In questo tutorial di Hadoop , ti forniremo un'introduzione completa della federazione HDFS. In questo tutorial parleremo dell'architettura HDFS, dei limiti dell'attuale architettura di HDFS.
Successivamente, tratteremo in dettaglio l'architettura della federazione HDFS insieme ai loro vantaggi nel framework Hadoop.
Cos'è la federazione HDFS?
Federazione migliora un Hadoop HDFS esistente architettura. L'architettura HDFS precedente consente un unico spazio dei nomi per l'intero cluster. In tale architettura, un singolo NameNode gestisce lo spazio dei nomi.
Se NameNode ha esito negativo, l'intero cluster sarà fuori servizio. E il cluster non sarà disponibile fino al riavvio di NameNode o al ripristino di un computer separato.
La federazione HDFS è stata introdotta per superare questa limitazione. Supera questo problema aggiungendo il supporto per molti NameNode/Namespace a HDFS.
Architettura HDFS attuale
HDFS ha due livelli principali indicati di seguito:
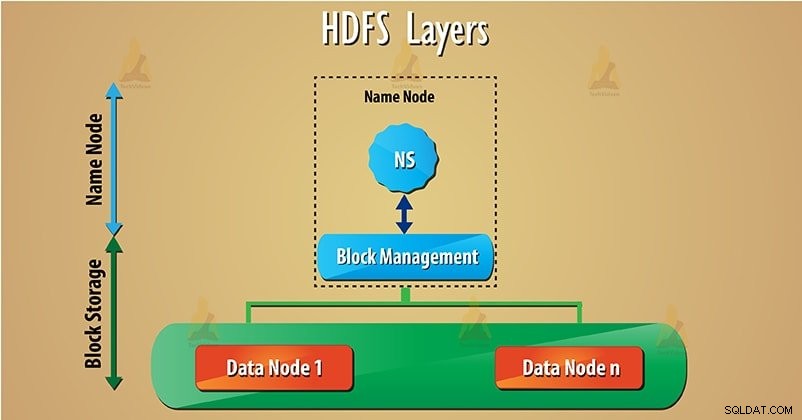
a) Spazio dei nomi – Questo livello gestisce file, directory e blocchi . Questo livello supporta le operazioni di base del file system come la creazione, l'eliminazione di file.
b) Blocca spazio di archiviazione – Ha due parti-
- Gestione dei blocchi – Supporta operazioni relative ai blocchi come la creazione, l'eliminazione dei blocchi. Gestisce i nodi di dati nel cluster e si occupa della gestione della replica.
- Archiviazione fisica – Questo memorizza i blocchi sul file system locale e fornisce l'accesso alle operazioni di lettura o scrittura. Segui questo link per apprendere le operazioni di lettura e scrittura dei dati HDFS.
Questo HDFS attuale funziona bene per le configurazioni più piccole. Tuttavia, per le grandi organizzazioni in cui dobbiamo occuparci dell'enorme quantità di dati presenta alcune limitazioni. La federazione Hadoop gestisce queste limitazioni.
Limitazione dell'attuale architettura HDFS
La limitazione dell'attuale architettura HDFS è riportata di seguito:
1. Archiviazione a blocchi strettamente accoppiati e spazio dei nomi
Livello spazio dei nomi e livello di archiviazione sono strettamente accoppiati. Rende difficile l'implementazione alternativa di namenode. E limita altri servizi all'utilizzo dell'archiviazione a blocchi.
2. Scalabilità dello spazio dei nomi
Lo spazio dei nomi non è scalabile come datanode. Il ridimensionamento nel cluster HDFS avviene orizzontalmente mediante l'aggiunta di nodi di dati. Ma non possiamo aggiungere più spazio dei nomi a un cluster esistente. Possiamo scalare verticalmente lo spazio dei nomi su un singolo namenode.
3. Prestazioni
L'intera performance di Hadoop dipende dal throughput del namenode. Un'operazione del file system corrente dipende dal throughput di un singolo namenode. NameNode attualmente supporta 60.000 attività simultanee.
Prossimamente MapReduce avrà il supporto per più di 1.00.000 attività simultanee. E questo avrà bisogno di più namenode.
