Questo post del blog presenterà un semplice tipo di esempio "hello world" su come ottenere i dati archiviati in S3 indicizzati e serviti da un servizio Apache Solr ospitato in un cluster di esplorazione ed esplorazione di dati in CDP. Per i curiosi:DDE è un'opzione di distribuzione del cluster ottimizzata per Solr pre-templata in CDP e recentemente rilasciata in anteprima tecnica . In questo blog tratteremo solo gli ambienti AWS e S3. Le opzioni di distribuzione di Azure e ADLS sono disponibili anche nell'anteprima tecnica, ma verranno trattate in un futuro post del blog.
Descriveremo lo scenario più semplice per iniziare facilmente. Ovviamente sono possibili configurazioni di pipeline di dati più avanzate e schemi più ricchi, ma questo è un buon punto di partenza per un principiante.
Presupposti:
- Hai già un account CDP e disponi dei diritti di utente avanzato o amministratore per l'ambiente in cui prevedi di avviare questo servizio.
Se non disponi di un account CDP AWS, contatta il tuo rappresentante Cloudera preferito o registrati per una prova CDP qui. - Hai ambienti e identità mappati e configurati. Più esplicitamente, tutto ciò che serve è avere la mappatura dell'utente CDP su un ruolo AWS che concede l'accesso allo specifico bucket s3 da cui vuoi leggere (e scrivere).
- Hai già impostato una password per il carico di lavoro (FreeIPA).
- Hai un cluster DDE in esecuzione. Puoi anche trovare ulteriori informazioni sull'utilizzo dei modelli in CDP Data Hub qui.
- Hai accesso CLI a quel cluster.
- La porta SSH è aperta su AWS come per il tuo indirizzo IP. È possibile ottenere l'indirizzo IP pubblico per uno dei nodi Solr all'interno dei dettagli del cluster Datahub. Scopri qui come eseguire l'SSH su un cluster AWS.
- Hai un file di log in un bucket S3 accessibile per il tuo utente (
/sample.log in questo esempio). Se non ne hai uno, ecco un link a quello che abbiamo utilizzato.
Flusso di lavoro
Le sezioni seguenti ti guideranno attraverso i passaggi per ottenere i dati indicizzati utilizzando lo strumento Crunch Indexer che esce dalla scatola con DDE.

Crea una raccolta per conservare il tuo indice
In HUE c'è un designer di indici; tuttavia, finché DDE è in Tech Preview, sarà in qualche modo in fase di ricostruzione e non è consigliato a questo punto. Ma per favore, provalo dopo che DDE diventa GA e facci sapere cosa ne pensi.
Per ora, puoi creare il tuo schema e le tue configurazioni Solr utilizzando lo strumento CLI 'solrctl'. Crea una configurazione chiamata "my-own-logs-config" e una raccolta chiamata "my-own-logs". Ciò richiede l'accesso alla CLI.
1. SSH a uno qualsiasi dei nodi di lavoro nel tuo cluster.
2. kinit come utente con il permesso di creare la configurazione della raccolta:
kinit
3. Assicurarsi che la variabile di ambiente SOLR_ZK_ENSEMBLE sia impostata in /etc/solr/conf/solr-env.sh. Salvane il valore poiché sarà necessario nei passaggi successivi.
Premi Invio e digita la password del tuo carico di lavoro (FreeIPA).
Ad esempio:
cat /etc/solr/conf/solr-env.sh
Uscita prevista:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Questo viene impostato automaticamente sugli host con un ruolo Solr Server o Gateway in Cloudera Manager.
4. Per generare i file di configurazione per la raccolta, eseguire il comando seguente:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate è uno dei modelli predefiniti forniti con Solr in CDP ma, essendo un modello, non è modificabile. Ai fini di questo flusso di lavoro, è necessario copiarlo e quindi crearne uno nuovo che sia mutabile (questo è ciò che fa l'opzione immutable=false). Ciò fornisce una configurazione flessibile e senza schema. La creazione di uno schema ben progettato è qualcosa in cui vale la pena investire tempo di progettazione, ma non è necessario per l'uso esplorativo. Per questo motivo va oltre lo scopo di questo post sul blog. In un ambiente di produzione reale, tuttavia, consigliamo vivamente l'uso di schemi ben progettati e, se necessario, siamo lieti di fornire l'aiuto di esperti!
5. Crea una nuova collezione usando il seguente comando:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Questo crea la raccolta "my-own-logs" basata sulla configurazione della raccolta "my-own-logs-config" su uno shard.
6. Per convalidare la creazione della raccolta, è possibile accedere all'interfaccia utente di Solr Admin. La raccolta per "i miei-log" sarà disponibile tramite il menu a tendina nella navigazione a sinistra.

