In un suggerimento recente, ho descritto uno scenario in cui un'istanza di SQL Server 2016 sembrava alle prese con i tempi di checkpoint. Il registro degli errori è stato popolato con un numero allarmante di voci FlushCache come questa:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Sono rimasto un po' perplesso da questo problema, dal momento che il sistema non era certamente debole:molti core, 3 TB di memoria e spazio di archiviazione XtremIO. E nessuno di questi messaggi FlushCache è mai stato associato agli avvisi di I/O di 15 secondi nel registro degli errori. Tuttavia, se si impilano un gruppo di database ad alta transazione, l'elaborazione del checkpoint può diventare piuttosto lenta. Non tanto per l'I/O diretto, ma per una maggiore riconciliazione che deve essere eseguita con un numero enorme di pagine sporche (non solo da commesse transazioni) sparsi su una tale quantità di memoria e potenzialmente in attesa del lazywriter (poiché ce n'è solo uno per l'intera istanza).
Ho fatto una rapida lettura "rinfrescante" di alcuni post molto preziosi:
- Come funzionano i checkpoint e cosa viene registrato
- Punti di controllo del database (SQL Server)
- Cosa fa checkpoint per tempdb?
- Un mito di SQL Server DBA al giorno:(15/30) checkpoint scrive solo pagine da transazioni impegnate
- I messaggi FlushCache potrebbero non essere un vero e proprio stallo dell'IO
- Checkpoint indiretto e tempdb:lo scheduler buono, cattivo e non cedevole
- Modifica il tempo di ripristino target di un database
- Come funziona:quando viene aggiunto il messaggio FlushCache al log degli errori di SQL Server?
- Modifiche al comportamento del checkpoint di SQL Server 2016
- Intervallo di ripristino del target e checkpoint indiretto – Nuovo valore predefinito di 60 secondi in SQL Server 2016
- SQL 2016 – Funziona più velocemente:checkpoint indiretto predefinito
- SQL Server:grande RAM e checkpoint DB
Ho deciso rapidamente che volevo tenere traccia delle durate dei checkpoint per alcuni di questi database più problematici, prima e dopo aver modificato l'intervallo di ripristino target da 0 (il vecchio modo) a 60 secondi (il nuovo modo). A gennaio, ho preso in prestito una sessione di eventi estesi dall'amica e collega canadese Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Ho contrassegnato l'ora in cui ho modificato ciascun database, quindi ho analizzato i risultati dei dati degli eventi estesi utilizzando una query pubblicata nel suggerimento originale. I risultati hanno mostrato che dopo essere passati ai checkpoint indiretti, ogni database è passato da checkpoint con una media di 30 secondi a checkpoint con una media di meno di un decimo di secondo (e anche molti meno checkpoint nella maggior parte dei casi). C'è molto da scompattare da questo grafico, ma questi sono i dati grezzi che ho usato per presentare la mia argomentazione (clicca per ingrandire):
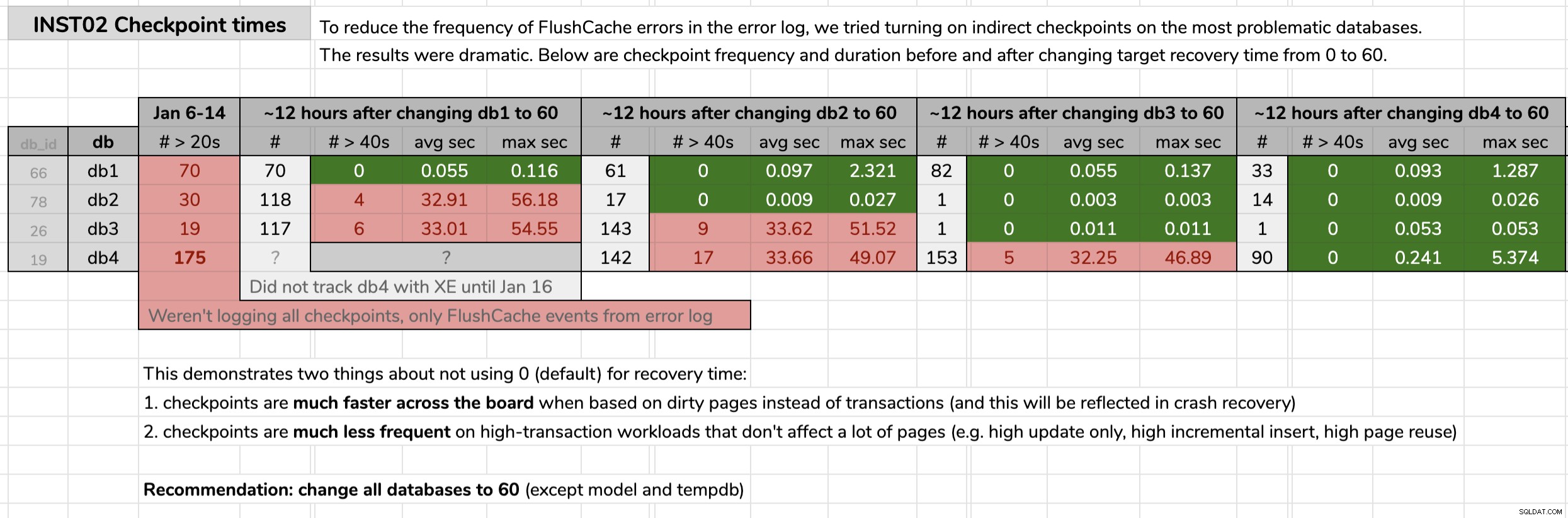 Le mie prove
Le mie prove
Una volta che ho dimostrato il mio caso su questi database problematici, ho ottenuto il via libera per implementarlo in tutti i nostri database utente nel nostro ambiente. In dev prima, e poi in produzione, ho eseguito quanto segue tramite una query CMS per ottenere un indicatore di quanti database stavamo parlando:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Alcune note sulla query:
database_id > 4
Non volevo toccaremasteraffatto e non volevo cambiaretempdbancora perché non siamo sull'ultima CU di SQL Server 2017 (vedi KB n. 4497928 per un motivo che i dettagli sono importanti). Quest'ultimo esclude ilmodel, anche, perché la modifica del modello influirebbe sutempdbal successivo failover/riavvio. Avrei potuto cambiaremsdb, e potrei tornare a farlo prima o poi, ma qui mi sono concentrato sui database degli utenti.
