Uno dei modi migliori per conoscere i bug in SQL Server è leggere le note sulla versione per gli aggiornamenti cumulativi e i Service Pack quando escono. Tuttavia, occasionalmente questo è anche un ottimo modo per conoscere i miglioramenti anche a SQL Server.
Aggiornamento cumulativo 6 per SQL Server 2014 Service Pack 1 ha introdotto un nuovo flag di traccia, 7471, che modifica il comportamento di blocco delle attività UPDATE STATISTICS in SQL Server (vedere KB #3156157). In questo post esamineremo la differenza nel comportamento di blocco e dove potrebbe essere utile questo flag di traccia.
Per impostare un ambiente demo appropriato per questo post, ho utilizzato il database AdventureWorks2014 e ho creato una tabella SalesOrderDetail in versione ingrandita basata sullo script disponibile sul mio blog. La tabella SalesOrderDetailEnlarged è stata ingrandita a 2 GB in modo che le operazioni UPDATE STATISTICS WITH FULLSCAN possano essere eseguite su diverse statistiche sulla tabella contemporaneamente. Ho quindi utilizzato sp_whoisactive per esaminare i blocchi tenuti da entrambe le sessioni.
Comportamento senza TF 7471
Il comportamento predefinito di SQL Server richiede un blocco esclusivo (X) sulla risorsa OBJECT.UPDSTATS per la tabella ogni volta che viene eseguito un comando UPDATE STATISTICS su una tabella. È possibile visualizzare ciò nell'output sp_whoisactive per due esecuzioni simultanee di UPDATE STATISTICS WITH FULLSCAN rispetto alla tabella Sales.SalesOrderDetailEnlarged, utilizzando nomi di indice diversi per l'aggiornamento delle statistiche. Ciò comporta il blocco della seconda esecuzione di UPDATE STATISTICS fino al completamento della prima esecuzione.
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="GRANT" request_count="1" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="WAIT" request_count="1" />
</Locks>
</Object> La granularità della risorsa di blocco su OBJECT.UPDSTATS impedisce aggiornamenti simultanei di più statistiche sulla stessa tabella. I miglioramenti hardware negli ultimi anni hanno davvero modificato i potenziali colli di bottiglia comuni alle implementazioni di SQL Server e, proprio come sono state apportate modifiche a DBCC CHECKDB per renderlo più veloce, modificando il comportamento di blocco di UPDATE STATISTICS per consentire aggiornamenti simultanei delle statistiche sul la stessa tabella può ridurre significativamente le finestre di manutenzione per i VLDB, soprattutto dove c'è una capacità sufficiente di CPU e sottosistema di I/O per consentire l'esecuzione di aggiornamenti simultanei senza influire sull'esperienza dell'utente finale.
Comportamento con TF 7471
Il comportamento di blocco con il flag di traccia 7471 ha consentito le modifiche dalla richiesta di un blocco esclusivo (X) sulla risorsa OBJECT.UPDSTATS alla richiesta di un blocco di aggiornamento (U) sulla risorsa METADATA.STATS per la statistica specifica in fase di aggiornamento, che consente esecuzioni simultanee di UPDATE STATISTICS sulla stessa tabella. L'output di sp_whoisactive per gli stessi comandi UPDATE STATISTICS WITH FULLCAN con il flag di traccia abilitato è mostrato di seguito:
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Objects>
<Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="IX_SalesOrderDetailEnlarged_ProductID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> Per i VLDB, che stanno diventando molto più comuni, questo può fare una grande differenza nel tempo necessario per eseguire gli aggiornamenti delle statistiche su un server.
Di recente ho scritto sul blog di una soluzione di manutenzione parallela per SQL Server che utilizza Service Broker e gli script di manutenzione di Ola Hallengren come un modo per ottimizzare le attività di manutenzione notturna e ridurre il tempo necessario per ricostruire gli indici e aggiornare le statistiche sui server che hanno molta CPU e capacità di I/O disponibile. Come parte di tale soluzione, ho forzato un ordine di accodamento delle attività a Service Broker per cercare di evitare esecuzioni simultanee sulla stessa tabella sia per la ricostruzione/riorganizzazione dell'indice che per le attività UPDATE STATISTICS. L'obiettivo era mantenere i lavoratori il più occupati possibile fino alla fine delle attività di manutenzione, dove le cose si sarebbero serializzate in esecuzione sulla base del blocco delle attività simultanee.
