Come vorresti unire il processo "top" per tutti i tuoi 5 nodi di database e ordinare in base all'utilizzo della CPU con un solo comando di linea? Sì, avete letto bene! Che ne dici dei grafici interattivi visualizzati nell'interfaccia del terminale? Abbiamo introdotto il client CLI per ClusterControl chiamato s9s circa un anno fa, ed è stato un ottimo complemento all'interfaccia web. È anche open source..
In questo post del blog, ti mostreremo come monitorare i tuoi database utilizzando il tuo terminale e la CLI di s9s.
Introduzione a s9s, ClusterControl CLI
ClusterControl CLI (o s9s o s9s CLI), è un progetto open source e un pacchetto opzionale introdotto con ClusterControl versione 1.4.1. È uno strumento a riga di comando per interagire, controllare e gestire l'infrastruttura del database utilizzando ClusterControl. Il progetto della riga di comando di s9s è open source e può essere trovato su GitHub.
A partire dalla versione 1.4.1, lo script di installazione installerà automaticamente il pacchetto (s9s-tools) sul nodo ClusterControl.
Alcuni prerequisiti. Per poter eseguire s9s-tools CLI, deve essere vero quanto segue:
- Un ClusterControl Controller in esecuzione (cmon).
- Client s9s, installa come pacchetto separato.
- La porta 9501 deve essere raggiungibile dal client s9s.
L'installazione della CLI s9s è semplice se la si installa sull'host ClusterControl Controller stesso:$ rm
$ rm -Rf ~/.s9s
$ wget https://repo.severalnines.com/s9s-tools/install-s9s-tools.sh
$ ./install-s9s-tools.shÈ possibile installare s9s-tools al di fuori del server ClusterControl (la propria workstation laptop o bastion host), purché l'interfaccia ClusterControl Controller RPC (TLS) sia esposta alla rete pubblica (impostazione predefinita 127.0.0.1:9501). Puoi trovare maggiori dettagli su come configurarlo nella pagina della documentazione.
Per verificare se è possibile connettersi correttamente all'interfaccia ClusterControl RPC, è necessario ottenere la risposta OK durante l'esecuzione del comando seguente:
$ s9s cluster --ping
PING OK 2.000 msCome nota a margine, guarda anche le limitazioni quando usi questo strumento.
Esempio di distribuzione
La nostra distribuzione di esempio è composta da 8 nodi in 3 cluster:
- Replica in streaming PostgreSQL:1 master, 2 slave
- Replica MySQL - 1 master, 1 slave
- Set di repliche MongoDB:1 nodo primario, 2 nodi secondari
Tutti i cluster di database sono stati distribuiti da ClusterControl utilizzando la procedura guidata di distribuzione "Distribuisci cluster di database" e dal punto di vista dell'interfaccia utente, questo è ciò che vedremmo nella dashboard del cluster:
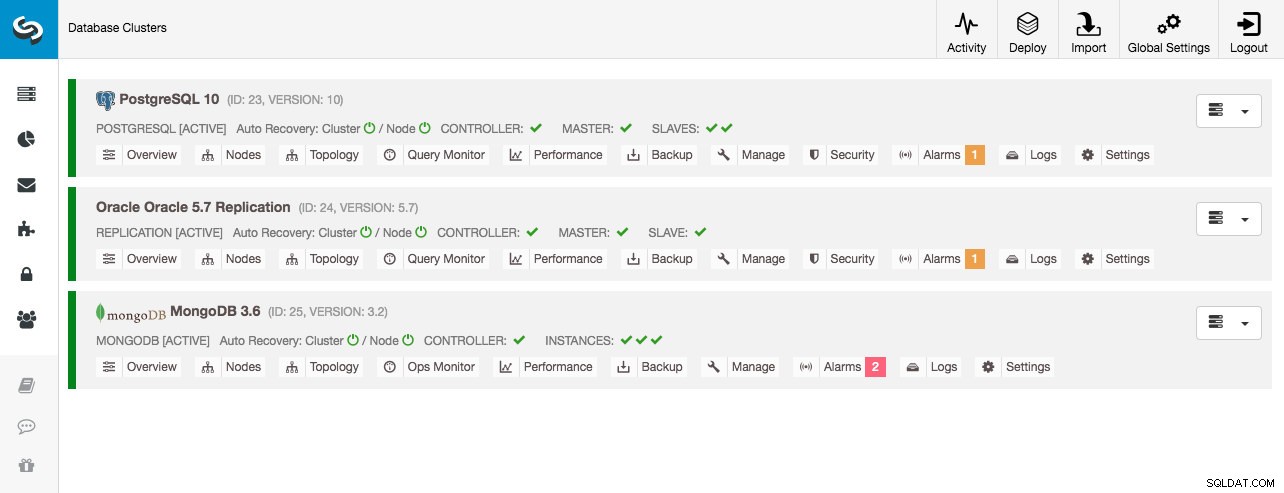
Monitoraggio cluster
Inizieremo elencando i cluster:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
