cliente richiede quel prodotto, il che richiederebbe molto tempo. Invece, calcoleremo il valore in anticipo; quando un cliente ce lo chiede, lo avremo pronto. Naturalmente, questo semplifica molto la query di selezione. D'altra parte, il units_in_stock l'attributo deve essere modificato dopo ogni inserimento, aggiornamento o eliminazione nel products_on_order , writeoff , product_offered e product_sold tabelle.
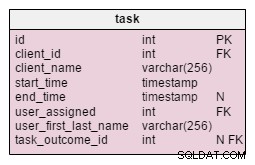
Nella task tabella, troviamo due nuovi attributi:client_name e user_first_last_name . Entrambi memorizzano i valori quando è stata creata l'attività. Il motivo è che entrambi questi valori possono cambiare nel tempo. Conserveremo anche una chiave esterna che li mette in relazione con il client e l'ID utente originali. Ci sono più valori che vorremmo memorizzare, come l'indirizzo del cliente, la partita IVA, ecc.




Il product_offered table ha due nuovi attributi, price_per_unit e price . Il price_per_unit viene memorizzato perché dobbiamo memorizzare il prezzo effettivo quando il prodotto è stato offerto . Il modello normalizzato mostrerebbe solo il suo stato attuale, quindi quando il prezzo del prodotto cambia anche i nostri prezzi "storia" cambierebbero. La nostra modifica non solo rende il database più veloce:lo fa anche funzionare meglio. Il price attributo è il valore calcolato units_sold * price_per_unit . L'ho aggiunto qui per evitare di fare quel calcolo ogni volta che vogliamo dare un'occhiata a un elenco di prodotti offerti. È un piccolo costo, ma migliora le prestazioni.
Le modifiche apportate al product_sold tavolo sono molto simili. La struttura della tabella è la stessa, ma memorizza un elenco di articoli venduti.
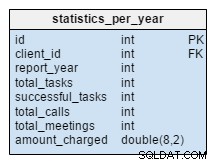
Il statistics_per_year il tavolo è completamente nuovo per il nostro modello. Dovremmo considerarla come una tabella denormalizzata perché tutti i suoi dati possono essere calcolati dalle altre tabelle. L'idea alla base di questa tabella è quella di memorizzare il numero di attività, attività riuscite, riunioni e chiamate relative a un determinato cliente. Gestisce anche la somma totale addebitata per ogni anno. Dopo aver inserito, aggiornato o eliminato qualcosa nell'task , meeting , call e product_sold tabelle, dovremmo ricalcolare i dati di questa tabella per quel cliente e l'anno corrispondente. Possiamo aspettarci che per lo più avremo modifiche solo per l'anno in corso. Non dovrebbe essere necessario modificare i rapporti per gli anni precedenti.
I valori in questa tabella sono calcolati in anticipo, quindi spenderemo meno tempo e risorse nel momento in cui avremo bisogno del risultato del calcolo. Pensa spesso ai valori di cui avrai bisogno. Forse non ti serviranno regolarmente tutti e potresti rischiare di calcolarne alcuni dal vivo.
La denormalizzazione è un concetto molto interessante e potente. Sebbene non sia il primo che dovresti avere in mente per migliorare le prestazioni, in alcune situazioni può essere la migliore o addirittura l'unica soluzione.
Prima di scegliere di utilizzare la denormalizzazione, assicurati di volerla. Fai qualche analisi e tieni traccia delle prestazioni. Probabilmente deciderai di procedere con la denormalizzazione dopo che sei già andato in diretta. Non aver paura di usarlo, ma tieni traccia delle modifiche e non dovresti riscontrare alcun problema (ad esempio le temute anomalie dei dati).