Esplora l'architettura di Hadoop, che è il framework più adottato per l'archiviazione e l'elaborazione di enormi quantità di dati.
In questo articolo, studieremo l'architettura Hadoop. L'articolo spiega l'architettura Hadoop e i componenti dell'architettura Hadoop che sono HDFS, MapReduce e YARN. Nell'articolo esploreremo in dettaglio l'architettura Hadoop, insieme al diagramma Hadoop Architecture.
Cominciamo ora con Hadoop Architecture.
Architettura Hadoop
L'obiettivo della progettazione di Hadoop è sviluppare un framework economico, affidabile e scalabile che archivia e analizzi i big data in aumento.
Apache Hadoop è un framework software progettato da Apache Software Foundation per l'archiviazione e l'elaborazione di grandi set di dati di dimensioni e formati variabili.
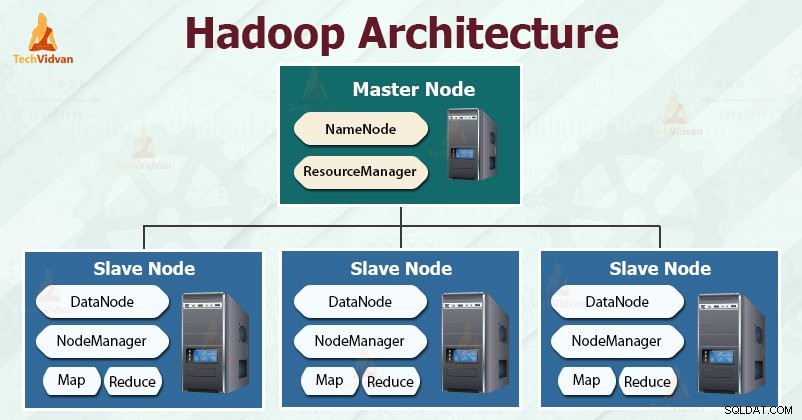
Hadoop segue il master-slave architettura per archiviare ed elaborare in modo efficace grandi quantità di dati. I nodi master assegnano compiti ai nodi slave.
I nodi slave sono responsabili della memorizzazione dei dati effettivi e dell'esecuzione del calcolo/elaborazione effettivi. I nodi master sono responsabili dell'archiviazione dei metadati e della gestione delle risorse nel cluster.
I nodi slave archiviano i dati aziendali effettivi, mentre il master archivia i metadati.
L'architettura Hadoop comprende tre livelli. Sono:
- Livello di archiviazione (HDFS)
- Livello di gestione delle risorse (YARN)
- Livello di elaborazione (MapReduce)
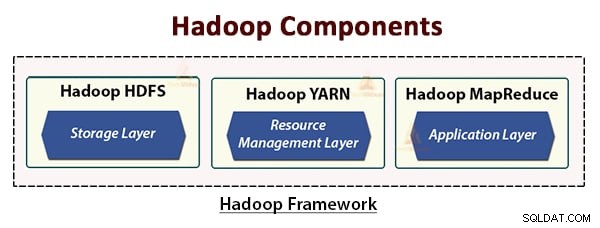
HDFS, YARN e MapReduce sono i componenti principali di Hadoop Framework.
Analizziamo ora in dettaglio queste tre componenti fondamentali.
1. HDFS
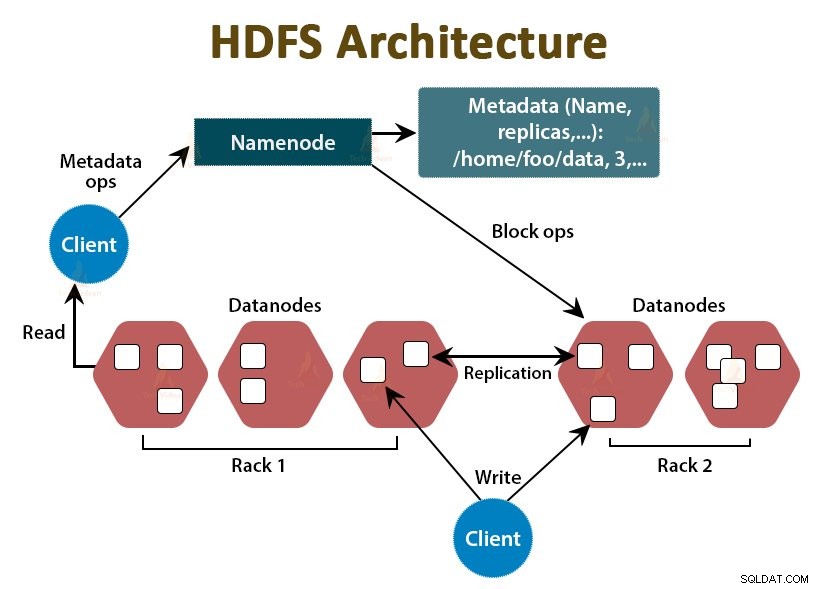
HDFS è il File system distribuito Hadoop , che funziona su hardware di fascia economica. È il livello di archiviazione per Hadoop. I file in HDFS sono suddivisi in blocchi di dimensioni blocchi chiamati blocchi di dati.