23 STARTED postgresql_single system admins PostgreSQL 10 All nodes are operational.
24 STARTED replication system admins Oracle 5.7 Replication All nodes are operational.
25 STARTED mongodb system admins MongoDB 3.6 All nodes are operational.Vediamo gli stessi cluster dell'interfaccia utente. Possiamo ottenere maggiori dettagli sul particolare cluster usando il flag --stat. In questo modo è anche possibile monitorare più cluster e nodi, le opzioni della riga di comando possono persino utilizzare caratteri jolly nei nomi dei nodi e dei cluster:
$ s9s cluster --stat *Replication
Oracle 5.7 Replication Name: Oracle 5.7 Replication Owner: system/admins
ID: 24 State: STARTED
Type: REPLICATION Vendor: oracle 5.7
Status: All nodes are operational.
Alarms: 0 crit 1 warn
Jobs: 0 abort 0 defnd 0 dequd 0 faild 7 finsd 0 runng
Config: '/etc/cmon.d/cmon_24.cnf'
LogFile: '/var/log/cmon_24.log'
HOSTNAME CPU MEMORY SWAP DISK NICs
10.0.0.104 1 6% 992M 120M 0B 0B 19G 13G 10K/s 54K/s
10.0.0.168 1 6% 992M 116M 0B 0B 19G 13G 11K/s 66K/s
10.0.0.156 2 39% 3.6G 2.4G 0B 0B 19G 3.3G 338K/s 79K/sL'output sopra fornisce un riepilogo della nostra replica MySQL insieme allo stato del cluster, allo stato, al fornitore, al file di configurazione e così via. In fondo alla riga, puoi vedere l'elenco dei nodi che rientrano in questo ID cluster con una vista riepilogativa delle risorse di sistema per ciascun host come il numero di CPU, la memoria totale, l'utilizzo della memoria, il disco di scambio e le interfacce di rete. Tutte le informazioni visualizzate vengono recuperate dal database CMON, non direttamente dai nodi effettivi.
Puoi anche ottenere una vista riepilogativa di tutti i database su tutti i cluster:
$ s9s cluster --list-databases --long
SIZE #TBL #ROWS OWNER GROUP CLUSTER DATABASE
7,340,032 0 0 system admins PostgreSQL 10 postgres
7,340,032 0 0 system admins PostgreSQL 10 template1
7,340,032 0 0 system admins PostgreSQL 10 template0
765,460,480 24 2,399,611 system admins PostgreSQL 10 sbtest
0 101 - system admins Oracle 5.7 Replication sys
Total: 5 databases, 789,577,728, 125 tables.L'ultima riga riassume che abbiamo un totale di 5 database con 125 tabelle, 4 delle quali sono nel nostro cluster PostgreSQL.
Per un esempio completo di utilizzo delle opzioni della riga di comando del cluster s9s, consulta la documentazione del cluster s9s.