[state] / is_read_only / is_in_standby
Dobbiamo assicurarci che i database che stiamo cercando di modificare siano online e non di sola lettura (ne ho colpito uno che era attualmente impostato per la sola lettura e dovrò tornare su quello più tardi).
OUTER APPLY (...)
Vogliamo limitare le nostre azioni ai database che sono i principali in un AG o non in un AG (e dobbiamo anche tenere conto degli AG distribuiti, dove possiamo essere primari e locali ma non essere ancora scrivibili) . Se ti capita di eseguire il controllo su un secondario, non puoi risolvere il problema lì, ma dovresti comunque ricevere un avviso al riguardo. Grazie a Erik Darling per aver aiutato con questa logica e Taylor Martell per aver motivato i miglioramenti.
- Se hai istanze che eseguono versioni precedenti come SQL Server 2008 R2 (ne ho trovato uno!), dovrai modificarlo un po', poiché
target_recovery_time_in_secondsla colonna non esiste lì. Ho dovuto usare l'SQL dinamico per aggirare questo problema in un caso, ma potresti anche spostare o rimuovere temporaneamente dove quelle istanze cadono nella tua gerarchia CMS. Inoltre, non potresti essere pigro come me ed eseguire il codice in Powershell anziché in una finestra di query CMS, dove potresti facilmente filtrare i database in base a un numero qualsiasi di proprietà prima di incontrare problemi in fase di compilazione.
In produzione, c'erano 102 istanze (circa la metà) e 1.590 database totali che utilizzavano la vecchia impostazione. Tutto era su SQL Server 2017, quindi perché questa impostazione era così prevalente? Perché sono stati creati prima che i checkpoint indiretti diventassero l'impostazione predefinita in SQL Server 2016. Ecco un esempio dei risultati:
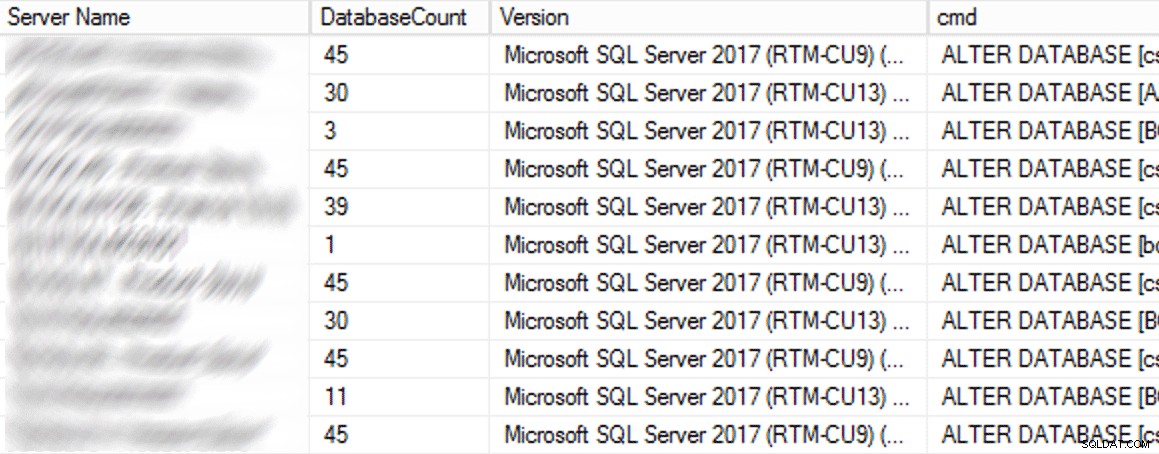 Risultati parziali dalla query CMS.
Risultati parziali dalla query CMS.
Quindi ho eseguito di nuovo la query CMS, questa volta con sys.sp_executesql senza commento. Ci sono voluti circa 12 minuti per eseguirlo su tutti i 1.590 database. Nel giro di un'ora, stavo già ricevendo segnalazioni di persone che osservavano un calo significativo della CPU in alcune delle istanze più occupate.
Ho ancora altro da fare. Ad esempio, devo testare il potenziale impatto su tempdb e se c'è un peso nel nostro caso d'uso per le storie dell'orrore che ho sentito. E dobbiamo assicurarci che l'impostazione di 60 secondi faccia parte della nostra automazione e di tutte le richieste di creazione di database, in particolare quelle che vengono eseguite tramite script o ripristinate dai backup.