Ho apportato alcune modifiche all'elaborazione in quel post per testare gli effetti di questo flag di traccia solo con aggiornamenti simultanei delle statistiche e i risultati sono di seguito.
Test delle prestazioni dell'aggiornamento delle statistiche simultanee
Per testare le prestazioni del solo aggiornamento delle statistiche in parallelo utilizzando la configurazione di Service Broker, ho iniziato creando una statistica di colonna su ogni colonna del database AdventureWorks2014 utilizzando lo script seguente per generare i comandi DDL da eseguire.
USE [AdventureWorks2014]
GO
SELECT *, 'DROP STATISTICS ' + QUOTENAME(c.TABLE_SCHEMA) + '.'
+ QUOTENAME(c.TABLE_NAME) + '.' + QUOTENAME(c.TABLE_NAME
+ '_' + c.COLUMN_NAME) + ';
GO
CREATE STATISTICS ' +QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME)
+ ' ON ' + QUOTENAME(c.TABLE_SCHEMA) + '.' + QUOTENAME(c.TABLE_NAME)
+ ' (' +QUOTENAME(c.COLUMN_NAME) + ');' + '
GO'
FROM INFORMATION_SCHEMA.COLUMNS AS c
INNER JOIN INFORMATION_SCHEMA.TABLES AS t
ON c.TABLE_CATALOG = t.TABLE_CATALOG AND
c.TABLE_SCHEMA = t.TABLE_SCHEMA AND
c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_TYPE = 'BASE TABLE'
AND c.DATA_TYPE <> N'xml'; Questo non è qualcosa che in genere vorresti fare, ma mi fornisce molte statistiche per test paralleli dell'impatto del flag di traccia sull'aggiornamento simultaneo delle statistiche. Invece di randomizzare l'ordine in cui accodano le attività a Service Broker, accodano semplicemente le attività così come esistono nella tabella CommandLog in base all'ID della tabella, semplicemente incrementando l'ID di uno finché tutti i comandi non sono stati accodati per l'elaborazione.
USE [master]; -- Clear the Command Log TRUNCATE TABLE [master].[dbo].[CommandLog]; DECLARE @MaxID INT; SELECT @MaxID = MAX(ID) FROM master.dbo.CommandLog; SELECT @MaxID = ISNULL(@MaxID, 1) ---- Load new tasks into the Command Log EXEC master.dbo.IndexOptimize @Databases = N'AdventureWorks2014', @FragmentationLow = NULL, @FragmentationMedium = NULL, @FragmentationHigh = NULL, @UpdateStatistics = 'ALL', @StatisticsSample = 100, @LogToTable = 'Y', @Execute = 'N'; DECLARE @NewMaxID INT SELECT @NewMaxID = MAX(ID) FROM master.dbo.CommandLog; USE msdb; DECLARE @CurrentID INT = @MaxID WHILE (@CurrentID <= @NewMaxID) BEGIN -- Begin a conversation and send a request message DECLARE @conversation_handle UNIQUEIDENTIFIER; DECLARE @message_body XML; BEGIN TRANSACTION; BEGIN DIALOG @conversation_handle FROM SERVICE [OlaHallengrenMaintenanceTaskService] TO SERVICE N'OlaHallengrenMaintenanceTaskService' ON CONTRACT [OlaHallengrenMaintenanceTaskContract] WITH ENCRYPTION = OFF; SELECT @message_body = N'<CommandLogID>'+CAST(@CurrentID AS NVARCHAR)+N'</CommandLogID>'; SEND ON CONVERSATION @conversation_handle MESSAGE TYPE [OlaHallengrenMaintenanceTaskMessage] (@message_body); COMMIT TRANSACTION; SET @CurrentID = @CurrentID + 1; END WHILE EXISTS (SELECT 1 FROM OlaHallengrenMaintenanceTaskQueue WITH(NOLOCK)) BEGIN WAITFOR DELAY '00:00:01.000' END WAITFOR DELAY '00:00:06.000' SELECT DATEDIFF(ms, MIN(StartTime), MAX(EndTime)) FROM master.dbo.CommandLog; GO 10
Quindi ho aspettato il completamento di tutte le attività, ho misurato il delta nell'ora di inizio e nell'ora di fine delle esecuzioni delle attività e ho eseguito la media di dieci test per determinare i miglioramenti solo per l'aggiornamento delle statistiche contemporaneamente utilizzando il campionamento predefinito e gli aggiornamenti della scansione completa.
