Garantire il corretto funzionamento dei database di produzione non è un compito banale e ci sono una serie di strumenti e utilità per aiutare con il lavoro. Sono disponibili strumenti per monitorare l'integrità, le prestazioni del server, l'analisi di query, le distribuzioni, la gestione del failover, gli aggiornamenti e l'elenco potrebbe continuare. ClusterControl come piattaforma di gestione e monitoraggio per l'infrastruttura di database si distingue per la sua capacità di gestire l'intero ciclo di vita dall'implementazione al monitoraggio, alla gestione continua e al ridimensionamento.
Sebbene ClusterControl offra funzionalità importanti come il failover automatico del database, la crittografia in transito/a riposo, la gestione del backup, il ripristino point-in-time, l'integrazione di Prometheus e il ridimensionamento del database, queste possono essere trovate in altri strumenti di gestione/monitoraggio aziendali sul mercato. Tuttavia, ci sono alcune funzionalità che non troverai facilmente. In questo post del blog presenteremo 9 funzionalità che non troverai in nessun altro strumento di gestione e monitoraggio sul mercato (come il momento in cui scriviamo).
Verifica del backup
Qualsiasi backup non è letteralmente un backup finché non sai che può essere ripristinato, verificando realmente che possa essere ripristinato. ClusterControl consente di verificare un backup dopo che il backup è stato eseguito girando un nuovo server e testando il ripristino. La verifica di un backup è un processo fondamentale per assicurarsi di soddisfare la politica dell'obiettivo del punto di ripristino (RPO) in caso di ripristino di emergenza. Il processo di verifica eseguirà il ripristino su un nuovo host autonomo (dove ClusterControl installerà i pacchetti di database necessari prima del ripristino) o su un server dedicato alla verifica del backup.
Per configurare la verifica del backup, seleziona semplicemente un backup esistente e fai clic su Ripristina. Ci sarà un'opzione per ripristinare e verificare:
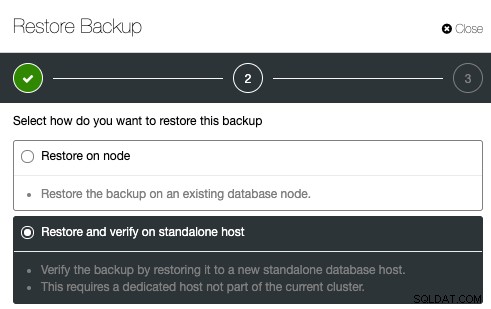
Quindi, specifica semplicemente l'indirizzo IP del server che desideri ripristinare e verificare:
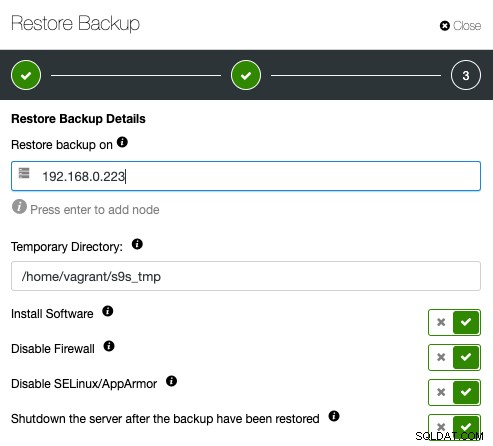
Assicurati che l'host specificato sia accessibile tramite SSH senza password in anticipo. Hai anche una manciata di opzioni sotto per il processo di provisioning. È inoltre possibile arrestare il server di verifica dopo il ripristino per risparmiare costi e risorse dopo la verifica del backup. ClusterControl cercherà il codice di uscita del processo di ripristino e osserverà il registro di ripristino per verificare se la verifica ha esito negativo o positivo.
Semplificazione della gestione di ProxySQL tramite una GUI
Molti sarebbero d'accordo sul fatto che avere un'interfaccia utente grafica sia più efficiente e meno soggetta a errori umani durante la configurazione di un sistema. ProxySQL è una parte del livello di database critico (sebbene si trovi sopra di esso) e deve essere sufficientemente visibile agli occhi di DBA per individuare problemi e problemi comuni. ClusterControl fornisce un'interfaccia utente grafica completa per ProxySQL.
