Ottieni una panoramica dei meccanismi disponibili per il backup dei dati archiviati in Apache HBase e come ripristinare tali dati in caso di vari scenari di ripristino/failover dei dati
Con una maggiore adozione e integrazione di HBase nei sistemi aziendali critici, molte aziende devono proteggere questo importante asset aziendale sviluppando solide strategie di backup e ripristino di emergenza (BDR) per i propri cluster HBase. Per quanto possa sembrare scoraggiante eseguire rapidamente e facilmente il backup e il ripristino di potenzialmente petabyte di dati, HBase e l'ecosistema Apache Hadoop forniscono molti meccanismi integrati per ottenere proprio questo.
In questo post, otterrai una panoramica di alto livello dei meccanismi disponibili per il backup dei dati archiviati in HBase e come ripristinare tali dati in caso di vari scenari di ripristino/failover dei dati. Dopo aver letto questo post, dovresti essere in grado di prendere una decisione informata su quale strategia BDR è la migliore per le tue esigenze aziendali. Dovresti anche comprendere i pro, i contro e le implicazioni sulle prestazioni di ciascun meccanismo. (I dettagli qui riportati si applicano a CDH 4.3.0/HBase 0.94.6 e versioni successive.)
Nota:al momento della stesura di questo documento, Cloudera Enterprise 4 offre funzionalità di backup e ripristino di emergenza pronte per la produzione per HDFS e Hive Metastore tramite Cloudera BDR 1.0 come funzionalità con licenza individuale. HBase non è incluso in quella versione GA; pertanto, sono necessari i vari meccanismi descritti in questo blog. (Cloudera Enterprise 5, attualmente in versione beta, offre la gestione degli snapshot HBase tramite Cloudera BDR.)
Backup
HBase è un archivio dati distribuito con struttura ad albero di unione strutturato in log con complessi meccanismi interni per garantire l'accuratezza, la coerenza, il controllo delle versioni dei dati e così via. Quindi, come è possibile ottenere una copia di backup coerente di questi dati che risiedono in una combinazione di file H e WAL (Write-Ahead-Log) su HDFS e in memoria su dozzine di server regionali?
Cominciamo con il meno dirompente, il più piccolo ingombro di dati, il meccanismo meno impattante sulle prestazioni e procediamo fino allo strumento più dirompente in stile carrello elevatore:
- Istantanee
- Replica
- Esporta
- Copia tabella
- API di HTable
- Backup offline dei dati HDFS
La tabella seguente fornisce una panoramica per confrontare rapidamente questi approcci, che descriverò in dettaglio di seguito.
| Impatto sulle prestazioni | Impronta dati | Tempo di inattività | Backup incrementali | Facilità di implementazione | Mean Time To Recovery (MTTR) | |
| Istantanee | Minimo | Piccolo | Breve (solo durante il ripristino) | No | Facile | Secondi |
| Replica | Minimo | Grande | Nessuno | Intrinseco | Medio | Secondi |
| Esporta | Alto | Grande | Nessuno | Sì | Facile | Alto |
| Copia tabella | Alto | Grande | Nessuno | Sì | Facile | Alto |
| API | Medio | Grande | Nessuno | Sì | Difficile | A te |
| Manuale | N/A | Grande | Lungo | No | Medio | Alto |
Istantanee
A partire da CDH 4.3.0, gli snapshot HBase sono completamente funzionali, ricchi di funzionalità e non richiedono tempi di inattività del cluster durante la loro creazione. Il mio collega Matteo Bertozzi ha trattato molto bene le istantanee nel suo post sul blog e la successiva immersione profonda. Qui fornirò solo una panoramica di alto livello.
Le istantanee catturano semplicemente un momento per la tua tabella creando l'equivalente di collegamenti fisici UNIX ai file di archiviazione della tua tabella su HDFS (Figura 1). Questi snapshot vengono completati in pochi secondi, non comportano quasi alcun sovraccarico di prestazioni sul cluster e creano un'impronta di dati minuscola. I tuoi dati non vengono affatto duplicati, ma semplicemente catalogati in piccoli file di metadati, il che consente al sistema di tornare a quel momento nel caso in cui fosse necessario ripristinare quell'istantanea.
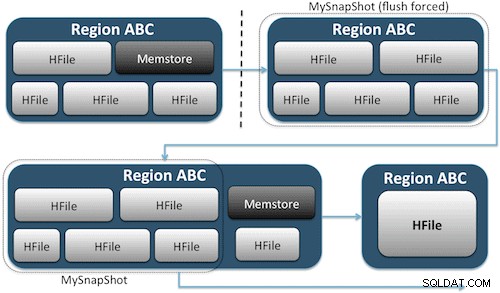
Creare uno snapshot di una tabella è semplice come eseguire questo comando dalla shell HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Dopo aver eseguito questo comando, troverai alcuni piccoli file di dati situati in /hbase/.snapshot/myTable (CDH4) o /hbase/.hbase-snapshots (Apache 0.94.6.1) in HDFS che contengono le informazioni necessarie per ripristinare lo snapshot . Il ripristino è semplice come eseguire questi comandi dalla shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Nota:come puoi vedere, il ripristino di uno snapshot richiede una breve interruzione poiché la tabella deve essere offline. Tutti i dati aggiunti/aggiornati dopo l'acquisizione dello snapshot ripristinato andranno persi.