Questi blocchi vengono quindi archiviati sui nodi slave nel cluster. La dimensione del blocco è di 128 MB per impostazione predefinita, che possiamo configurare secondo i nostri requisiti.
Come Hadoop, anche HDFS segue l'architettura master-slave. Comprende due demoni:NameNode e DataNode. Il NameNode è il demone principale che viene eseguito sul nodo principale. I DataNodes sono il demone slave che gira sui nodi slave.
NomeNodo
NameNode memorizza i metadati del filesystem, ovvero i nomi dei file, le informazioni sui blocchi di un file, le posizioni dei blocchi, i permessi, ecc. Gestisce i Datanode.
DataNode
I DataNode sono i nodi slave che memorizzano i dati aziendali effettivi. Serve le richieste di lettura/scrittura del client in base alle istruzioni NameNode.
DataNodes memorizza i blocchi dei file e NameNode memorizza i metadati come posizioni dei blocchi, autorizzazioni, ecc.
2. MappaRiduci
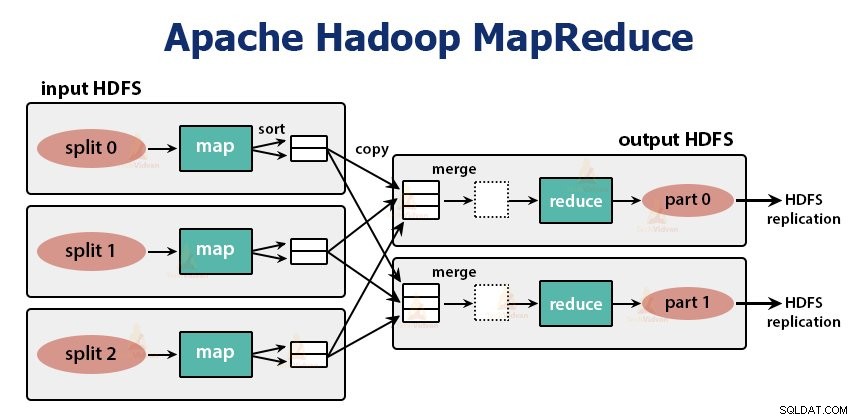
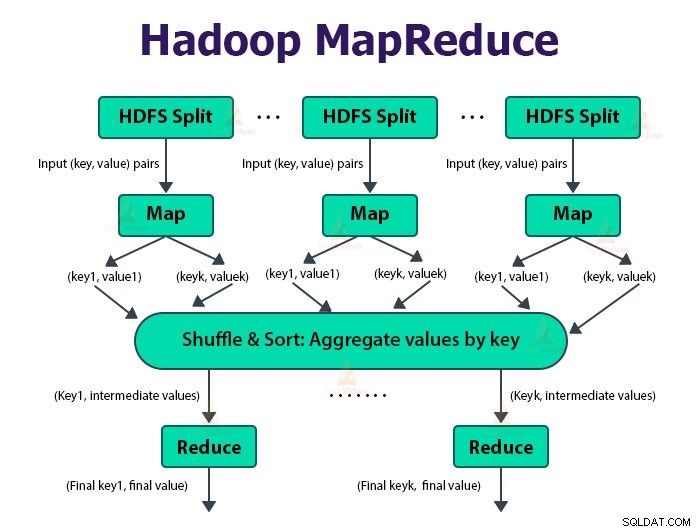
È il livello di elaborazione dei dati di Hadoop. È un framework software per la scrittura di applicazioni che elaborano grandi quantità di dati (da terabyte a petabyte nell'intervallo) in parallelo sul cluster di hardware di base.
