Se vuoi sapere tutto su Hadoop MapReduce, sei nel posto giusto. Questo tutorial di MapReduce ti fornisce la guida completa su tutto in Hadoop MapReduce.
In questa introduzione a MapReduce, esplorerai cos'è Hadoop MapReduce, come funziona il framework MapReduce. L'articolo copre anche MapReduce DataFlow, Diverse fasi in MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality e molti altri.
Abbiamo anche sfruttato i vantaggi del framework MapReduce.
Per prima cosa esploriamo perché abbiamo bisogno di Hadoop MapReduce.
Perché MapReduce?
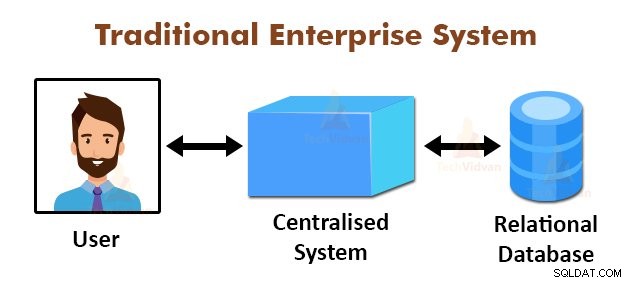
La figura sopra mostra la vista schematica dei tradizionali sistemi aziendali. I sistemi tradizionali dispongono normalmente di un server centralizzato per la memorizzazione e l'elaborazione dei dati. Questo modello non è adatto per l'elaborazione di enormi quantità di dati scalabili.
Inoltre, questo modello non può essere ospitato dai server di database standard. Inoltre, il sistema centralizzato crea troppi colli di bottiglia durante l'elaborazione simultanea di più file.
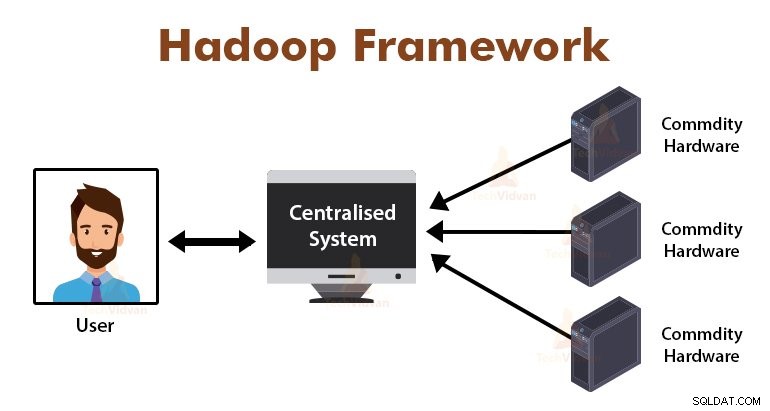
Utilizzando l'algoritmo MapReduce, Google ha risolto questo problema di collo di bottiglia. Il framework MapReduce divide l'attività in piccole parti e assegna le attività a molti computer.
Successivamente, i risultati vengono raccolti in un luogo comune e quindi integrati per formare il set di dati dei risultati.
Introduzione a MapReduce Framework
MapReduce è il livello di elaborazione in Hadoop. È un framework software progettato per elaborare enormi volumi di dati in parallelo dividendo l'attività nell'insieme di attività indipendenti.
Dobbiamo solo inserire la logica aziendale nel modo in cui funziona MapReduce e il framework si occuperà del resto delle cose. Il framework MapReduce funziona dividendo il lavoro in piccoli compiti e assegna questi compiti agli schiavi.
I programmi MapReduce sono scritti in uno stile particolare influenzato dai costrutti di programmazione funzionale, idiomi specifici per l'elaborazione delle liste di dati.
In MapReduce, gli input sono sotto forma di un elenco e anche l'output del framework è sotto forma di un elenco. MapReduce è il cuore di Hadoop. L'efficienza e la potenza di Hadoop sono dovute all'elaborazione parallela del framework MapReduce.