Le istanze ProxySQL possono essere distribuite su nuovi host o importare quelle esistenti in ClusterControl. ClusterControl può configurare ProxySQL per l'integrazione con un indirizzo IP virtuale (fornito da Keepalived) per l'accesso di un singolo endpoint ai server di database. Fornisce inoltre informazioni dettagliate sul monitoraggio dei componenti chiave di ProxySQL come il backend delle query, le query lente, le query principali, gli hit delle query e una serie di altre statistiche di monitoraggio. Quello che segue è uno screenshot che mostra come aggiungere una nuova regola di query:
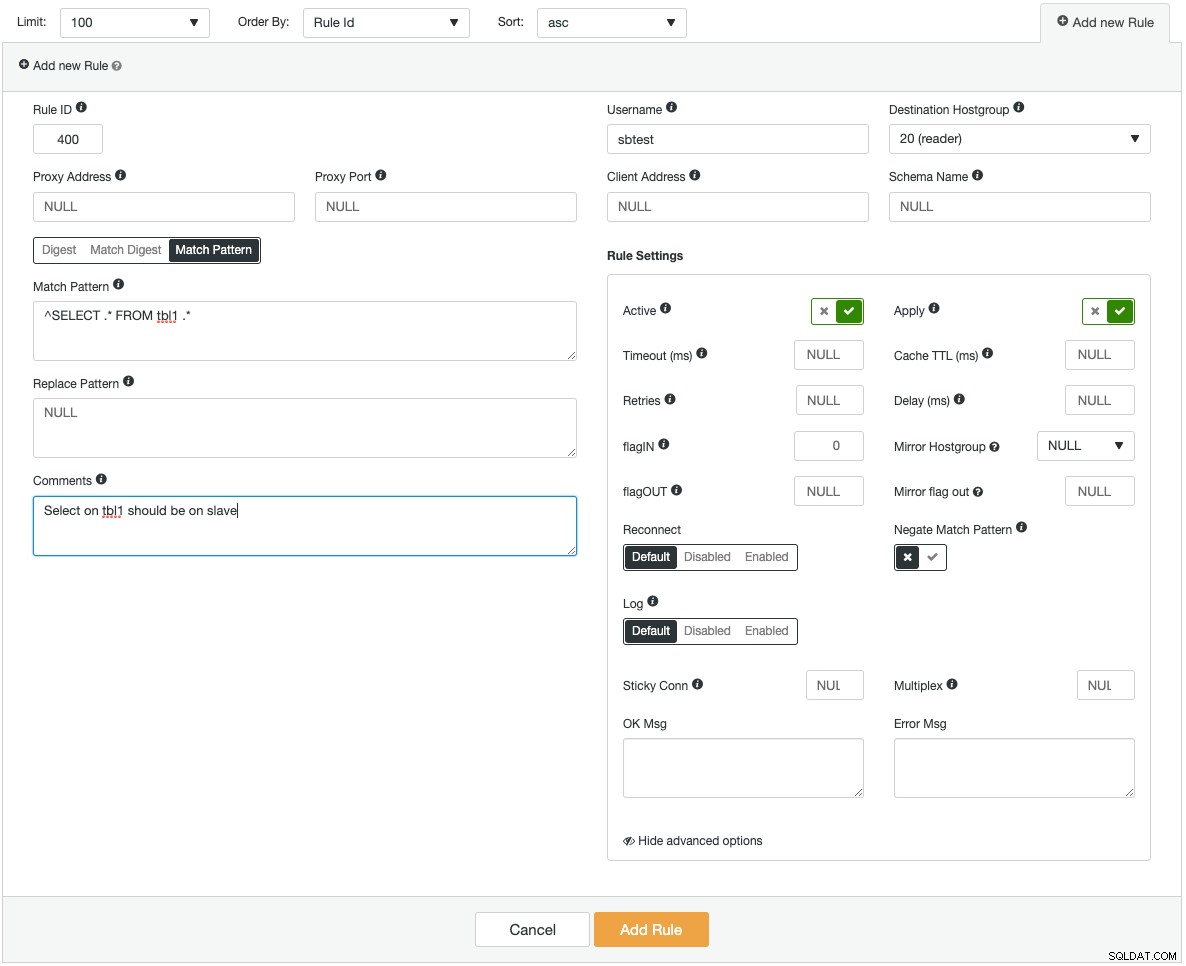
Se dovessi aggiungere una regola di query molto complessa, ti sentiresti più a tuo agio nel farlo tramite l'interfaccia utente grafica. Ogni campo ha un suggerimento per assisterti durante la compilazione del modulo delle regole di query. Quando si aggiunge o si modifica una configurazione ProxySQL, ClusterControl si assicurerà che le modifiche vengano apportate al runtime e salvate su disco per la persistenza.
ClusterControl 1.7.4 ora supporta sia ProxySQL 1.x che ProxySQL 2.x.
Rapporti operativi
I rapporti operativi sono un insieme di rapporti di riepilogo dell'infrastruttura del database che possono essere generati al volo o programmati per essere inviati a destinatari diversi. Questi report consistono in diversi controlli e affrontano varie attività DBA quotidiane. L'idea alla base del reporting operativo di ClusterControl è quella di mettere tutti i dati più rilevanti in un unico documento che può essere rapidamente analizzato al fine di ottenere una chiara comprensione dello stato dei database e dei suoi processi.
Con ClusterControl è possibile pianificare report sull'ambiente tra cluster come Report giornaliero sul sistema, Report sull'aggiornamento dei pacchetti, Report sulle modifiche allo schema, nonché backup e disponibilità. Questi rapporti ti aiuteranno a mantenere il tuo ambiente sicuro e operativo. Vedrai anche consigli su come correggere le lacune. I report possono essere indirizzati a SysOps, DevOps o persino ai manager che desiderano ricevere aggiornamenti regolari sullo stato dello stato di un determinato sistema.
