Vuoi sapere tutto sul cluster Hadoop?
Hadoop è un framework software per l'analisi e l'archiviazione di grandi quantità di dati in cluster di hardware di base. In questo articolo studieremo un cluster Hadoop.
Iniziamo con un'introduzione a Cluster.
Cos'è un cluster?
Un Cluster è una raccolta di nodi. I nodi non sono altro che un punto di connessione/intersezione all'interno di una rete.
Un cluster di computer è un insieme di computer collegati a una rete, in grado di comunicare tra loro e funziona come un unico sistema.
Cos'è il cluster Hadoop?
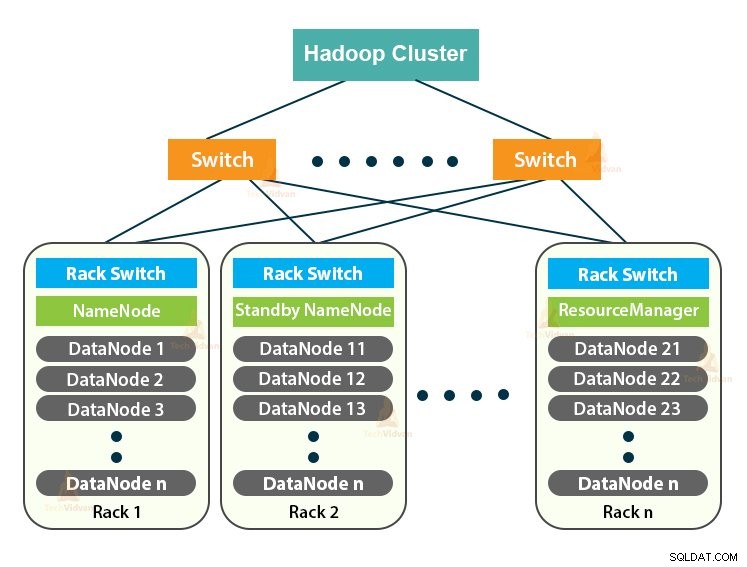
Hadoop Cluster è solo un cluster di computer utilizzato per gestire una grande quantità di dati in modo distribuito.
È un cluster computazionale progettato per archiviare e analizzare enormi quantità di dati non strutturati o strutturati in un ambiente informatico distribuito.
I cluster Hadoop sono anche noti come sistemi di condivisione nulla perché nulla è condiviso tra i nodi nel cluster tranne la larghezza di banda della rete. Ciò riduce la latenza di elaborazione.
Pertanto, quando è necessario elaborare query sull'enorme quantità di dati, la latenza a livello di cluster viene ridotta al minimo.
Studiamo ora l'architettura del cluster Hadoop.
Architettura del cluster Hadoop
Il cluster Hadoop segue un'architettura master-slave. È costituito dal nodo master, dai nodi slave e dal nodo client.
1. Master in Hadoop Cluster
Master in Hadoop Cluster è una macchina ad alta potenza con un'elevata configurazione di memoria e CPU. I due demoni che sono NameNode e ResourceManager vengono eseguiti sul nodo master.
a. Funzioni di NameNode
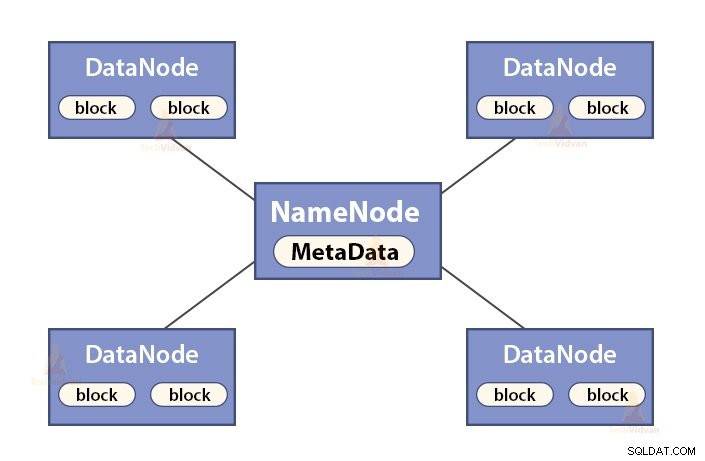
NameNode è un nodo master in Hadoop HDFS . NameNode gestisce lo spazio dei nomi del filesystem. Memorizza i metadati del filesystem nella memoria per un rapido recupero. Quindi, dovrebbe essere configurato su macchine di fascia alta.