Monitoraggio dei nodi
Per il monitoraggio dei nodi, la CLI di s9s ha caratteristiche simili con l'opzione cluster. Per ottenere una vista riepilogativa di tutti i nodi, puoi semplicemente fare:
$ s9s node --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.6.2.2662 23 PostgreSQL 10 10.0.0.156 9500 Up and running
poM- 10.4 23 PostgreSQL 10 10.0.0.44 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.58 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.60 5432 Up and running
soS- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.104 3306 Up and running.
coC- 1.6.2.2662 24 Oracle 5.7 Replication 10.0.0.156 9500 Up and running
soM- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.168 3306 Up and running.
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.125 27017 Up and Running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.131 27017 Up and Running
coC- 1.6.2.2662 25 MongoDB 3.6 10.0.0.156 9500 Up and running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.35 27017 Up and Running
Total: 11La colonna più a sinistra specifica il tipo di nodo. Per questa distribuzione, "c" rappresenta ClusterControl Controller, "p" per PostgreSQL, "m" per MongoDB, "e" per Memcached e s per nodi MySQL generici. Il prossimo è lo stato dell'host - "o" per online, " l" per off-line, "f" per nodi guasti e così via. Il prossimo è il ruolo del nodo nel cluster. Può essere M per master, S per slave, C per controller e - per tutto il resto. Le colonne rimanenti sono piuttosto autoesplicative.
Puoi ottenere tutto l'elenco guardando la pagina man di questo componente:
$ man s9s-nodeDa lì, possiamo passare a statistiche più dettagliate per tutti i nodi con --stats flag:
$ s9s node --stat --cluster-id=24
10.0.0.104:3306
Name: 10.0.0.104 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.104 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: slave
OS: centos 7.0.1406 core Access: read-only
VM ID: -
Version: 5.7.23-log
Message: Up and running.
LastSeen: Just now SSH: 0 fail(s)
Connect: y Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 16592 Uptime: 01:44:38
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.168:3306
Name: 10.0.0.168 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.168 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: master
