Finora abbiamo trattato l'introduzione di Hadoop e Hadoop HDFS in dettaglio. In questo tutorial, ti forniremo una descrizione dettagliata di Hadoop Reducer.
Qui si discuterà cos'è Reducer in MapReduce, come funziona Reducer in Hadoop MapReduce, diverse fasi di Hadoop Reducer, come possiamo modificare il numero di Reducer in Hadoop MapReduce.
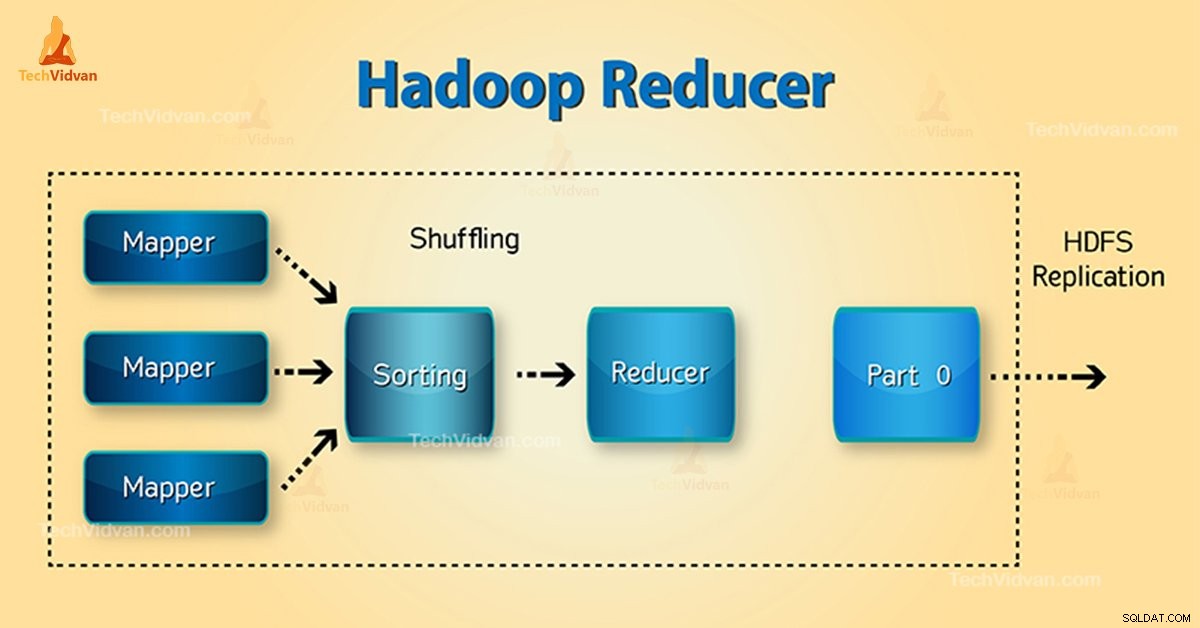
Cos'è Hadoop Reducer?
Riduttore in Hadoop MapReduce riduce un insieme di valori intermedi che condividono una chiave per un insieme più piccolo di valori.
Nel flusso di esecuzione dei lavori di MapReduce, Reducer prende un insieme di una coppia chiave-valore intermedia prodotto dal mapper come input. Quindi, Reducer aggrega, filtra e combina coppie chiave-valore e ciò richiede un'ampia gamma di elaborazioni.
La mappatura one-one avviene tra chiavi e riduttori nell'esecuzione del lavoro MapReduce. Corrono in parallelo poiché sono indipendenti l'uno dall'altro. L'utente decide il numero di riduttori in MapReduce.
Fasi di Hadoop Reducer
Le tre fasi di Reducer sono le seguenti:
1. Fase di mescolamento
Questa è la fase in cui l'output ordinato dal mapper è l'input del riduttore. Il framework con l'aiuto di HTTP recupera la partizione rilevante dell'output di tutti i mappatori in questa fase.Fase di ordinamento
2. Fase di ordinamento
Questa è la fase in cui l'input di diversi mappatori viene nuovamente ordinato in base alle chiavi simili in diversi mappatori.
Sia Shuffle che Sort si verificano contemporaneamente.
3. Riduci la fase
Questa fase si verifica dopo la mescolatura e l'ordinamento. Riduci attività aggrega le coppie chiave-valore. Con OutputCollector.collect() proprietà, l'output dell'attività di riduzione viene scritto nel FileSystem. L'uscita del riduttore non è ordinata.
Numero di riduttori in Hadoop MapReduce
L'utente imposta il numero di riduttori con l'aiuto di Job.setNumreduceTasks(int) proprietà. Quindi il giusto numero di riduttori dalla formula:
0,95 o 1,75 moltiplicato per (
Quindi, con 0,95, tutti i riduttori si avviano immediatamente. Quindi, inizia a trasferire gli output delle mappe al termine delle mappe.
Il nodo più veloce termina il primo round di riduttori con 1,75. Quindi lancia la seconda ondata di riduttore che fa un lavoro molto migliore di bilanciamento del carico.
Con l'aumento del numero dei riduttori:
- Le spese generali del quadro aumentano.
- Il bilanciamento del carico aumenta.
- Il costo dei guasti diminuisce.
Conclusione
Quindi, Reducer prende come input l'output dei mappatori. Quindi, elabora le coppie chiave-valore e produce l'output. L'uscita del riduttore è l'uscita finale. Se ti piace questo blog o hai qualche domanda relativa a Hadoop Reducer, condividi con noi lasciando un commento.
Spero che ti aiuteremo.