Le funzioni di NameNode sono:
- Gestisce lo spazio dei nomi del filesystem
- Memorizza i metadati sui blocchi di un file, la posizione dei blocchi, le autorizzazioni e così via
- Esegue le operazioni dello spazio dei nomi del filesystem come l'apertura, la chiusura, la ridenominazione di file e directory, ecc.
- Mantiene e gestisce il DataNode.
b. Funzioni di Resource Manager
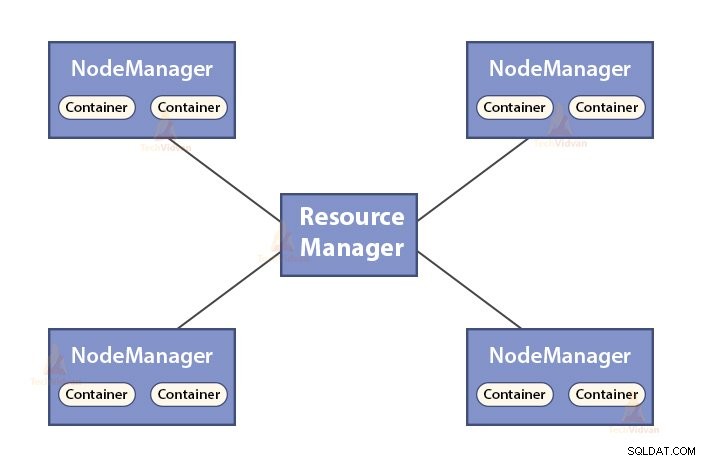
- ResourceManager è il demone principale di YARN.
- Il ResourceManager arbitra le risorse tra tutte le applicazioni nel sistema.
- Tiene traccia dei nodi attivi e morti nel cluster.
2. Schiavi nel cluster Hadoop
Gli schiavi nel cluster Hadoop sono hardware di base poco costoso. I due demoni che sono DataNode e YARN NodeManager vengono eseguiti sui nodi slave.
a. Funzioni di DataNode
- DataNodes memorizza i dati aziendali effettivi. Memorizza i blocchi di un file.
- Esegue la creazione di blocchi, la cancellazione, la replica in base alle istruzioni di NameNode.
- DataNode è responsabile delle operazioni di lettura/scrittura del client.
b. Funzioni di NodeManager
- NodeManager è il demone slave di YARN.
- È responsabile dei container, monitora il loro utilizzo delle risorse (come CPU, disco, memoria, rete) e segnala le stesse al ResourceManager.
- Il NodeManager controlla anche lo stato del nodo su cui è in esecuzione.
3. Nodo client nel cluster Hadoop
I nodi client in Hadoop non sono né nodi master né nodi slave. Hanno Hadoop installato su di loro con tutte le impostazioni del cluster.
Funzioni dei nodi Client
- I nodi client caricano i dati nel cluster Hadoop.
- Invia i lavori MapReduce, descrivendo come devono essere elaborati i dati.
- Recupera i risultati del lavoro dopo il completamento dell'elaborazione.
Possiamo scalare il cluster Hadoop aggiungendo più nodi. Questo rende Hadoop linearmente scalabile . Con ogni aggiunta di nodi, otteniamo un corrispondente aumento del throughput. Se abbiamo 'n' nodi, l'aggiunta di 1 nodo fornisce (1/n) potenza di calcolo aggiuntiva.
