La valutazione del pattern architetturale di streaming più adatto al tuo caso d'uso è un prerequisito per un'implementazione di produzione di successo.
L'ecosistema Apache Hadoop è diventato una piattaforma preferita per le aziende che cercano di elaborare e comprendere dati su larga scala in tempo reale. Tecnologie come Apache Kafka, Apache Flume, Apache Spark, Apache Storm e Apache Samza stanno spingendo sempre più oltre il possibile. Spesso si è tentati di raggruppare insieme casi d'uso di streaming su larga scala, ma in realtà tendono a scomporsi in alcuni modelli architetturali diversi, con diversi componenti dell'ecosistema più adatti a problemi diversi.
In questo post, illustrerò i quattro principali modelli di streaming che abbiamo riscontrato con i clienti che eseguono hub di dati aziendali in produzione e spiegherò come implementare tali modelli in modo architetturale su Hadoop.
Modelli di streaming
I quattro modelli di streaming di base (spesso usati in tandem) sono:
- Immissione di stream: Implica la persistenza a bassa latenza degli eventi su HDFS, Apache HBase e Apache Solr.
- Elaborazione di eventi Near Real-Time (NRT) con contesto esterno: Esegue azioni come avvisi, segnalazione, trasformazione e filtraggio degli eventi al loro arrivo. Le azioni potrebbero essere intraprese in base a criteri sofisticati, come i modelli di rilevamento delle anomalie. Casi d'uso comuni, come il rilevamento e la raccomandazione di frodi NRT, spesso richiedono basse latenze inferiori a 100 millisecondi.
- Elaborazione partizionata di eventi NRT: Simile all'elaborazione degli eventi NRT, ma trae vantaggi dal partizionamento dei dati, come la memorizzazione di informazioni esterne più rilevanti nella memoria. Questo modello richiede anche latenze di elaborazione inferiori a 100 millisecondi.
- Topologia complessa per aggregazioni o ML: Il Santo Graal dell'elaborazione dei flussi:ottiene risposte in tempo reale dai dati con una serie di operazioni complesse e flessibili. In questo caso, poiché i risultati spesso dipendono da calcoli in finestra e richiedono dati più attivi, l'attenzione si sposta da una latenza ultra bassa alla funzionalità e alla precisione.
Nelle sezioni seguenti, analizzeremo i modi consigliati per implementare tali modelli in modo testato, collaudato e gestibile.
Immissione in streaming
Tradizionalmente, Flume è stato il sistema consigliato per l'importazione in streaming. La sua ampia libreria di fonti e lavelli copre tutte le basi di cosa consumare e dove scrivere. (Per i dettagli su come configurare e gestire Flume, Utilizzo di Flume , il libro O'Reilly Media dell'ingegnere software Cloudera/membro di Flume PMC Hari Shreedharan, è un'ottima risorsa.)
Nell'ultimo anno, Kafka è diventato popolare anche grazie a potenti funzionalità come la riproduzione e la replica. A causa della sovrapposizione tra gli obiettivi di Flume e Kafka, la loro relazione è spesso confusa. Come si adattano? La risposta è semplice:Kafka è una pipa simile all'astrazione di Flume's Channel, anche se una pipa migliore grazie al suo supporto per le funzionalità sopra menzionate. Un approccio comune consiste nell'usare Flume per la sorgente e il pozzo e Kafka per il tubo tra di loro.
Il diagramma seguente illustra come Kafka può fungere da sorgente di dati a monte per Flume, destinazione a valle di Flume o canale Flume.
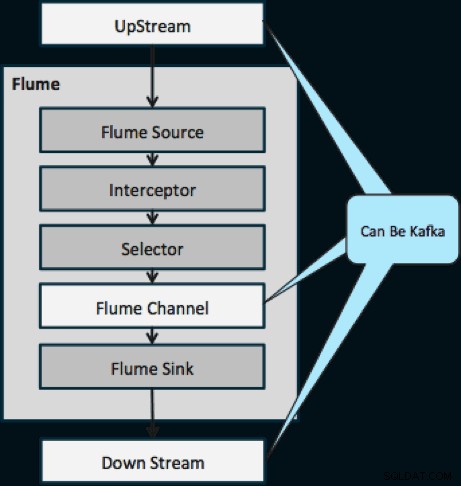
Il design illustrato di seguito è estremamente scalabile, resistente alla battaglia, monitorato centralmente tramite Cloudera Manager, tollerante ai guasti e supporta la riproduzione.