Indicizza i tuoi dati
Qui descriviamo utilizzando un semplice esempio come configurare ed eseguire lo strumento Crunch Indexer integrato per indicizzare rapidamente i dati in S3 e servire tramite Solr in DDE. Poiché la protezione del cluster può utilizzare CM Auto TLS, Knox, Kerberos e Ranger, "Spark submit" potrebbe dipendere da aspetti non trattati in questo post.
L'indicizzazione dei dati da S3 equivale all'indicizzazione da HDFS.
Esegui questi passaggi sul nodo di lavoro Yarn (denominato "Yarnworker" nell'interfaccia utente web della Console di gestione).
1. SSH al nodo di lavoro Yarn dedicato del cluster DDE come utente amministratore Solr.
Per scoprire l'indirizzo IP del nodo di lavoro Yarn, fare clic su Hardware scheda nella pagina dei dettagli del cluster, quindi scorrere fino al nodo "Yarnworker".

2. Vai alla tua directory delle risorse (o creane una se non la hai già:
cd
Utilizzare la cartella home dell'utente amministratore come directory delle risorse (
3. Kinit il tuo utente :
kinit
Premi Invio e digita la password del tuo carico di lavoro (FreeIPA).
4. Eseguire il seguente comando curl, sostituendo
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Crea un file di configurazione Morphline per lo strumento Crunch Indexer, read-log-morphline.conf in questo esempio. Sostituisci
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
] Questa Morphline legge le tracce dello stack dal file di registro specificato, quindi scrive un registro delle voci di debug e lo carica nel Solr specificato.
6. Crea un file log4j.properties per la configurazione del registro:
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Controlla se il file che vuoi leggere esiste su S3 (se non ne hai uno, ecco un link a quello che abbiamo usato per questo semplice esempio:
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Esegui il comando spark-submit:
Sostituisci i segnaposto in
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Se incontri un messaggio simile, potresti ignorarlo:
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
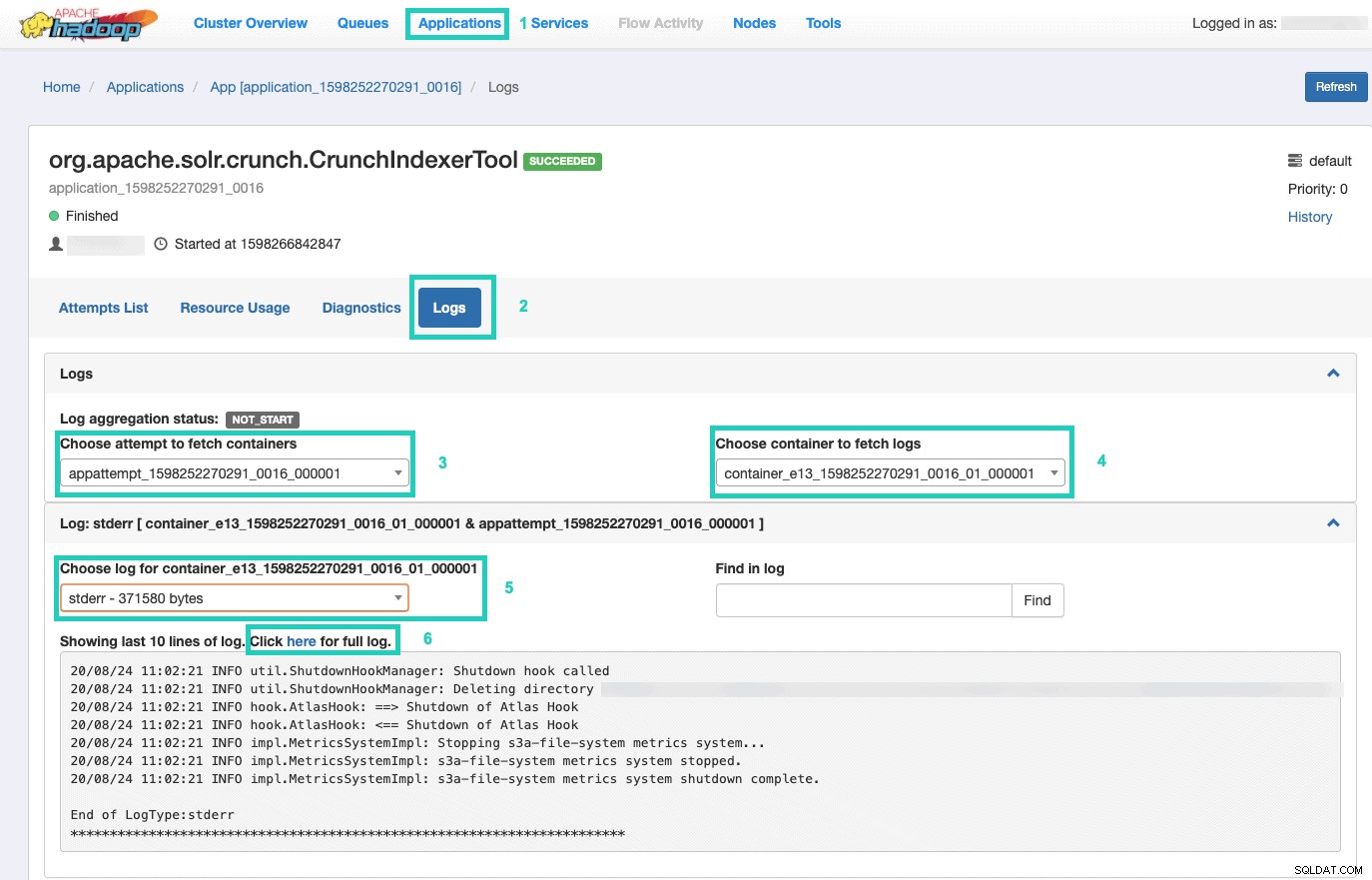
9. Per monitorare l'esecuzione del comando, vai a Gestione risorse.