Cluster Hadoop a nodo singolo VS Cluster Hadoop a più nodi
1. Cluster Hadoop a nodo singolo
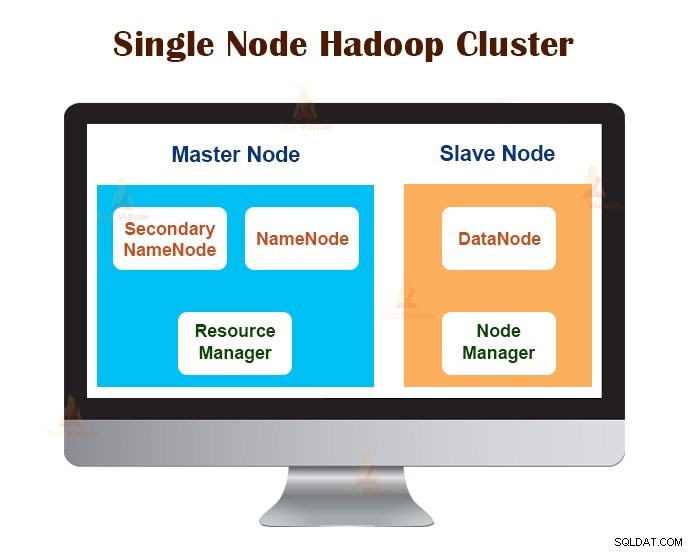
Il cluster Hadoop a nodo singolo viene distribuito su una singola macchina. Tutti i demoni come NameNode, DataNode, ResourceManager, NodeManager vengono eseguiti sulla stessa macchina/host.
In una configurazione del cluster a nodo singolo, tutto viene eseguito su una singola istanza JVM. L'utente Hadoop non ha dovuto effettuare alcuna impostazione di configurazione, ad eccezione dell'impostazione della variabile JAVA_HOME.
Il fattore di replica predefinito per un cluster Hadoop a nodo singolo è sempre 1.
2. Cluster Hadoop multinodo
Il cluster Hadoop multinodo viene distribuito su più macchine. Tutti i demoni nel cluster Hadoop multinodo sono attivi ed eseguiti su macchine/host differenti.
Un cluster Hadoop multinodo segue l'architettura master-slave. I demoni Namenode e ResourceManager vengono eseguiti sui nodi master, che sono computer di fascia alta.
I demoni DataNodes e NodeManager vengono eseguiti sui nodi slave (nodi di lavoro), che sono hardware di fascia economica.
Nel cluster Hadoop multinodo, le macchine slave possono essere presenti in qualsiasi posizione, indipendentemente dalla posizione fisica del server master.
Protocolli di comunicazione utilizzati in Hadoop Cluster
I protocolli di comunicazione HDFS sono sovrapposti al protocollo TCP/IP. Un client stabilisce una connessione con il NameNode tramite la porta TCP configurabile sulla macchina NameNode.
Il cluster Hadoop stabilisce una connessione al client tramite ClientProtocol. Inoltre, il DataNode comunica con il NameNode utilizzando il protocollo DataNode.
L'astrazione Remote Procedure Call (RPC) avvolge il protocollo client e il protocollo DataNode. In base alla progettazione, NameNode non avvia alcun RPC. Risponde solo alle richieste RPC emesse da client o DataNode.
Migliori pratiche per la creazione di cluster Hadoop
Le prestazioni di un cluster Hadoop dipendono da vari fattori in base alle risorse hardware ben dimensionate che utilizzano CPU, memoria, larghezza di banda di rete, disco rigido e altri livelli software ben configurati.
Costruire un cluster Hadoop è un lavoro non banale. Richiede la considerazione di vari fattori come la scelta dell'hardware giusto, il dimensionamento dei cluster Hadoop e la configurazione del cluster Hadoop.
