L'obiettivo principale di questo Tutorial Hadoop consiste nel fornirti una descrizione dettagliata di ogni componente utilizzato nel funzionamento di Hadoop. In questo tutorial tratteremo il partizionatore in Hadoop.
Che cos'è Hadoop Partitioner, qual è la necessità di Partitioner in Hadoop, Qual è il Partitioner predefinito in MapReduce, Quanti MapReduce Partitioner sono utilizzati in Hadoop?
Risponderemo a tutte queste domande in questo tutorial di MapReduce.
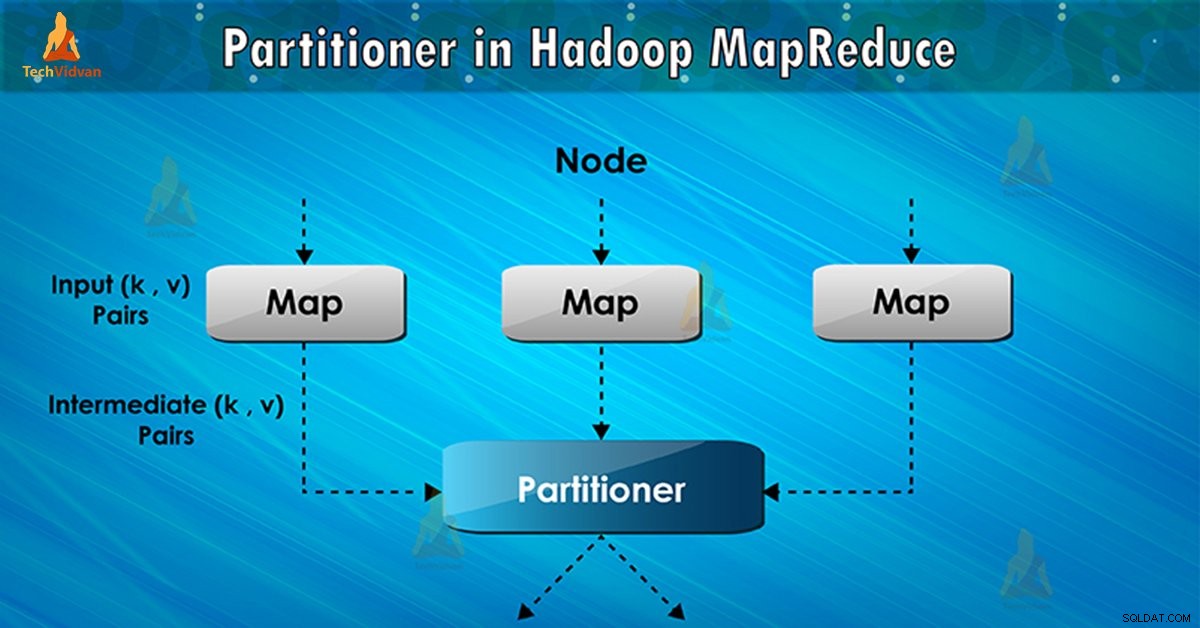
Cos'è Hadoop Partitioner?
Il partizionatore nell'esecuzione del lavoro MapReduce controlla il partizionamento delle chiavi degli output della mappa intermedi. Con l'aiuto della funzione hash, chiave (o un sottoinsieme della chiave) deriva la partizione. Il numero totale di partizioni è uguale al numero di attività di riduzione.
Sulla base del valore chiave , partizioni del framework, ogni mappatore produzione. I record con lo stesso valore di chiave vanno nella stessa partizione (all'interno di ogni mappatore). Quindi ogni partizione viene inviata a un riduttore .
La classe di partizione decide quale partizione andrà a una data coppia (chiave, valore). La fase di partizione nel flusso di dati MapReduce avviene dopo la fase della mappa e prima della fase di riduzione.
Necessità di MapReduce Partitioner in Hadoop
Nell'esecuzione del lavoro MapReduce, prende un set di dati di input e produce l'elenco delle coppie chiave-valore. Questa coppia chiave-valore è il risultato della fase della mappa. In cui i dati di input sono divisi e ogni attività elabora la divisione e ogni mappa, genera l'elenco delle coppie chiave-valore.
Quindi, il framework invia l'output della mappa per ridurre l'attività. Riduci i processi la funzione di riduzione definita dall'utente sugli output della mappa. Prima di ridurre la fase, avviene il partizionamento dell'output della mappa in base alla chiave.
Il partizionamento Hadoop specifica che tutti i valori per ciascuna chiave sono raggruppati. Si assicura inoltre che tutti i valori di una singola chiave vadano allo stesso riduttore. Ciò consente una distribuzione uniforme dell'output della mappa sul riduttore.
Il partizionatore in un processo MapReduce reindirizza l'output del mappatore al riduttore determinando quale riduttore gestisce la chiave particolare.
Partizionatore predefinito Hadoop
Partizionatore hash è il partizionatore predefinito. Calcola un valore hash per la chiave. Assegna anche la partizione in base a questo risultato.
Quanti partizionatori in Hadoop?
Il numero totale di Partitioner dipende dal numero di riduttori. Hadoop Partitioner divide i dati in base al numero di riduttori. È impostato da JobConf.setNumReduceTasks() metodo.
Pertanto il singolo riduttore elabora i dati dal singolo partizionatore. La cosa importante da notare è che il framework crea un partizionatore solo quando ci sono molti riduttori.
Partizionamento scadente in Hadoop MapReduce
Se nell'immissione dei dati nel lavoro MapReduce una chiave appare più di qualsiasi altra chiave. In tal caso, per inviare i dati alla partizione utilizziamo due meccanismi che sono i seguenti:
- La chiave che appare più volte verrà inviata a una partizione.
- Tutte le altre chiavi verranno inviate alle partizioni sulla base del loro hashCode() .
Se hashCode() il metodo non distribuisce altri dati chiave nell'intervallo di partizione. Quindi i dati non verranno inviati ai riduttori.
Una scarsa partizione dei dati significa che alcuni riduttori avranno più input di dati rispetto ad altri. Avranno più lavoro da fare rispetto ad altri riduttori. Quindi l'intero lavoro deve attendere che un riduttore finisca la sua parte extra-grande del carico.
Come superare il partizionamento scadente in MapReduce?
Per superare un partizionamento scadente in Hadoop MapReduce, possiamo creare un partizionatore personalizzato. Ciò consente di condividere il carico di lavoro tra diversi riduttori.
Conclusione
In conclusione, Partitioner consente una distribuzione uniforme dell'output della mappa sul riduttore. In MapReducer Partitioner, il partizionamento dell'output della mappa avviene in base alla chiave e al valore.
Quindi, abbiamo coperto la panoramica completa di Partitioner in questo blog. Spero ti sia piaciuto. Se qualche dubbio ti viene in mente su Hadoop Partitioner, quindi non dimenticare di condividere con noi.