Una volta lì, seleziona le Applicazioni scheda > Fai clic sull'ID applicazione del tentativo di applicazione che desideri monitorare > Seleziona Registri> Scegli tentativo di recuperare i contenitori> Scegli il contenitore per recuperare i log> Scegli il registro per il contenitore> Seleziona lo stderr log> Fai clic su Fai clic qui per il log completo .
Servisci il tuo indice
Hai molte opzioni su come fornire i dati indicizzati ricercabili agli utenti finali. Puoi creare la tua ricca applicazione basata sulle ricche API di Solr (molto comune). Puoi collegare il tuo strumento di terze parti preferito, come Qlik, Tableau ecc., tramite le loro connessioni Solr certificate. Puoi utilizzare la semplice dashboard solr di Hue per creare applicazioni prototipo.
Per fare quest'ultimo:
1. Vai a Tonalità.

2. Nella visualizzazione dashboard, vai al file di indice di tua scelta (ad esempio quello che hai appena creato).
3. Inizia a trascinare e rilasciare vari elementi del dashboard e seleziona i campi dall'indice per popolare i dati per l'oggetto visivo a portata di mano.
Un rapido tutorial video della dashboard del passato può essere trovato qui, come fonte di ispirazione.
Lasceremo un approfondimento per un futuro post sul blog.
Riepilogo
Ci auguriamo che tu abbia imparato molto da questo post del blog su come ottenere i dati in S3 indicizzati da Solr in un DDE utilizzando lo strumento Crunch Indexer. Ovviamente ci sono molti altri modi (Spark nell'esperienza di ingegneria dei dati, Nifi nell'esperienza di flusso di dati, Kafka nell'esperienza di gestione del flusso e così via), ma questi saranno trattati nei futuri post del blog. Ci auguriamo che tu abbia molto successo nel tuo continuo viaggio nella creazione di potenti applicazioni di insight che coinvolgono testo e altri dati non strutturati. Se decidi di provare DDE in CDP, facci sapere come è andato tutto!