4. Isolamento
Non c'è separazione dello spazio dei nomi. Quindi non c'è isolamento tra l'organizzazione tenant che utilizza il cluster.
HDFS Architettura della federazione
La federazione usa molti Namenode/spazi dei nomi indipendenti per ridimensionare orizzontalmente il servizio dei nomi. Nell'architettura della federazione HDFS, nella parte inferiore, sono presenti i datanode. E i datanode sono usati come memoria comune per i blocchi da tutti i namenode.
Ciascun nodo di dati si registra con tutti i nodi di nome nel cluster. Questi nodi di dati inviano heartbeat periodici, bloccano, segnalano e gestiscono i comandi dai nodi di nome.
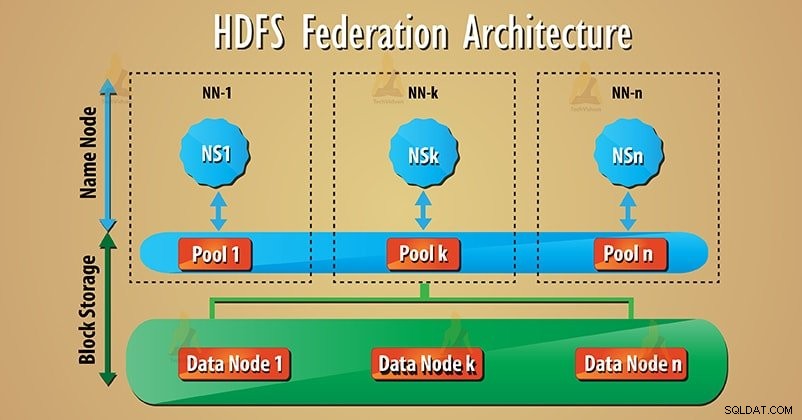
Molti namenode (NN1, NN2…, NNn) gestiscono rispettivamente molti namespace (NS1, NS2…, NSn). Ogni spazio dei nomi ha il proprio pool di blocchi (NS1 ha il pool 1 e così via). Il blocco dal pool 1 viene archiviato sul nodo dati 1 e così via.
1. Blocco pool
L'insieme di blocchi è Pool di blocchi che appartiene a un singolo spazio dei nomi. Esiste una raccolta di pool nell'architettura della federazione HDFS. E ogni blocco è gestito dall'altro.
Ciò consente a uno spazio dei nomi di creare un ID blocco per nuovi blocchi senza coordinamento con un altro spazio dei nomi. Tutti i Datanode memorizzano i blocchi di dati presenti in tutti i pool di blocchi.
2. Volume spazio dei nomi
Lo spazio dei nomi insieme al relativo pool di blocchi è Volume dello spazio dei nomi . Nella federazione HDFS sono presenti molti volumi dello spazio dei nomi. Quindi, ogni volume dello spazio dei nomi funziona in modo indipendente. Quando eliminiamo namenode o namespace, verrà eliminato anche il pool di blocchi corrispondente presente sui datanode.
Vantaggi della Federazione HDFS
La federazione HDFS supera i limiti dell'architettura HDFS precedente. Quindi fornisce:
- Isolamento – Non c'è isolamento in un singolo namenode in un ambiente multiutente. Nella federazione HDFS diverse categorie di applicazioni e utenti possono essere isolate in spazi dei nomi diversi utilizzando molti namenode.
- Scalabilità dello spazio dei nomi – Nella federazione molti namenode aumentano orizzontalmente nello spazio dei nomi del filesystem.
- Prestazioni – Possiamo migliorare il throughput delle operazioni di lettura/scrittura aggiungendo più namenode.
Conclusione
In conclusione a HDFS Federation, possiamo dire che supera i limiti dell'architettura HDFS a nodo singolo. Nella precedente architettura HDFS per un intero cluster consente solo un singolo spazio dei nomi. Mentre Federation utilizza molti Namenode/spazi dei nomi indipendenti per ridimensionare il servizio dei nomi in orizzontale.
Separa anche il livello dello spazio dei nomi e lo spazio di archiviazione strato. Quindi fornisce isolamento, scalabilità e design semplice.
Se hai domande o suggerimenti relativi alla Federazione in Hadoop HDFS, faccelo sapere lasciando un commento.



