In questo blog, ti forniremo l'introduzione completa di Hadoop Mapper . Io
In questo blog, risponderemo a cos'è Mapper in Hadoop MapReduce, come funziona hadoop mapper, quali sono i processi di mapper in Mapreduce, come Hadoop genera la coppia chiave-valore in MapReduce.
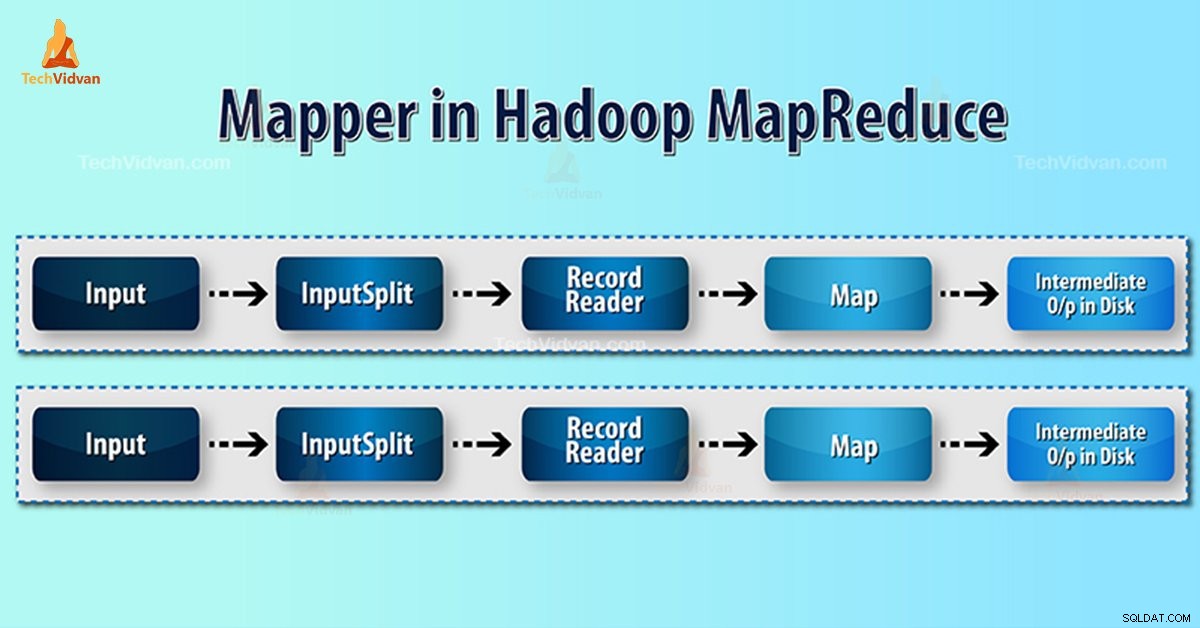
Introduzione a Hadoop Mapper
Mappa Hadoop elabora il record di input prodotto dal RecordReader e genera coppie chiave-valore intermedie. L'uscita intermedia è completamente diversa dalla coppia di ingressi.
L'output del mapper è la raccolta completa di coppie chiave-valore. Prima di scrivere l'output per ogni attività di mappatura, il partizionamento dell'output avviene in base alla chiave. Pertanto, il partizionamento specifica che tutti i valori per ciascuna chiave sono raggruppati insieme.
Hadoop MapReduce genera un'attività mappa per ogni InputSplit.
Hadoop MapReduce comprende solo coppie di dati valore-chiave. Quindi, prima di inviare i dati al mappatore, il framework Hadoop dovrebbe convertire i dati nella coppia chiave-valore.
Come viene generata la coppia chiave-valore in Hadoop?
Poiché abbiamo capito cos'è il mapper in hadoop, ora discuteremo di come Hadoop genera una coppia chiave-valore?
- InputSplit – È la rappresentazione logica dei dati generati da InputFormat. Nel programma MapReduce, descrive un'unità di lavoro che contiene una singola attività mappa.
- RecordReader- Comunica con l'inputSplit. E poi converte i dati in coppie chiave-valore adatte alla lettura da parte del Mapper. RecordReader per impostazione predefinita utilizza TextInputFormat per convertire i dati nella coppia chiave-valore.
Processo di mappatura in Hadoop MapReduce
InputSplit converte la rappresentazione fisica dei blocchi in logica per il Mapper. Ad esempio, per leggere il file da 100 MB, saranno necessari 2 InputSplit. Per ogni blocco, il framework crea un InputSplit. Ogni InputSplit crea un mappatore.
MapReduce InputSplit non dipende sempre dal numero di blocchi di dati . Possiamo modificare il numero di una divisione impostando la proprietà mapred.max.split.size durante l'esecuzione del lavoro.
MapReduce RecordReader è responsabile della lettura/conversione dei dati in coppie chiave-valore fino alla fine del file. RecordReader assegna Byte offset a ciascuna riga presente nel file.
Quindi Mapper riceve questa coppia di chiavi. Mapper produce l'output intermedio (coppie chiave-valore comprensibili da ridurre).
Quante attività sulla mappa in Hadoop?
Il numero di attività mappa dipende dal numero totale di blocchi dei file di input. Nella mappa MapReduce, il giusto livello di parallelismo sembra essere di circa 10-100 mappe/nodo. Ma ci sono 300 mappe per le attività della mappa leggera della CPU.
Ad esempio, abbiamo una dimensione del blocco di 128 MB. E ci aspettiamo 10 TB di dati di input. Così produce 82.000 mappe. Quindi il numero di mappe dipende da InputFormat.
Mapper =(dimensione totale dei dati)/ (dimensione suddivisa di input)
Esempio – la dimensione dei dati è 1 TB. La dimensione della divisione di input è 100 MB.
Mappatore =(1000*1000)/100 =10.000
Conclusione
Quindi, Mapper in Hadoop prende un insieme di dati e lo converte in un altro insieme di dati. Pertanto, suddivide i singoli elementi in tuple (coppie chiave/valore).
Spero che questo blocco ti piaccia, se hai qualche domanda per il mappatore Hadoop, quindi per favore lascia un commento in una sezione indicata di seguito. Saremo felici di risolverli.