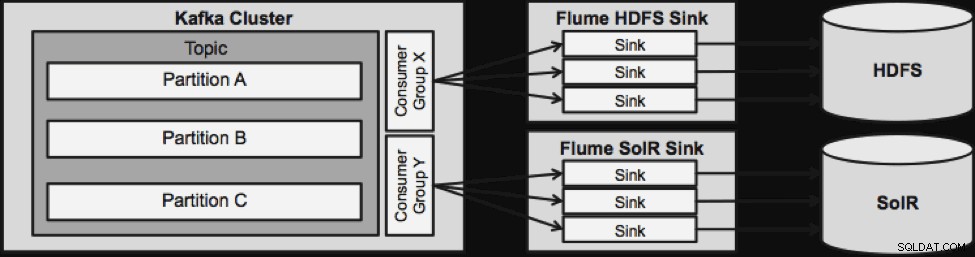
Una cosa da notare prima di passare alla prossima architettura di streaming è il modo in cui questo design gestisce con grazia i guasti. I lavelli Flume provengono da un gruppo di consumatori Kafka. Il gruppo dei consumatori tiene traccia dell'offset dell'argomento con l'aiuto di Apache ZooKeeper. In caso di smarrimento di un Flume Sink, il Kafka Consumer ridistribuirà il carico ai restanti lavelli. Quando il Flume Sink si riattiva, il gruppo Consumer si ridistribuirà nuovamente.
Elaborazione di eventi NRT con contesto esterno
Per ribadire, un caso d'uso comune per questo modello è guardare gli eventi in streaming e prendere decisioni immediate, sia per trasformare i dati sia per intraprendere una sorta di azione esterna. La logica decisionale dipende spesso da profili o metadati esterni. Un modo semplice e scalabile per implementare questo approccio consiste nell'aggiungere un intercettore Source o Sink Flume all'architettura Kafka/Flume. Con un'ottimizzazione modesta, non è difficile ottenere latenze di pochi millisecondi.
I Flume Interceptor accettano eventi o batch di eventi e consentono al codice utente di modificare o intraprendere azioni basate su di essi. Il codice utente può interagire con la memoria locale o un sistema di archiviazione esterno come HBase per ottenere le informazioni sul profilo necessarie per le decisioni. HBase di solito può fornirci le nostre informazioni in circa 4-25 millisecondi a seconda della rete, della progettazione dello schema e della configurazione. Puoi anche configurare HBase in modo che non venga mai interrotto o interrotto, anche in caso di guasto.
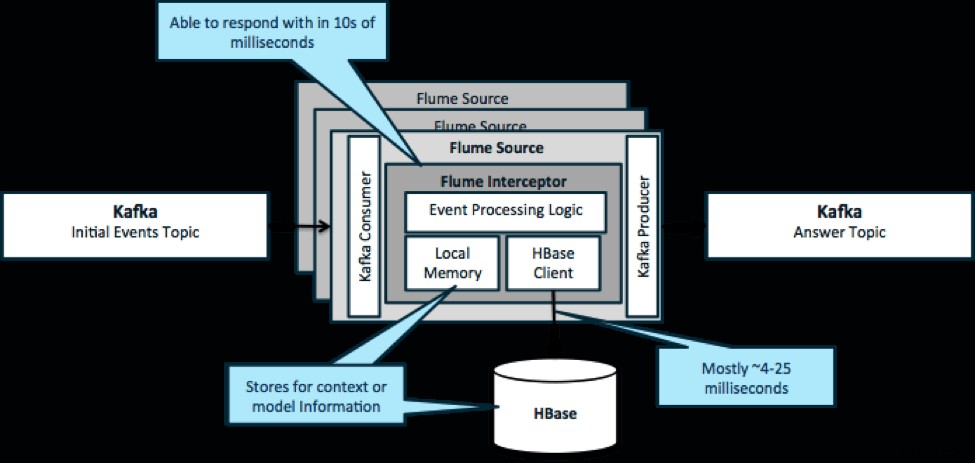
L'implementazione non richiede quasi nessuna codifica oltre alla logica specifica dell'applicazione nell'intercettore. Cloudera Manager offre un'interfaccia utente intuitiva per implementare questa logica tramite pacchetti, nonché per collegare, configurare e monitorare i servizi.
Elaborazione di eventi partizionati NRT con contesto esterno
Nell'architettura illustrata di seguito (soluzione non partizionata), dovresti chiamare frequentemente HBase perché il contesto esterno rilevante per eventi particolari non si adatta alla memoria locale sugli intercettori Flume.
