Nel nostro precedenteHadoop blog abbiamo studiato ogni componente di Hadoop Processo MapReduce in dettaglio. In questo discuteremo l'argomento molto interessante, ovvero il lavoro Map Only in Hadoop.
In primo luogo, faremo una breve introduzione della Mappa e Riduci fase in Hadoop Mapreduce, quindi dopo discuteremo che cos'è il lavoro solo mappa in Hadoop MapReduce.
Alla fine discuteremo anche i vantaggi e gli svantaggi del lavoro Hadoop Map Only in questo tutorial.
Cos'è Hadoop Map Only Job?
Lavoro solo mappa in Hadoop è il processo in cui mapper fa tutti i compiti. Nessun compito viene svolto dal riduttore . L'output di Mapper è l'output finale.
MapReduce è il livello di elaborazione dei dati di Hadoop. Elabora grandi dati strutturati e non strutturati archiviati in HDFS . MapReduce elabora anche un'enorme quantità di dati in parallelo.
Lo fa dividendo il lavoro (lavoro inviato) in una serie di attività indipendenti (sottolavoro). In Hadoop, MapReduce funziona suddividendo l'elaborazione in fasi:Mappa e Riduci .
- Mappa: È la prima fase dell'elaborazione, in cui specifichiamo tutto il codice logico complesso. Prende un insieme di dati e lo converte in un altro insieme di dati. Suddivide ogni singolo elemento in tuple (coppie chiave-valore ).
- Riduci: È la seconda fase di elaborazione. Qui specifichiamo un'elaborazione leggera come aggregazione/somma. Prende l'output dalla mappa come input. Quindi combina quelle tuple in base alla chiave.
Da questo esempio di conteggio delle parole, possiamo dire che esistono due insiemi di processi paralleli, mappare e ridurre. Nel processo della mappa, il primo input viene suddiviso per distribuire il lavoro tra tutti i nodi della mappa come mostrato sopra.
Quindi framework identifica ogni parola e mappa al numero 1. Pertanto, crea coppie chiamate coppie di tuple (valore-chiave).
Nel primo nodo del mappatore, passa tre parole leone, tigre e fiume. Pertanto, produce 3 coppie chiave-valore come output del nodo. Tre chiavi diverse e valore impostato su 1 e lo stesso processo si ripete per tutti i nodi.
Quindi passa queste tuple ai nodi del riduttore. Il partizionatore esegue il shuffle in modo che tutte le tuple con la stessa chiave vadano allo stesso nodo.
Nel processo di riduzione ciò che sostanzialmente accade è un'aggregazione di valori ovvero un'operazione su valori che condividono la stessa chiave.
Consideriamo ora uno scenario in cui dobbiamo solo eseguire l'operazione. Non abbiamo bisogno di aggregazione, in tal caso preferiremo "Lavoro solo mappa '.
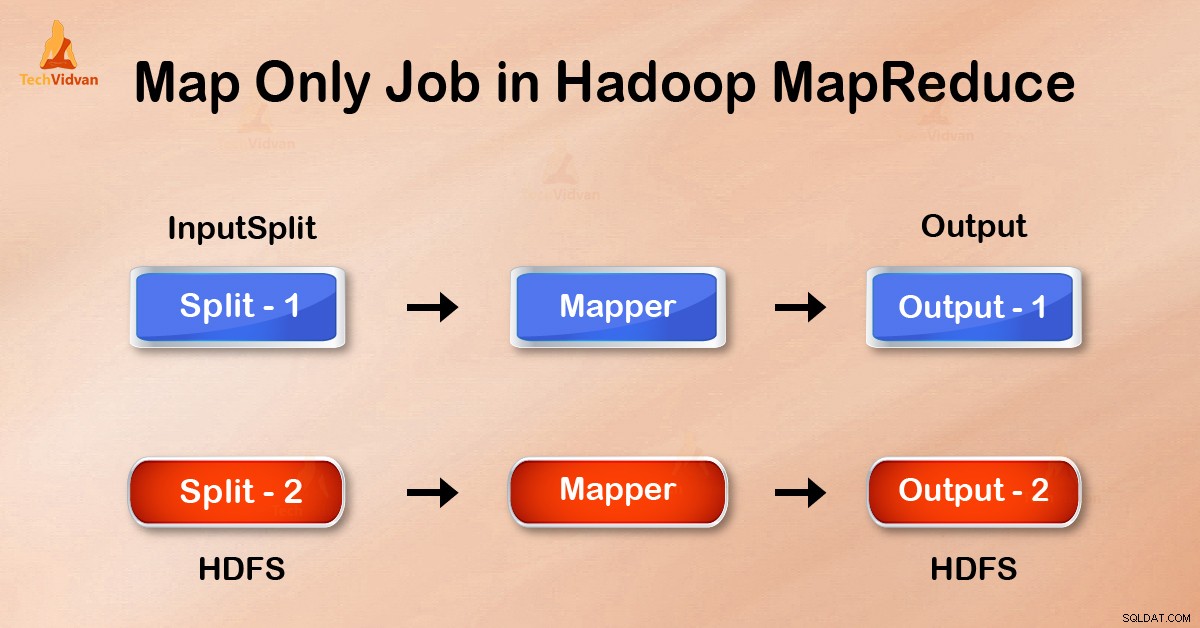
Nel lavoro Map-Only, la mappa esegue tutte le attività con il suo InputSplit . Il riduttore non funziona. L'output dei mappatori è l'output finale.
Come evitare la fase di riduzione in MapReduce?
Impostando job.setNumreduceTasks(0) nella configurazione in un driver possiamo evitare di ridurre la fase. Questo farà un numero di riduttore come 0 . Pertanto, l'unico mappatore eseguirà l'attività completa.
Vantaggi del lavoro Solo mappa in Hadoop
In MapReduce l'esecuzione del lavoro tra le fasi mappa e riduce c'è la fase chiave, ordinamento e shuffle. Rimescolamento – Ordinamento sono responsabili dello smistamento delle chiavi in ordine crescente. Quindi raggruppare i valori in base alle stesse chiavi. Questa fase è molto costosa.
Se non è necessario ridurre la fase, dovremmo evitarlo. Poiché evitare di ridurre la fase eliminerebbe anche la fase di smistamento e smistamento. Pertanto, ciò farà risparmiare anche la congestione della rete.
Il motivo è che mescolando, un'uscita del mappatore viaggia per ridursi. E quando le dimensioni dei dati sono enormi, i dati di grandi dimensioni devono viaggiare verso il riduttore.
L'output del mapper viene scritto sul disco locale prima dell'invio per ridurre. Ma nel processo Solo mappa, questo output viene scritto direttamente in HDFS. Ciò consente di risparmiare ulteriormente tempo e di ridurre i costi.
Conclusione
Quindi, abbiamo visto che il lavoro Map-only riduce la congestione della rete evitando lo shuffle, l'ordinamento e la riduzione della fase. La mappa da sola si occupa dell'elaborazione complessiva e produce l'output. UTILIZZANDO job.setNumreduceTasks(0) questo è ottenuto.
Spero che tu abbia compreso il lavoro Solo mappa di Hadoop e il suo significato perché abbiamo coperto tutto sul lavoro Solo mappa in Hadoop. Ma se hai qualche domanda, puoi condividerla con noi nella sezione commenti.



