Questo tutorial Hadoop è tutto incentrato su MapReduce Shuffling e Sorting. Qui ti forniremo una descrizione dettagliata della fase di mescolamento e ordinamento di Hadoop.
In primo luogo discuteremo cos'è MapReduce Shuffling, quindi MapReduce Sorting, quindi tratteremo in dettaglio la fase di ordinamento secondario di MapReduce.
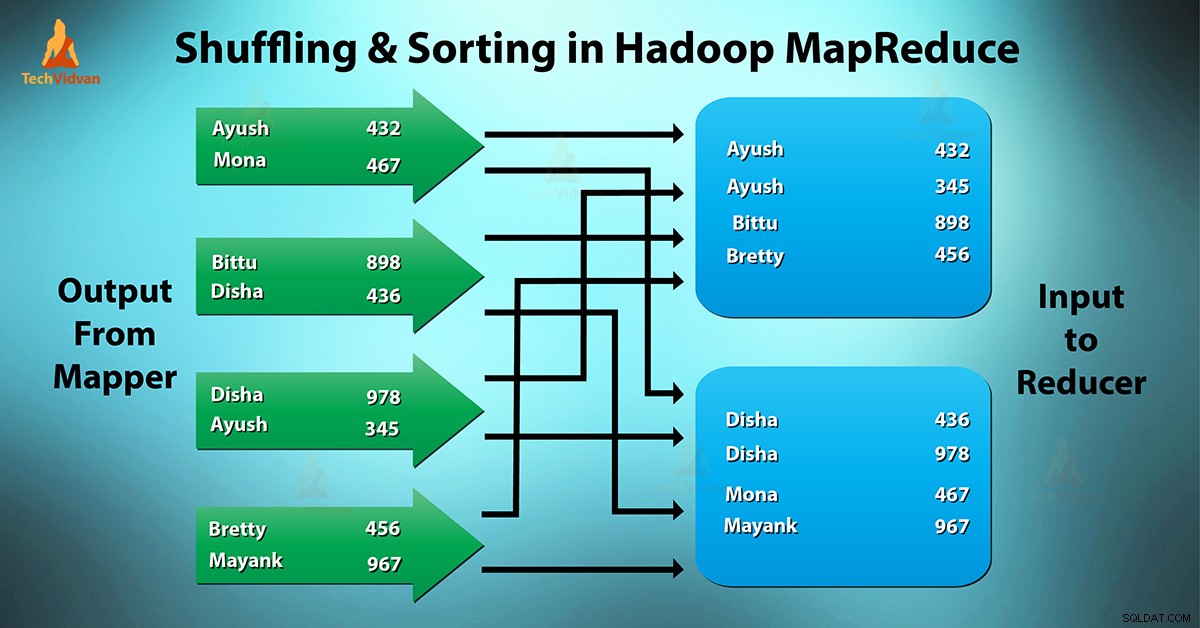
Cos'è MapReduce Shuffling and Sorting?
Rimescolamento è il processo mediante il quale trasferisce i mappatori uscita intermedia al riduttore. Il riduttore ottiene 1 o più chiavi e valori associati in base ai riduttori.
La chiave intermedia – valore generato dal mapper viene ordinato automaticamente per chiave. Nella fase di ordinamento avviene l'unione e l'ordinamento dell'output della mappa.
La mescolanza e l'ordinamento in Hadoop avvengono contemporaneamente.
Shuffling in MapReduce
Il processo di trasferimento dei dati dai mappatori ai riduttori sta mescolando. È anche il processo mediante il quale il sistema esegue l'ordinamento. Quindi trasferisce l'output della mappa al riduttore come input. Questo è il motivo per cui è necessaria la fase di shuffle per i riduttori.
Altrimenti, non avrebbero alcun input (o input da ogni mappatore). Dal momento che il rimescolamento può iniziare anche prima che la fase della mappa sia terminata. In questo modo si risparmia un po' di tempo e si completano le attività in minor tempo.
Ordinamento in MapReduce
MapReduce Framework ordina automaticamente le chiavi generate dal mapper. Pertanto, prima di avviare il riduttore, tutte le coppie chiave-valore intermedie vengono ordinate per chiave e non per valore. Non ordina i valori passati a ciascun riduttore. Possono essere in qualsiasi ordine.
L'ordinamento in un processo MapReduce aiuta Reducer a distinguere facilmente quando deve iniziare un nuovo processo di riduzione.
Ciò consente di risparmiare tempo per il riduttore. Reducer in MapReduce avvia una nuova attività di riduzione quando la chiave successiva nei dati di input ordinati è diversa dalla precedente. Ogni attività di riduzione accetta coppie chiave-valore come input e genera coppie chiave-valore come output.
La cosa importante da notare è che la mescolanza e l'ordinamento in Hadoop MapReduce non avranno luogo se si specificano zero riduttori (setNumReduceTasks(0)).
Se reducer è zero, il lavoro MapReduce si interrompe nella fase della mappa. E la fase mappa non prevede alcun tipo di ordinamento (anche la fase mappa è più veloce).
Ordinamento secondario in MapReduce
Se vogliamo ordinare i valori del riduttore, utilizziamo una tecnica di ordinamento secondario. Questa tecnica ci consente di ordinare i valori (in ordine crescente o decrescente) passati a ciascun riduttore.
Conclusione
In conclusione, MapReduce Shuffling e Sorting si verificano simultaneamente per riassumere l'output intermedio del Mapper. Se si specificano riduttori zero (setNumReduceTasks (0)) non si verificherà Hadoop Shuffling-Sorting.
Framework ordina tutte le coppie chiave-valore intermedie per chiave, non per valore. Utilizza l'ordinamento secondario per l'ordinamento per valore. Se hai suggerimenti o domande relative alla fase di selezione e ordinamento di MapReduce, lascia un commento in una casella dei commenti.
Saremo felici di risolverli.