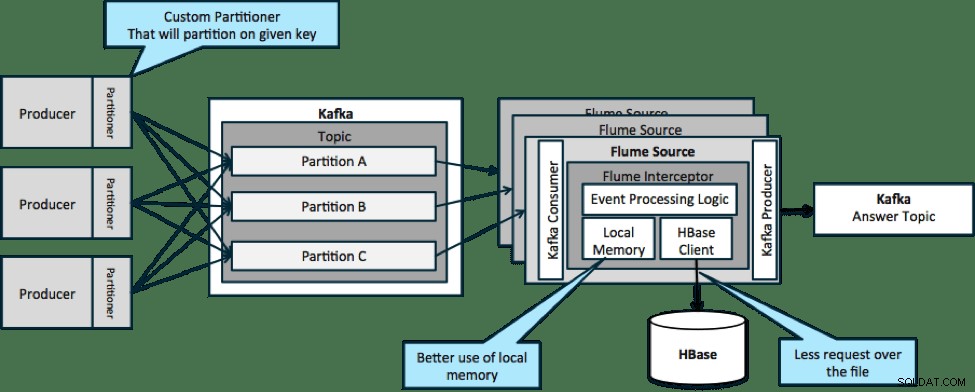
Tuttavia, se si definisce una chiave per partizionare i dati, è possibile abbinare i dati in ingresso al sottoinsieme dei dati di contesto che sono rilevanti per essi. Se si partizionano i dati 10 volte, è necessario mantenere solo 1/10 dei profili in memoria. HBase è veloce, ma la memoria locale è più veloce. Kafka ti consente di definire un partizionatore personalizzato che utilizza per dividere i tuoi dati.
Nota che Flume non è strettamente necessario qui; la soluzione principale qui solo un consumatore Kafka. Quindi, potresti utilizzare solo un consumatore in YARN o un'applicazione MapReduce solo mappa.
Topologia complessa per aggregazioni o ML
Fino a questo punto, abbiamo esplorato le operazioni a livello di evento. Tuttavia, a volte sono necessarie operazioni più complesse come conteggi, medie, sessioni o creazione di modelli di apprendimento automatico che operano su batch di dati. In questo caso, Spark Streaming è lo strumento ideale per diversi motivi:
- È facile da sviluppare rispetto ad altri strumenti. Le API ricche e concise di Spark semplificano la creazione di topologie complesse.
- Codice simile per lo streaming e l'elaborazione batch. Con poche modifiche, il codice per piccoli lotti in tempo reale può essere utilizzato offline per enormi lotti. Oltre a ridurre le dimensioni del codice, questo approccio riduce il tempo necessario per il test e l'integrazione.
- C'è un motore da sapere. C'è un costo che va nella formazione del personale sulle stranezze e gli interni dei motori di elaborazione distribuiti. La standardizzazione su Spark consolida questo costo sia per lo streaming che per il batch.
- Il micro-batching ti aiuta a scalare in modo affidabile. Il riconoscimento a livello di batch consente una maggiore velocità effettiva e consente soluzioni senza il timore di un doppio invio. Il micro-batching aiuta anche con l'invio di modifiche a HDFS o HBase in termini di prestazioni su larga scala.
- L'integrazione dell'ecosistema Hadoop è già iniziata. Spark ha una profonda integrazione con HDFS, HBase e Kafka.
- Nessun rischio di perdita di dati. Grazie a WAL e Kafka, Spark Streaming evita la perdita di dati in caso di guasto.
- È facile eseguire il debug e l'esecuzione. Puoi eseguire il debug e scorrere il tuo codice Spark Streaming in un IDE locale senza un cluster. Inoltre, il codice sembra un normale codice di programmazione funzionale, quindi non ci vuole molto tempo per uno sviluppatore Java o Scala per fare il salto. (È supportato anche Python.)
- Lo streaming è nativamente con stato. In Spark Streaming, lo stato è un cittadino di prima classe, il che significa che è facile scrivere applicazioni di streaming stateful che siano resilienti ai guasti dei nodi.
- Come standard de facto, Spark riceve investimenti a lungo termine da tutto l'ecosistema.
Al momento della stesura di questo articolo, negli ultimi 30 giorni c'erano circa 700 commit in totale per Spark, rispetto ad altri framework di streaming come Storm, con 15 commit nello stesso periodo. - Hai accesso alle librerie ML.
MLlib di Spark sta diventando estremamente popolare e le sue funzionalità non potranno che aumentare. - Puoi usare SQL dove necessario.
Con Spark SQL, puoi aggiungere la logica SQL alla tua applicazione di streaming per ridurre la complessità del codice.
Conclusione
C'è molta potenza nello streaming e diversi modelli possibili, ma come hai appreso in questo post, puoi fare cose davvero potenti con una codifica minima se sai quale modello si adatta meglio al tuo caso d'uso.
Ted Malaska è Solutions Architect presso Cloudera, collaboratore di Spark, Flume e HBase e coautore del libro O'Reilly, Architettura delle applicazioni Hadoop.



