Nella nostra precedente tutta Hadoop o rial , ti abbiamo fornito una descrizione dettagliata di InputFormat. Ora in questo blog tratteremo Hadoop OutputFormat.
Discuteremo cos'è OutputFormat in Hadoop, Cos'è RecordWritter in MapReduce OutputFormat. Tratteremo anche i tipi di OutputFormat in MapReduce.
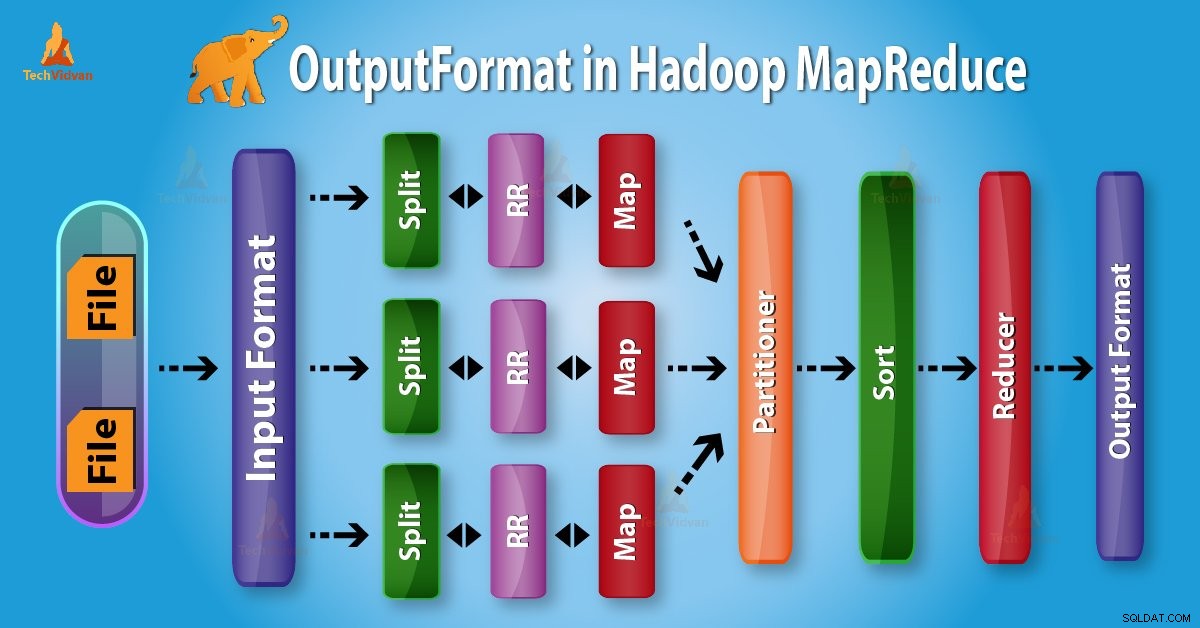
Introduzione a Hadoop OutputFormat
Formato di output controllare le specifiche di output per l'esecuzione del lavoro Map-Reduce. Descrive come viene utilizzata l'implementazione di RecordWriter per scrivere l'output nei file di output.
Prima di iniziare con OutputFormat, impariamo prima cosa è RecordWriter e qual è il lavoro di RecordWriter in MapReduce?
1. RecordWriter in Hadoop MapReduce
Come sappiamo, Riduttore prende Mapper uscita intermedia come ingresso. Quindi esegue una funzione di riduzione su di essi per generare un output che è di nuovo zero o più coppie chiave-valore.
Pertanto, RecordWriter nell'esecuzione del lavoro MapReduce scrive queste coppie chiave-valore di output dalla fase Reducer nei file di output.
2. Formato output Hadoop
Dall'alto è chiaro che RecordWriter prende i dati di output da Reducer. Quindi scrive questi dati nei file di output. OutputFormat determina il modo in cui queste coppie chiave-valore di output vengono scritte nei file di output da RecordWriter.
Le funzioni OutputFormat e InputFormat sono simili. Le istanze OutputFormat vengono utilizzate per scrivere su file sul disco locale o in HDFS. In MapReduce l'esecuzione del lavoro sulla base delle specifiche di output;
- Il lavoro Hadoop MapReduce verifica che la directory di output non sia già presente.
- OutputFormat nel lavoro MapReduce fornisce l'implementazione RecordWriter da utilizzare per scrivere i file di output del lavoro. Quindi i file di output vengono archiviati in un FileSystem.
Il framework utilizza FileOutputFormat.setOutputPath() metodo per impostare la directory di output.
Tipi di OutputFormat in MapReduce
Esistono vari tipi di OutputFormat che sono i seguenti:
1. Formato TextOutput
L'OutputFormat predefinito è TextOutputFormat. Scrive coppie (chiave, valore) su singole righe di file di testo. Le sue chiavi e valori possono essere di qualsiasi tipo. Il motivo è che TextOutputFormat li trasforma in string chiamando toString() su di loro.
Separa la coppia chiave-valore con un carattere di tabulazione. Utilizzando MapReduce.output.textoutputformat.separator proprietà possiamo anche cambiarla.
KeyValueTextOutputFormat viene utilizzato anche per leggere questi file di testo di output.
2. SequenceFileOutputFormat
Questo OutputFormat scrive file di sequenze per il suo output. SequenceFileInputFormat è anche un formato intermedio utilizzato tra i lavori MapReduce. Serializza i tipi di dati arbitrari nel file.
E il corrispondente SequenceFileInputFormat deserializzerà il file negli stessi tipi. Presenta i dati al prossimo mappatore nello stesso modo in cui era emesso dal precedente riduttore. I metodi statici controllano anche la compressione.
3. SequenceFileAsBinaryOutputFormat
È un'altra variante di SequenceFileInputFormat. Scrive anche chiavi e valori in un file di sequenza in formato binario.
4. MapFileOutputFormat
È un'altra forma di FileOutputFormat. Scrive anche l'output come file di mappa. Il framework aggiunge una chiave in un MapFile in ordine. Quindi dobbiamo assicurarci che il riduttore emetta le chiavi in ordine.
5. Più uscite
Questo formato consente di scrivere dati su file i cui nomi derivano dalle chiavi e dai valori di output.
6. LazyOutputFormat
Nell'esecuzione del lavoro MapReduce, FileOutputFormat a volte crea file di output, anche se sono vuoti. LazyOutputFormat è anche un wrapper OutputFormat.
7. Formato DBOutput
È l'OutputFormat per scrivere su database relazionali e HBase. Questo formato invia anche l'output di riduzione a una tabella SQL. Accetta anche coppie chiave-valore. In questo, la chiave ha un tipo che si estende DBwritable.
Conclusione
Pertanto, vengono utilizzati OutputFormats diversi in base alle esigenze. Spero che questo blog ti sia stato utile. Se hai qualche domanda su Hadoop OutputFormat, quindi per favore lascia un commento in una casella di commento. Saremo lieti di risolverli.