Esploriamo ora come funziona Hadoop MapReduce.
Come funziona Hadoop MapReduce?
Il framework Hadoop MapReduce funziona dividendo un lavoro in attività indipendenti ed eseguendo queste attività su macchine slave. Il lavoro MapReduce viene eseguito in due fasi che sono la fase di mappatura e la fase di riduzione.
L'ingresso e l'uscita da entrambe le fasi sono coppie di valori chiave. Il framework MapReduce si basa sul principio della località dei dati (discusso più avanti), il che significa che invia il calcolo ai nodi in cui risiedono i dati.
- Fase della mappa − Nella fase Mappa, la funzione mappa definita dall'utente elabora i dati di input. Nella funzione mappa, l'utente inserisce la logica aziendale. L'output della fase Map è quello intermedio e viene memorizzato sul disco locale.
- Fase di riduzione – Questa fase è la combinazione della fase di mescolamento e della fase di riduzione. Nella fase Riduci, gli output dalla fase mappa vengono passati al Riduttore dove vengono aggregati. L'uscita della fase Riduci è l'uscita finale. Nella fase di riduzione, la funzione di riduzione definita dall'utente elabora l'output dei mappatori e genera i risultati finali.
Durante il processo MapReduce, il framework Hadoop invia le attività Mappa e le attività Riduci alle macchine appropriate nel cluster.
Il framework stesso gestisce tutti i dettagli del passaggio dei dati come l'emissione di attività, la verifica del completamento delle attività e la copia dei dati tra i nodi attorno al cluster. Le attività si svolgono sui nodi in cui risiedono i dati al fine di ridurre il traffico di rete.
MapReduce il flusso di dati
Tutti voi potreste voler sapere come vengono generate queste coppie di valori chiave e come MapReduce elabora i dati di input. Questa sezione risponde a tutte queste domande.
Vediamo in che modo i dati devono fluire dalle varie fasi in Hadoop MapReduce per gestire i dati imminenti in modo parallelo e distribuito.
1. File di input
Il set di dati di input, che deve essere elaborato dal programma MapReduce, è memorizzato in InputFile. Il file di input è archiviato nel file system distribuito Hadoop.
2. InputSplit
Il record in InputFiles è suddiviso nel modello logico. La dimensione divisa è generalmente uguale alla dimensione del blocco HDFS. Ogni suddivisione viene elaborata dal singolo mappatore.
3. Formato di input
InputFormat specifica la specifica di input del file. Definisce il modo per il RecordReader in cui il record di InputFile viene convertito nella chiave, coppie di valori.
4. Lettore di record
RecordReader legge i dati da InputSplit e converte i record nella chiave, coppie di valori e li presenta ai Mapper.
5. Mappatori
I mappatori prendono le coppie chiave e valore come input dal lettore di record e le elaborano implementando la funzione di mappatura definita dall'utente. In ogni Mapper, alla volta, viene elaborata una singola suddivisione.
Lo sviluppatore ha inserito la logica aziendale nella funzione mappa. L'output di tutti i mappatori è l'output intermedio, anch'esso sotto forma di coppie di chiavi e valori.
6. Mescola e ordina
L'output intermedio generato dai Mapper viene smistato prima di passare al Reducer al fine di ridurre la congestione della rete. Le uscite intermedie ordinate vengono quindi mescolate al riduttore tramite la rete.
7. Riduttore
Il processo Reducer e aggrega gli output del Mapper implementando la funzione di riduzione definita dall'utente. L'output di Reducers è l'output finale ed è archiviato nel file system distribuito Hadoop (HDFS).
Analizziamo ora alcune terminologie e concetti avanzati del framework Hadoop MapReduce.
Coppie chiave-valore in MapReduce
Il framework MapReduce funziona sulle coppie chiave e valore perché si occupa dello schema non statico. Prende i dati sotto forma di chiave, coppia di valori e l'output generato è anche sotto forma di chiave, coppie di valori.