Se i tuoi requisiti aziendali sono tali da richiedere un backup fuori sede dei tuoi dati, puoi utilizzare il comando exportSnapshot per duplicare i dati di una tabella nel tuo cluster HDFS locale o in un cluster HDFS remoto di tua scelta.
Le istantanee sono ogni volta un'immagine completa del tuo tavolo; al momento non è disponibile alcuna funzionalità di snapshot incrementale.
Replica HBase
La replica HBase è un altro strumento di backup con sovraccarico molto basso. (Il mio collega Himanshu Vashishtha tratta la replica in dettaglio in questo post del blog.) In sintesi, la replica può essere definita a livello di famiglia di colonne, funziona in background e mantiene tutte le modifiche sincronizzate tra i cluster nella catena di replica.
La replica ha tre modalità:master->slave, master<->master e ciclica. Questo approccio offre flessibilità per acquisire dati da qualsiasi data center e garantisce che vengano replicati su tutte le copie di quella tabella in altri data center. In caso di un'interruzione catastrofica in un data center, le applicazioni client possono essere reindirizzate a una posizione alternativa per i dati utilizzando gli strumenti DNS.
La replica è un processo robusto e tollerante ai guasti che fornisce "coerenza finale", il che significa che in qualsiasi momento le modifiche recenti a una tabella potrebbero non essere disponibili in tutte le repliche di quella tabella, ma è garantito che alla fine ci arriveranno.
Nota:per le tabelle esistenti, devi prima copiare manualmente la tabella di origine nella tabella di destinazione tramite uno degli altri mezzi descritti in questo post. La replica agisce solo su nuove scritture/modifiche dopo averla abilitata.

(dalla pagina Replica di Apache)
Esporta
Lo strumento Export di HBase è un'utilità HBase integrata che consente di esportare facilmente i dati da una tabella HBase a semplici SequenceFiles in una directory HDFS. Crea un processo MapReduce che effettua una serie di chiamate API HBase al tuo cluster e, una per una, ottiene ogni riga di dati dalla tabella specificata e scrive tali dati nella directory HDFS specificata. Questo strumento richiede più prestazioni per il tuo cluster perché utilizza MapReduce e l'API client HBase, ma è ricco di funzionalità e supporta il filtraggio dei dati per versione o intervallo di date, consentendo così backup incrementali.
Ecco un esempio del comando nella sua forma più semplice:
hbase org.apache.hadoop.hbase.mapreduce.Export
Una volta esportata la tabella, puoi copiare i file di dati risultanti ovunque desideri (ad esempio archiviazione fuori sede/fuori cluster). Puoi anche specificare un cluster/directory HDFS remoto come posizione di output del comando e Export scriverà direttamente il contenuto nel cluster remoto. Tieni presente che questo approccio introdurrà un elemento di rete nel percorso di scrittura dell'esportazione, quindi dovresti confermare che la tua connessione di rete al cluster remoto è affidabile e veloce.
Copia tabella
L'utilità CopyTable è trattata bene nel post del blog di Jon Hsieh, ma riassumerò qui le basi. Simile a Export, CopyTable crea un lavoro MapReduce che utilizza l'API HBase per leggere da una tabella di origine. La differenza fondamentale è che CopyTable scrive il suo output direttamente in una tabella di destinazione in HBase, che può essere locale al tuo cluster di origine o su un cluster remoto.
Un esempio della forma più semplice del comando è:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Questo comando copierà il contenuto di una tabella denominata "test" in una tabella nello stesso cluster denominata "testCopy".
Si noti che CopyTable comporta un sovraccarico di prestazioni significativo in quanto utilizza singoli "put" per scrivere i dati, riga per riga, nella tabella di destinazione. Se la tua tabella è molto grande, CopyTable potrebbe causare il riempimento del memstore sui server della regione di destinazione, richiedendo svuotamenti del memstore che alla fine porteranno a compattazioni, garbage collection e così via.
Inoltre, è necessario prendere in considerazione le implicazioni sulle prestazioni dell'esecuzione di MapReduce su HBase. Con set di dati di grandi dimensioni, questo approccio potrebbe non essere l'ideale.
API HTable (come un'applicazione Java personalizzata)
Come sempre con Hadoop, puoi sempre scrivere la tua applicazione personalizzata che utilizza l'API pubblica e interroga direttamente la tabella. Puoi farlo tramite i lavori MapReduce per utilizzare i vantaggi dell'elaborazione batch distribuita di quel framework o tramite qualsiasi altro mezzo di tua progettazione. Tuttavia, questo approccio richiede una conoscenza approfondita dello sviluppo di Hadoop e di tutte le API e le implicazioni sulle prestazioni dell'utilizzo nel cluster di produzione.