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 5.7.23-log
Message: Up and running.
Slaves: 10.0.0.104:3306
LastSeen: Just now SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 975 Uptime: 01:52:53
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.156:9500
Name: 10.0.0.156 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.156 Port: 9500
Alias: - Owner: system/admins
Class: CmonHost Type: controller
Status: CmonHostOnline Role: controller
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 1.6.2.2662
Message: Up and running
LastSeen: 28 seconds ago SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: n SuperReadOnly: n
Pid: 12746 Uptime: 01:10:05
Config: ''
LogFile: '/var/log/cmon_24.log'
PidFile: ''
DataDir: ''Anche la stampa di grafici con il client s9s può essere molto istruttiva. Presenta i dati raccolti dal titolare in vari grafici. Ci sono quasi 30 grafici supportati da questo strumento come elencato qui e s9s-node li enumera tutti. Di seguito viene mostrato l'istogramma di caricamento del server di tutti i nodi per l'ID cluster 1 raccolto da CMON, direttamente dal tuo terminale:
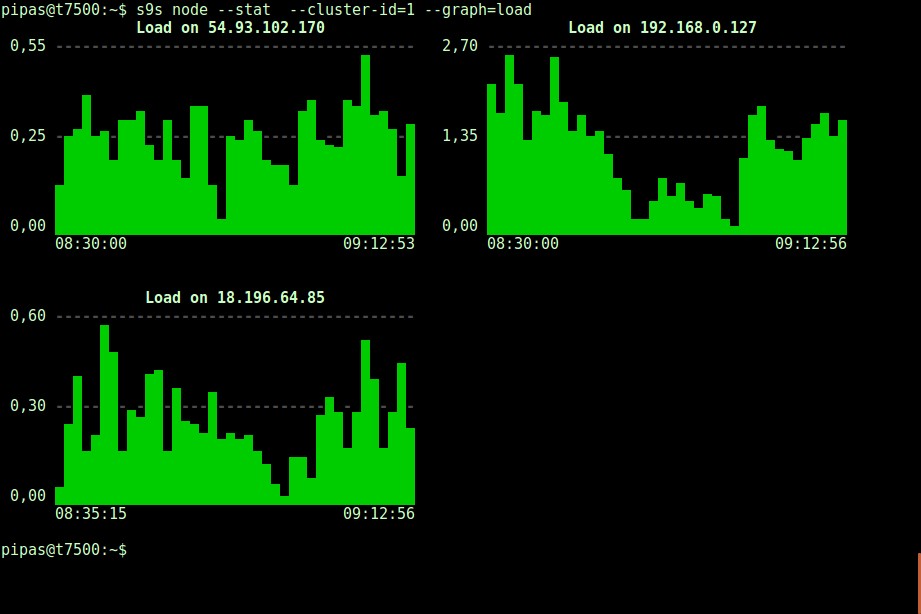
È possibile impostare la data e l'ora di inizio e fine. Si possono visualizzare periodi brevi (come l'ultima ora) o periodi più lunghi (come una settimana o un mese). Di seguito è riportato un esempio di visualizzazione dell'utilizzo del disco nell'ultima ora:
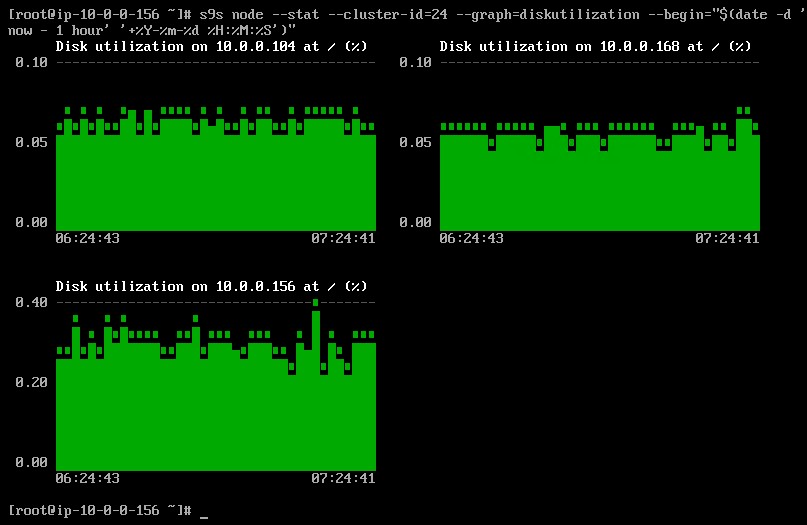
Usando l'opzione --density, è possibile stampare una vista diversa per ogni grafico. Questo grafico della densità non mostra le serie temporali, ma la frequenza con cui sono stati visualizzati i valori forniti (l'asse X rappresenta il valore della densità):
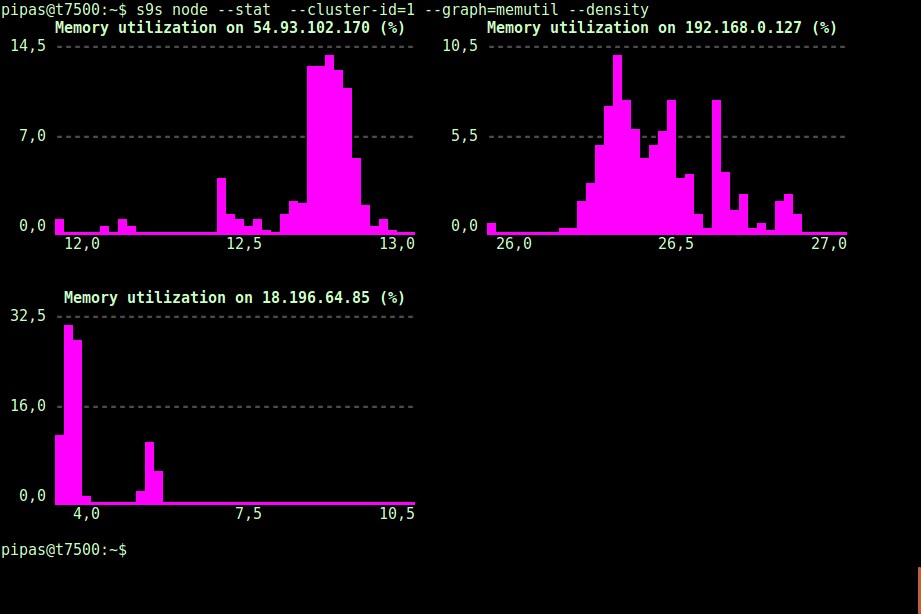
Se il terminale non supporta i caratteri Unicode, l'opzione --only-ascii può disattivarli:
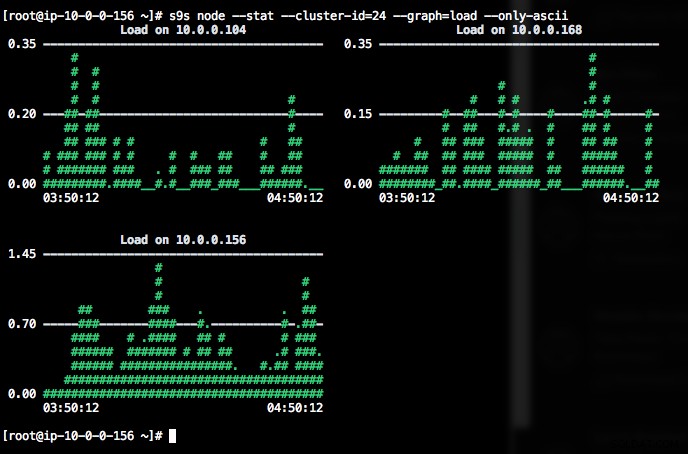
I grafici hanno dei colori, dove ad esempio valori pericolosamente alti sono mostrati in rosso. L'elenco dei nodi può essere filtrato con l'opzione --nodes, in cui puoi specificare i nomi dei nodi o utilizzare i caratteri jolly se conveniente.
Monitoraggio del processo