Il framework MapReduce funziona sulle coppie
Il lavoro MapReduce è l'unità di lavoro che il cliente desidera eseguire. Il lavoro MapReduce consiste principalmente nei dati di input, nel programma MapReduce e nelle informazioni di configurazione. Hadoop esegue i lavori MapReduce dividendoli in due tipi di attività che sono attività mappa e ridurre le attività . Hadoop YARN ha pianificato queste attività e viene eseguito sui nodi del cluster.
A causa di alcune condizioni sfavorevoli, se le attività falliscono, verranno automaticamente riprogrammate su un nodo diverso.
L'utente definisce la funzione mappa e la funzione di riduzione per eseguire il lavoro MapReduce.
L'input per la funzione mappa e l'output dalla funzione di riduzione è la chiave, coppia di valori.
La funzione delle attività della mappa è caricare, analizzare, filtrare e trasformare i dati. L'output dell'attività di mappatura è l'input dell'attività di riduzione. Riduci attività esegue quindi il raggruppamento e l'aggregazione sull'output dell'attività mappa.
L'attività MapReduce viene eseguita in due fasi-
1. Fase mappa
a. Lettore di record
Hadoop divide gli input del processo MapReduce in suddivisioni di dimensioni fisse denominate divisioni di input o si divide. Il lettore di record trasforma queste suddivisioni in record e analizza i dati in record, ma non analizza i record stessi. Lettore di record fornisce i dati alla funzione di mappatura in coppie chiave-valore.
Nella fase della mappa, Hadoop crea un'attività mappa che esegue una funzione definita dall'utente chiamata funzione mappa per ogni record nella divisione di input. Genera zero o più coppie chiave-valore intermedie come output dell'attività della mappa.
L'attività di mappatura scrive il suo output sul disco locale. Questo output intermedio viene quindi elaborato dalle attività di riduzione che eseguono una funzione di riduzione definita dall'utente per produrre l'output finale. Una volta completato il lavoro, l'output della mappa viene cancellato.
L'input per l'attività di riduzione singola è l'output di tutti i mappatori che è l'output di tutte le attività della mappa. Hadoop consente all'utente di definire una funzione combinata che viene eseguita sull'output della mappa.
Combinatore raggruppa i dati nella fase della mappa prima di passarli a Reducer. Combina l'output della funzione map che viene poi passato come input alla funzione reduce.
d. Partizionatore
Quando sono presenti più riduttori, le attività di mappatura suddividono l'output, creando ciascuna una partizione per ciascuna attività di riduzione. In ogni partizione possono esserci molte chiavi e i relativi valori associati, ma i record per una determinata chiave si trovano tutti in un'unica partizione.
Hadoop consente agli utenti di controllare il partizionamento specificando una funzione di partizionamento definita dall'utente. In genere, esiste un partizionatore predefinito che esegue il bucket delle chiavi utilizzando la funzione hash.
2. Fase di riduzione:
Le varie fasi della riduzione dell'attività sono le seguenti:
a. Ordina e mescola:
L'attività Riduttore inizia con un passaggio di riproduzione casuale e ordinamento. Lo scopo principale di questa fase è raccogliere insieme le chiavi equivalenti. La fase Ordina e mescola scarica i dati che vengono scritti dal partizionatore nel nodo in cui è in esecuzione Reducer.
Ordina ogni dato in un grande elenco di dati. Il framework MapReduce esegue questo ordinamento e lo shuffle in modo da poterlo scorrere facilmente nell'attività di riduzione.
Il ordinamento e mescolamento vengono eseguiti automaticamente dal framework. Lo sviluppatore attraverso l'oggetto comparatore può avere il controllo su come le chiavi vengono ordinate e raggruppate.
Il riduttore, che è la funzione di riduzione definita dall'utente, viene eseguito una volta per raggruppamento di chiavi. Il riduttore filtra, aggrega e combina i dati in diversi modi. Una volta completata l'attività di riduzione, fornisce zero o più coppie chiave-valore a OutputFormat. L'output dell'attività di riduzione è archiviato in Hadoop HDFS.