Vediamo ora ciascuno nel dettaglio.
1. Scegliere l'hardware giusto per il cluster Hadoop
Molte organizzazioni, quando configurano l'infrastruttura Hadoop, si trovano in una situazione difficile poiché non sono consapevoli del tipo di macchine che devono acquistare per configurare un ambiente Hadoop ottimizzato e della configurazione ideale che devono utilizzare.
Per scegliere l'hardware giusto per il cluster Hadoop, è necessario considerare i seguenti punti:
- Il volume di dati che il cluster gestirà.
- Il tipo di carichi di lavoro con cui dovrà gestire il cluster (limitato alla CPU, legato all'I/O).
- Metodologia di archiviazione dei dati come contenitori di dati, tecniche di compressione dei dati utilizzate, se presenti.
- Una politica di conservazione dei dati, ovvero per quanto tempo vogliamo conservare i dati prima di eliminarli.
2. Dimensionamento del cluster Hadoop
Per determinare la dimensione del cluster Hadoop, il volume di dati che gli utenti Hadoop elaboreranno sul cluster Hadoop dovrebbe essere una considerazione fondamentale.
Conoscendo il volume di dati da elaborare, aiuta a decidere quanti nodi saranno necessari per elaborare i dati in modo efficiente e la capacità di memoria richiesta per ciascun nodo. Dovrebbe esserci un equilibrio tra le prestazioni e il costo dell'hardware approvato.
3. Configurazione del cluster Hadoop
Trovare la configurazione ideale per il cluster Hadoop non è un lavoro facile. Il framework Hadoop deve essere adattato al cluster in esecuzione e anche al lavoro.
Il modo migliore per decidere la configurazione ideale per il cluster Hadoop è eseguire i lavori Hadoop con la configurazione predefinita disponibile per ottenere una baseline. Successivamente, possiamo analizzare i file di registro della cronologia dei lavori per vedere se ci sono risorse deboli o se il tempo impiegato per eseguire i lavori è maggiore del previsto.
In tal caso, modificare la configurazione. Ripetendo lo stesso processo è possibile ottimizzare la configurazione del cluster Hadoop che meglio si adatta ai requisiti aziendali.
Le prestazioni del cluster Hadoop dipendono molto dalle risorse allocate ai demoni. Per contesti di dati di piccole e medie dimensioni, Hadoop riserva un core CPU su ciascun DataNode, mentre, per i set di dati lunghi, alloca 2 core CPU su ciascun DataNode per i demoni HDFS e MapReduce.
Gestione del cluster Hadoop
Quando si implementa il cluster Hadoop in produzione, è evidente che dovrebbe scalare lungo tutte le dimensioni che sono volume, varietà e velocità.
Varie caratteristiche che dovrebbe possedere per essere pronto per la produzione sono:disponibilità 24 ore su 24, robustezza, gestibilità e prestazioni. La gestione dei cluster Hadoop è l'aspetto principale dell'iniziativa Big Data.
Il miglior strumento per la gestione dei cluster Hadoop dovrebbe avere le seguenti caratteristiche:-
- Deve garantire disponibilità elevata 24 ore su 24, 7 giorni su 7, fornitura di risorse, sicurezza diversificata, gestione del carico di lavoro, monitoraggio dello stato e ottimizzazione delle prestazioni. Inoltre, deve fornire pianificazione dei lavori, gestione dei criteri, backup e ripristino su uno o più nodi.
- Implementa l'elevata disponibilità HDFS NameNode ridondante con bilanciamento del carico, hot standby, risincronizzazione e failover automatico.
- Applicare controlli basati su criteri che impediscono a qualsiasi applicazione di acquisire una quota sproporzionata di risorse su un cluster Hadoop già al massimo.