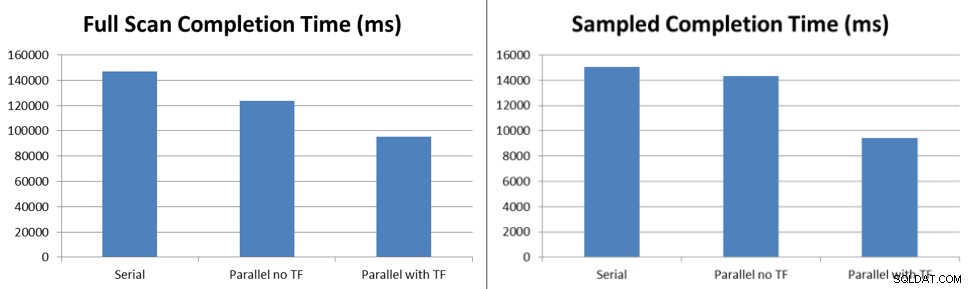
I risultati del test mostrano che anche con il blocco che si verifica con il comportamento predefinito senza il flag di traccia, gli aggiornamenti campionati delle statistiche vengono eseguiti il 6% più velocemente e gli aggiornamenti della scansione completa vengono eseguiti il 16% più velocemente con cinque thread che elaborano le attività accodate a Service Broker. Con il flag di traccia 7471 abilitato, gli stessi aggiornamenti campionati delle statistiche vengono eseguiti il 38% più velocemente e gli aggiornamenti della scansione completa vengono eseguiti il 45% più velocemente con cinque thread che elaborano le attività accodate a Service Broker.
Potenziali sfide con TF 7471
Per quanto convincenti siano i risultati del test, nulla in questo mondo è gratuito e durante i miei test iniziali ho riscontrato alcuni problemi con le dimensioni della VM che stavo usando sul mio laptop che hanno creato problemi di carico di lavoro.
Inizialmente stavo testando la manutenzione parallela utilizzando una VM 4vCPU con 4 GB di RAM che ho configurato appositamente per questo scopo. Quando ho iniziato ad aumentare il numero di MAX_QUEUE_READERS per la procedura di attivazione in Service Broker, ho iniziato a riscontrare problemi con le attese RESOURCE_SEMAPHORE quando veniva abilitato il flag di traccia, consentendo aggiornamenti paralleli delle statistiche sulle tabelle ingrandite nel mio database AdventureWorks2014 a causa dei requisiti di concessione della memoria per ciascuno dei comandi UPDATE STATISTICS in esecuzione. Ciò è stato alleviato modificando la configurazione della macchina virtuale in 16 GB di RAM, ma questo è qualcosa da monitorare e tenere d'occhio quando si eseguono attività parallele su tabelle più grandi, per includere la manutenzione dell'indice, poiché la carenza di concessione di memoria influirà anche sulle richieste degli utenti finali che potrebbero tentare di eseguire e ha bisogno anche di una concessione di memoria più grande.
Il team del prodotto ha anche pubblicato un blog su questo flag di traccia e nel suo post avverte che potrebbero verificarsi scenari di deadlock durante l'aggiornamento simultaneo delle statistiche mentre vengono create anche le statistiche. Questo non è qualcosa in cui mi sono imbattuto ancora durante i miei test, ma è sicuramente qualcosa di cui essere consapevole (anche Kendra Little lo avverte). Di conseguenza, la loro raccomandazione è che questo flag di traccia sia abilitato solo durante l'esecuzione di attività di manutenzione parallela e quindi dovrebbe essere disabilitato per i normali periodi di carico di lavoro.
Divertiti!