Prende l'output del riduttore e lo scrive nel file HDFS da RecordWriter. Per impostazione predefinita, separa chiave, valore con una scheda e ogni record con un carattere di nuova riga.
3. FILATO
YARN sta per Ancora un altro negoziatore di risorse . È il livello di gestione delle risorse di Hadoop. È stato introdotto in Hadoop 2.
YARN è progettato con l'idea di suddividere le funzionalità di pianificazione dei lavori e gestione delle risorse in demoni separati. L'idea di base è avere un ResourceManager globale e un master dell'applicazione per ogni applicazione in cui l'applicazione può essere un singolo lavoro o un DAG di lavori.
YARN è costituito da ResourceManager, NodeManager e ApplicationMaster per ogni applicazione.
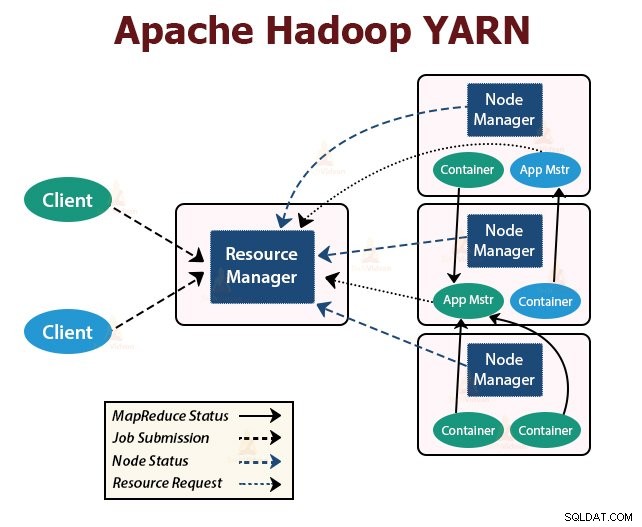
1. Responsabile risorse
Arbitra le risorse tra tutte le applicazioni nel cluster.
Ha due componenti principali che sono Scheduler e ApplicationManager.
a. Programmatore
- Lo Scheduler alloca le risorse alle varie applicazioni in esecuzione nel cluster, considerando le capacità, le code, ecc.
- È un puro Scheduler. Non monitora né traccia lo stato dell'applicazione.
- Scheduler non garantisce il riavvio delle attività non riuscite che non sono riuscite a causa di un errore dell'applicazione o dell'hardware.
- Esegue la pianificazione in base ai requisiti di risorse delle applicazioni.
- Sono responsabili dell'accettazione degli invii di lavoro.
- ApplicationManager negozia il primo contenitore per l'esecuzione di ApplicationMaster specifico per l'applicazione.
- Forniscono il servizio per riavviare il container ApplicationMaster in caso di errore.
- L'ApplicationMaster per ogni applicazione è responsabile della negoziazione dei container dallo Scheduler. Tiene traccia e monitora il loro stato e i loro progressi.
2. Node Manager:
NodeManager viene eseguito sui nodi slave. È responsabile dei contenitori, del monitoraggio dell'utilizzo delle risorse della macchina (CPU, memoria, disco, utilizzo della rete) e della segnalazione dello stesso a ResourceManager o Scheduler.
3. Maestro dell'applicazione:
L'ApplicationMaster per applicazione è una libreria specifica del framework. È responsabile della negoziazione delle risorse da ResourceManager. Funziona con i NodeManager per l'esecuzione e il monitoraggio delle attività.
Riepilogo
In questo articolo abbiamo studiato l'architettura Hadoop. Hadoop segue la topologia master-slave. I nodi master assegnano compiti ai nodi slave. L'architettura comprende tre livelli che sono HDFS, YARN e MapReduce.
HDFS è il file system distribuito in Hadoop per l'archiviazione di big data. MapReduce è il framework di elaborazione per l'elaborazione di vasti dati nel cluster Hadoop in modo distribuito. YARN è responsabile della gestione delle risorse tra le applicazioni nel cluster.
Il demone HDFS NameNode e il daemon YARN ResourceManager vengono eseguiti sul nodo master nel cluster Hadoop. Il demone HDFS DataNode e YARN NodeManager vengono eseguiti sui nodi slave.
Il framework HDFS e MapReduce viene eseguito sullo stesso set di nodi, il che si traduce in una larghezza di banda aggregata molto elevata in tutto il cluster.
Continua ad imparare!!