- Esecuzione di test di regressione per la gestione della distribuzione di qualsiasi livello software su cluster Hadoop. Questo per garantire che qualsiasi lavoro o dato non subisca arresti anomali o colli di bottiglia nelle operazioni quotidiane.
Vantaggi del cluster Hadoop
I vari vantaggi forniti dal Cluster Hadoop sono:
1. Scalabile
I cluster Hadoop sono scalabili. Possiamo aggiungere qualsiasi numero di nodi al cluster Hadoop senza alcun tempo di inattività e senza sforzi aggiuntivi. Con ogni aggiunta di nodi, otteniamo un corrispondente aumento del throughput.
2. Robustezza
Il cluster Hadoop è noto soprattutto per il suo storage affidabile. Può archiviare i dati in modo affidabile, anche in casi come l'errore DataNode, l'errore NameNode e la partizione di rete. Il DataNode invia periodicamente un segnale di heartbeat al NameNode.
Nella partizione di rete, un set di DataNode viene staccato dal NameNode a causa del quale NameNode non riceve alcun heartbeat da questi DataNode. NameNode considera quindi questi DataNode come morti e non inoltra loro alcuna richiesta di I/O.
Inoltre, il fattore di replica dei blocchi archiviati in questi DataNode scende al di sotto del valore specificato. Di conseguenza, NameNode avvia quindi la replica di questi blocchi e si riprende dall'errore.
3. Ribilanciamento del cluster
L'architettura Hadoop HDFS esegue automaticamente il ribilanciamento del cluster. Se lo spazio libero nel DataNode scende al di sotto del livello di soglia, l'architettura HDFS sposta automaticamente alcuni dati in un altro DataNode dove è disponibile spazio sufficiente.
4. Economico
La configurazione del cluster Hadoop è conveniente perché comprende hardware di base poco costoso. Qualsiasi organizzazione può configurare facilmente un potente cluster Hadoop senza spendere molto per costosi hardware del server.
Inoltre, i cluster Hadoop con la sua topologia di archiviazione distribuita superano i limiti del sistema tradizionale. Lo spazio di archiviazione limitato può essere esteso semplicemente aggiungendo ulteriori unità di archiviazione economiche al sistema.
5. Flessibile
I cluster Hadoop sono altamente flessibili in quanto possono elaborare dati di qualsiasi tipo, strutturati, semi-strutturati o non strutturati e di qualsiasi dimensione, da Gigabyte a Petabyte.
6. Elaborazione rapida
In Hadoop Cluster, i dati possono essere elaborati parallelamente in un ambiente distribuito. Ciò fornisce capacità di elaborazione dati rapida a Hadoop. I cluster Hadoop possono elaborare terabyte o petabyte di dati in una frazione di secondi.
7. Integrità dei dati
Per verificare l'eventuale danneggiamento dei blocchi di dati a causa di software difettoso, guasti in un dispositivo di archiviazione, ecc., il cluster Hadoop implementa il checksum su ogni blocco del file. Se trova un blocco danneggiato, lo cerca da un altro DataNode che contiene la replica dello stesso blocco. Pertanto, il cluster Hadoop mantiene l'integrità dei dati.
Riepilogo
Dopo aver letto questo articolo, possiamo dire che Hadoop Cluster è uno speciale cluster computazionale progettato per l'analisi e la memorizzazione di big data. Il cluster Hadoop segue l'architettura master-slave.
Il nodo master è la macchina computer di fascia alta e i nodi slave sono macchine con normale configurazione di CPU e memoria. Abbiamo anche visto che il cluster Hadoop può essere configurato su una singola macchina chiamata cluster Hadoop a nodo singolo o su più macchine chiamate cluster Hadoop multinodo.
In questo articolo, abbiamo anche illustrato le migliori pratiche da seguire durante la creazione di un cluster Hadoop. Abbiamo anche riscontrato molti vantaggi del cluster Hadoop, tra cui scalabilità, flessibilità, rapporto costo-efficacia, ecc.