Backup offline di dati HDFS grezzi
Il meccanismo di backup più brutale, anche quello più dirompente, comporta l'impronta di dati più ampia. Puoi arrestare in modo pulito il tuo cluster HBase e copiare manualmente tutti i dati e le strutture di directory che risiedono in /hbase nel tuo cluster HDFS. Poiché HBase è inattivo, ciò assicurerà che tutti i dati siano stati mantenuti negli HFiles in HDFS e otterrai una copia accurata dei dati. Tuttavia, sarà quasi impossibile ottenere backup incrementali poiché non sarai in grado di accertare quali dati sono stati modificati o aggiunti durante i tentativi di backup futuri.
È anche importante notare che il ripristino dei dati richiederebbe una riparazione del meta offline perché il file .META. la tabella conterrebbe informazioni potenzialmente non valide al momento del ripristino. Questo approccio richiede anche una rete veloce e affidabile per trasferire i dati fuori sede e ripristinarli in seguito, se necessario.
Per questi motivi, Cloudera sconsiglia vivamente questo approccio ai backup HBase.
Ripristino di emergenza
HBase è progettato per essere un sistema distribuito estremamente tollerante ai guasti con ridondanza nativa, presupponendo che l'hardware si guasti frequentemente. Il ripristino di emergenza in HBase di solito si presenta in diverse forme:
- Errore catastrofico a livello di data center, che richiede il failover in una posizione di backup
- Necessità di ripristinare una copia precedente dei tuoi dati a causa di un errore dell'utente o di un'eliminazione accidentale
- La possibilità di ripristinare una copia puntuale dei tuoi dati a fini di controllo
Come per qualsiasi piano di ripristino di emergenza, i requisiti aziendali determineranno l'architettura del piano e la quantità di denaro da investire in esso. Una volta stabiliti i backup di tua scelta, il ripristino assume forme diverse a seconda del tipo di ripristino richiesto:
- Failover per il backup del cluster
- Importa tabella/Ripristina uno snapshot
- Punta la directory principale di HBase nella posizione di backup
Se la tua strategia di backup è tale da aver replicato i tuoi dati HBase su un cluster di backup in un data center diverso, il failover è facile come indirizzare le tue applicazioni dell'utente finale al cluster di backup con tecniche DNS.
Tieni presente, tuttavia, che se prevedi di consentire la scrittura dei dati nel cluster di backup durante il periodo di interruzione, dovrai assicurarti che i dati tornino al cluster principale al termine dell'interruzione. La replica da master a master o ciclica gestirà questo processo automaticamente per te, ma uno schema di replica master-slave lascerà il tuo cluster master non sincronizzato, richiedendo un intervento manuale dopo l'interruzione.
Insieme alla funzione Esporta descritta in precedenza, esiste uno strumento di importazione corrispondente che può prendere i dati precedentemente sottoposti a backup da Export e ripristinarli in una tabella HBase. Le stesse implicazioni sulle prestazioni applicate all'esportazione sono in gioco anche con l'importazione. Se il tuo schema di backup prevedeva l'acquisizione di istantanee, tornare a una copia precedente dei tuoi dati è semplice come ripristinare quella snapshot.
Puoi anche recuperare da un disastro semplicemente modificando la proprietà hbase.root.dir in hbase-site.xml e puntandola a una copia di backup della tua directory /hbase se hai eseguito la copia offline a forza bruta delle strutture di dati HDFS . Tuttavia, questa è anche l'opzione di ripristino meno desiderabile in quanto richiede un'interruzione prolungata durante la copia dell'intera struttura dati nel cluster di produzione e, come accennato in precedenza, .META. potrebbe non essere sincronizzato.
Conclusione
In sintesi, il recupero dei dati dopo una qualche forma di perdita o interruzione richiede un piano BDR ben progettato. Consiglio vivamente di comprendere a fondo i requisiti aziendali in termini di tempo di attività, accuratezza/disponibilità dei dati e ripristino di emergenza. Grazie a una conoscenza dettagliata delle tue esigenze aziendali, puoi scegliere con cura gli strumenti che meglio soddisfano tali esigenze.
Tuttavia, la selezione degli strumenti è solo l'inizio. Dovresti eseguire test su larga scala della tua strategia BDR per assicurarti che funzioni funzionalmente nella tua infrastruttura, soddisfi le tue esigenze aziendali e che i tuoi team operativi abbiano molta familiarità con i passaggi necessari prima che si verifichi un'interruzione e tu scopra a proprie spese che il tuo piano BDR non funzionerà.
Se desideri commentare o discutere ulteriormente questo argomento, utilizza il nostro forum della community per HBase.
Ulteriori letture:
- Presentazione Strata + Hadoop World 2012 di Jon Hsieh
- HBase:la guida definitiva (Lars George)
- HBase in azione (Nick Dimiduk/Amandeep Khurana)



