Nel nostro precedente tutorial Hadoop , abbiamo studiato Hadoop Partitioner in dettaglio. Ora parleremo di InputSplit in Hadoop MapReduce.
Qui tratteremo cos'è Hadoop InputSplit, la necessità di InputSplit in MapReduce. Discuteremo anche in dettaglio come vengono creati questi InputSplit in Hadoop MapReduce.
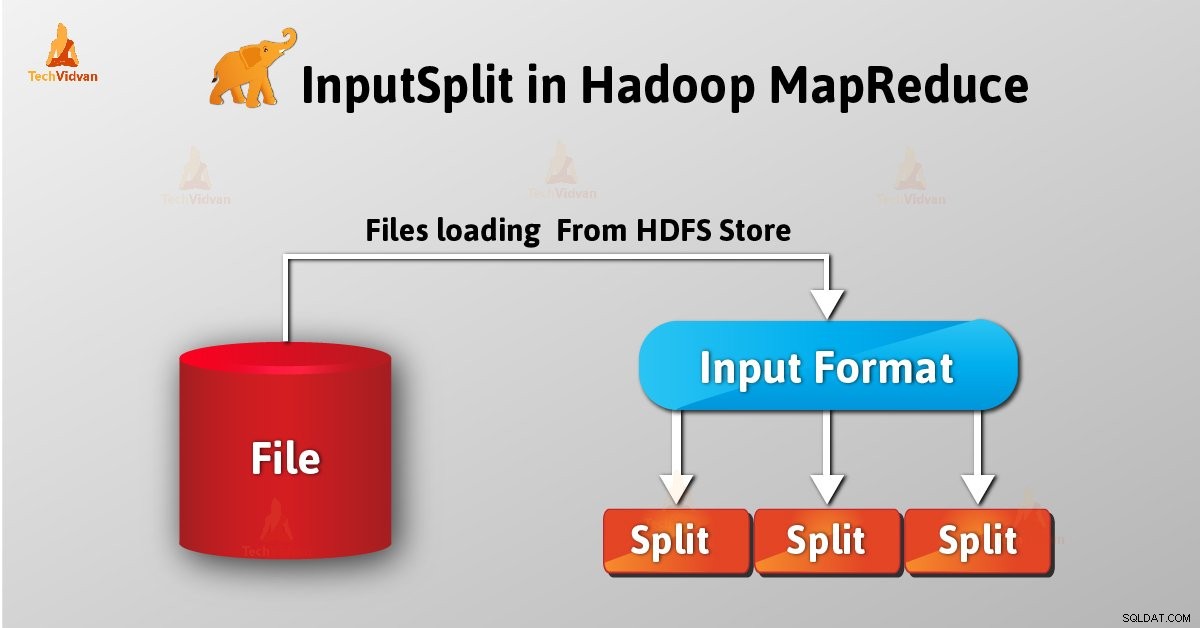
Introduzione a InputSplit in Hadoop
InputSplit è la rappresentazione logica dei dati in Hadoop MapReduce. Rappresenta i dati che il singolo mapper processi. Quindi il numero di attività della mappa è uguale al numero di InputSplits. Il framework si divide in record, che elabora il mapper.
La lunghezza di MapReduce InputSplit è stata misurata in byte. Ogni InputSplit ha posizioni di archiviazione (stringhe di nomi host). Il sistema MapReduce posiziona le attività della mappa il più vicino possibile ai dati della divisione utilizzando posizioni di archiviazione.
Processi del framework Mappare le attività nell'ordine della dimensione delle divisioni in modo che quella più grande venga elaborata per prima (algoritmo di approssimazione avida). Ciò riduce al minimo il tempo di esecuzione del lavoro.
La cosa principale su cui concentrarsi è che Inputsplit non contiene i dati di input; è solo un riferimento ai dati.
Come vengono creati gli InputSplit in Hadoop MapReduce?
Come utente, non ci occupiamo direttamente di InputSplit in Hadoop, poiché InputFormat (poiché InputFormat è responsabile della creazione di Inputsplit e della divisione nei record) lo crea. FileInputFormat suddivide un file in blocchi da 128 MB.
Inoltre, impostando mapred .min .divisi .dimensioni parametro in mapred-site .xml l'utente può modificare il valore secondo il requisito. Anche in questo modo possiamo sovrascrivere il parametro nell'oggetto Job utilizzato per inviare un particolare lavoro MapReduce.
Scrivendo un InputFormat personalizzato possiamo anche controllare come il file viene suddiviso in suddivisioni.
InputSplit è definito dall'utente. L'utente può anche controllare la dimensione della divisione in base alla dimensione dei dati nel programma MapReduce. Quindi, in un'esecuzione di un processo MapReduce il numero di attività mappa è uguale al numero di InputSplits.
Chiamando 'getSplit()' , il cliente calcola le divisioni per il lavoro. Quindi è stato inviato al master dell'applicazione, che utilizza le loro posizioni di archiviazione per pianificare le attività della mappa che le elaboreranno sul cluster.
Dopo che l'attività della mappa passa la divisione a createRecordReader() metodo. Da ciò ottiene RecordReader per la scissione. Quindi RecordReader genera il record (coppia chiave-valore) , che passa alla funzione mappa.
Conclusione
In conclusione possiamo dire che InputSplit rappresenta i dati che elabora i singoli mapper. Per ogni divisione viene creata un'attività mappa. Quindi, InputFormat crea InputSplit.
Se hai qualche domanda su InputSplit in MapReduce, quindi, lascia un commento in una sezione indicata di seguito.