La coppia di valori chiave MapReduce è un'entità record che viene ricevuta dal lavoro MapReduce per l'esecuzione. In una coppia chiave-valore:
- Chiave è l'offset di riga dall'inizio della riga all'interno del file.
- Il valore è il contenuto della riga, esclusi i terminatori di riga.
Partizionatore MapReduce
Il partizionatore Hadoop MapReduce partiziona lo spazio delle chiavi. Il partizionamento dello spazio delle chiavi in MapReduce specifica che tutti i valori di ciascuna chiave sono stati raggruppati e garantisce che tutti i valori della singola chiave debbano andare allo stesso riduttore.
Questa partizione consente una distribuzione uniforme dell'output del mapper su Reducer assicurando che la chiave giusta vada al Reducer giusto.
Il partizionatore MapReducer predefinito è Hash Partitioner, che partiziona gli spazi delle chiavi in base al valore hash.
Combinatore MapReduce
Il MapReduce Combiner è anche noto come "Semi-riduttore". Svolge un ruolo importante nella riduzione della congestione della rete. Il framework MapReduce fornisce la funzionalità per definire il Combiner, che combina l'output intermedio dei Mapper prima di passarli a Reducer.
L'aggregazione degli output di Mapper prima del passaggio a Reducer aiuta il framework a mescolare piccole quantità di dati, portando a una bassa congestione della rete.
La funzione principale del Combinatore è quella di riassumere l'output dei Mapper con la stessa chiave e passarlo al Riduttore. La classe Combinatore viene utilizzata tra la classe Mapper e la classe Riduttore.
Località dati in MapReduce
La località dei dati si riferisce a "Spostare il calcolo più vicino ai dati piuttosto che spostare i dati al calcolo". È molto più efficiente se il calcolo richiesto dall'applicazione viene eseguito sulla macchina dove risiedono i dati richiesti.
Questo è molto vero nel caso in cui la dimensione dei dati è enorme. È perché riduce al minimo la congestione della rete e aumenta il throughput complessivo del sistema.
L'unico presupposto alla base di questo è che è meglio spostare il calcolo più vicino alla macchina in cui sono presenti i dati invece di spostare i dati alla macchina in cui è in esecuzione l'applicazione.
Apache Hadoop lavora su un enorme volume di dati, quindi non è efficiente spostare dati così enormi sulla rete. Quindi il framework ha prodotto il principio più innovativo che è la località dei dati, che sposta la logica di calcolo sui dati invece di spostare i dati sugli algoritmi di calcolo. Questa è chiamata località dei dati.
Vantaggi di MapReduce
Utilizzo di MapReduce
Ogni volta che una pagina Web viene trovata nel registro, una coppia chiave e valore viene passata al riduttore in cui la chiave è la pagina Web e il valore è "1". Dopo aver emesso una chiave, una coppia di valori a Reducer, i Reducer aggregano il numero di per determinate pagine web.
Il risultato finale sarà il numero totale di visite per ogni pagina web.
3. Google utilizza MapReduce per calcolare il loro Pagerank.
La funzione di riduzione concatena quindi l'elenco di tutti gli URL di origine associati all'URL di destinazione specificato e restituisce il target e l'elenco di origini.
Riepilogo
Questo è tutto sul tutorial Hadoop MapReduce. Il framework elabora enormi volumi di dati in parallelo attraverso il cluster di hardware di base. Divide il lavoro in attività indipendenti e le esegue in parallelo su diversi nodi del cluster.
MapReduce supera il collo di bottiglia del sistema aziendale tradizionale. Il framework lavora sulla chiave, coppie di valori. L'utente definisce le due funzioni che sono la funzione mappa e la funzione di riduzione.
La logica aziendale viene inserita nella funzione mappa. L'articolo ha spiegato vari concetti avanzati del framework MapReduce.