Un'altra cosa interessante della CLI di s9s è che fornisce un elenco di processi dell'intero cluster:un "top" per tutti i nodi, tutti i processi uniti in uno. Il comando seguente esegue il comando "top" su tutti i nodi del database per l'ID cluster 24, ordinato per il maggior consumo di CPU e aggiornato continuamente:
$ s9s process --top --cluster-id=24
Oracle 5.7 Replication - 04:39:17 All nodes are operational.
3 hosts, 4 cores, 10.6 us, 4.2 sy, 84.6 id, 0.1 wa, 0.3 st,
GiB Mem : 5.5 total, 1.7 free, 2.6 used, 0.1 buffers, 1.1 cached
GiB Swap: 0 total, 0 used, 0 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
12746 root 10.0.0.156 20 1359348 58976 S 25.25 1.56 cmon
1587 apache 10.0.0.156 20 462572 21632 S 1.38 0.57 httpd
390 root 10.0.0.156 20 4356 584 S 1.32 0.02 rngd
975 mysql 10.0.0.168 20 1144260 71936 S 1.11 7.08 mysqld
16592 mysql 10.0.0.104 20 1144808 75976 S 1.11 7.48 mysqld
22983 root 10.0.0.104 20 127368 5308 S 0.92 0.52 sshd
22548 root 10.0.0.168 20 127368 5304 S 0.83 0.52 sshd
1632 mysql 10.0.0.156 20 3578232 1803336 S 0.50 47.65 mysqld
470 proxysql 10.0.0.156 20 167956 35300 S 0.44 0.93 proxysql
338 root 10.0.0.104 20 4304 600 S 0.37 0.06 rngd
351 root 10.0.0.168 20 4304 600 R 0.28 0.06 rngd
24 root 10.0.0.156 20 0 0 S 0.19 0.00 rcu_sched
785 root 10.0.0.156 20 454112 11092 S 0.13 0.29 httpd
26 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/1
25 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/0
22498 root 10.0.0.168 20 127368 5200 S 0.09 0.51 sshd
14538 root 10.0.0.104 20 0 0 S 0.09 0.00 kworker/0:1
22933 root 10.0.0.104 20 127368 5200 S 0.09 0.51 sshd
28295 root 10.0.0.156 20 127452 5016 S 0.06 0.13 sshd
2238 root 10.0.0.156 20 197520 10444 S 0.06 0.28 vc-agent-007
419 root 10.0.0.156 20 34764 1660 S 0.06 0.04 systemd-logind
1 root 10.0.0.156 20 47628 3560 S 0.06 0.09 systemd
27992 proxysql 10.0.0.156 20 11688 872 S 0.00 0.02 proxysql_galera
28036 proxysql 10.0.0.156 20 11688 876 S 0.00 0.02 proxysql_galeraC'è anche un flag --list che restituisce un risultato simile senza aggiornamento continuo (simile al comando "ps"):
$ s9s process --list --cluster-id=25Monitoraggio del lavoro
I lavori sono attività eseguite dal controller in background, in modo che l'applicazione client non debba attendere il completamento dell'intero lavoro. ClusterControl esegue le attività di gestione assegnando un ID a ciascuna attività e consente allo scheduler interno di decidere se è possibile eseguire due o più lavori in parallelo. Ad esempio, è possibile eseguire più di una distribuzione del cluster contemporaneamente, così come altre operazioni di lunga durata come il backup e il caricamento automatico dei backup nell'archivio cloud.
In qualsiasi operazione di gestione, sarebbe utile poter monitorare l'avanzamento e lo stato di un lavoro specifico, ad esempio scalare un nuovo slave per la nostra replica MySQL. Il comando seguente aggiunge un nuovo slave, 10.0.0.77 per aumentare la nostra replica MySQL:
$ s9s cluster --add-node --nodes="10.0.0.77" --cluster-id=24
Job with ID 66992 registered.Possiamo quindi monitorare il jobID 66992 utilizzando l'opzione job:
$ s9s job --log --job-id=66992
addNode: Verifying job parameters.
10.0.0.77:3306: Adding host to cluster.
10.0.0.77:3306: Testing SSH to host.
10.0.0.77:3306: Installing node.
10.0.0.77:3306: Setup new node (installSoftware = true).
10.0.0.77:3306: Setting SELinux in permissive mode.
10.0.0.77:3306: Disabling firewall.
10.0.0.77:3306: Setting vm.swappiness = 1
10.0.0.77:3306: Installing software.
10.0.0.77:3306: Setting up repositories.
10.0.0.77:3306: Installing helper packages.
10.0.0.77: Upgrading nss.
10.0.0.77: Upgrading ca-certificates.
10.0.0.77: Installing socat.
...
10.0.0.77: Installing pigz.
10.0.0.77: Installing bzip2.
10.0.0.77: Installing iproute2.
10.0.0.77: Installing tar.
10.0.0.77: Installing openssl.
10.0.0.77: Upgrading openssl openssl-libs.
10.0.0.77: Finished with helper packages.
10.0.0.77:3306: Verifying helper packages (checking if socat is installed successfully).
10.0.0.77:3306: Uninstalling existing MySQL packages.
10.0.0.77:3306: Installing replication software, vendor oracle, version 5.7.
10.0.0.77:3306: Installing software.
...Oppure possiamo usare il flag --wait e ottenere uno spinner con barra di avanzamento:
$ s9s job --wait --job-id=66992
Add Node to Cluster
- Job 66992 RUNNING [ █] ---% Add New Node to ClusterQuesto è tutto per il supplemento di monitoraggio di oggi. Ci auguriamo che proverai la CLI e ne trarrai valore. Buon raggruppamento