Di seguito è riportato un esempio di rapporto operativo giornaliero inviato alla tua casella di posta in merito alla disponibilità:
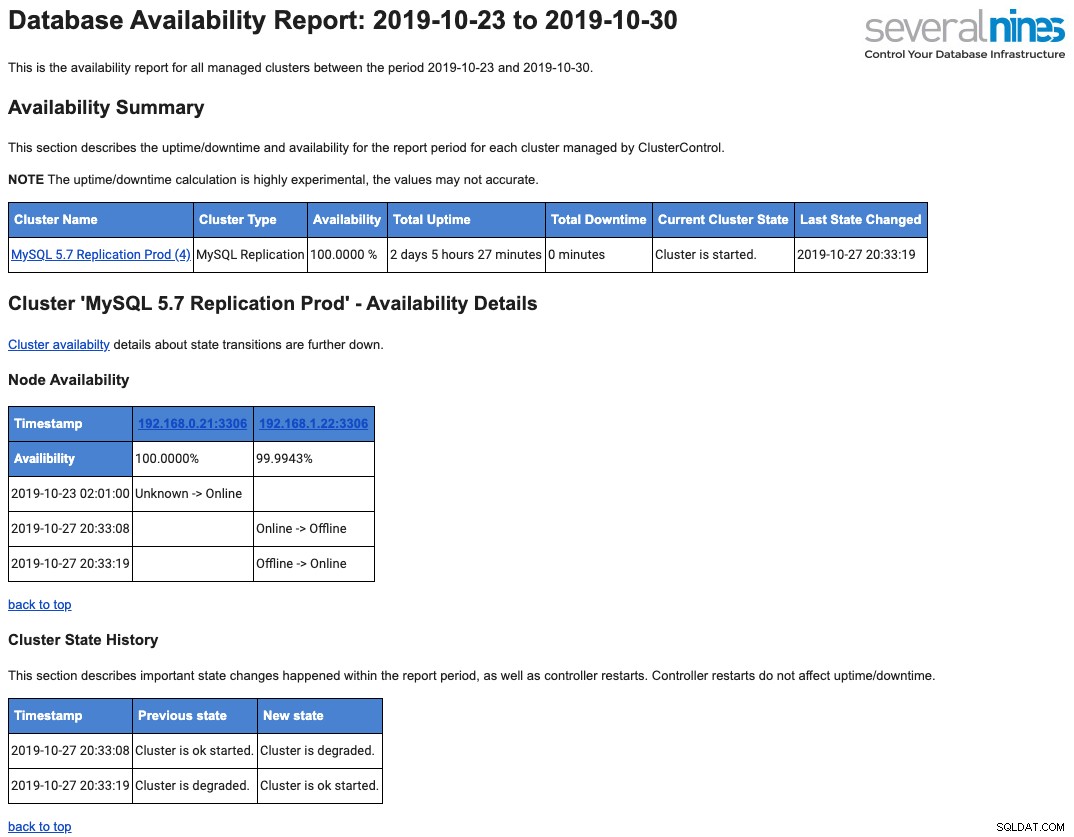
Ne abbiamo parlato in dettaglio in questo post del blog, An Overview of Database Operational Reporting in ClusterControl.
Risincronizza uno slave tramite backup
ClusterControl consente di eseguire lo staging di uno slave (che sia un nuovo slave o uno slave rotto) tramite l'ultimo backup completo o incrementale. Non sembra molto eccitante, ma questa funzione è enorme se hai grandi set di dati di 100 GB e oltre. Una pratica comune durante la risincronizzazione di uno slave è eseguire lo streaming di un backup del master corrente che richiederà del tempo a seconda delle dimensioni del database. Ciò aggiungerà un ulteriore onere al master, che potrebbe compromettere le prestazioni del master.
Per risincronizzare uno slave tramite backup, seleziona il nodo slave nella pagina Nodi e vai su Azioni nodo -> Ricostruisci replica slave -> Ricostruisci da un backup. Solo il backup compatibile con PITR verrà elencato nel menu a discesa:
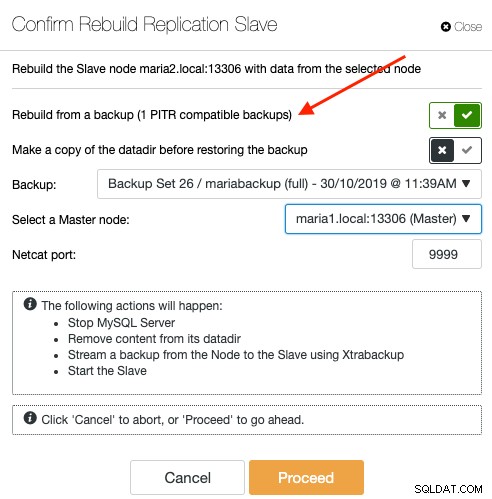
La risincronizzazione di uno slave da un backup non comporterà alcun sovraccarico aggiuntivo per il master, in cui ClusterControl estrae e trasmette il backup dalla posizione di archiviazione del backup allo slave e alla fine configura il collegamento di replica tra lo slave e il master. Lo slave raggiungerà in seguito il master una volta stabilito il collegamento di replica. Il master non viene toccato durante l'intero processo e puoi monitorare l'intero progresso in Attività -> Lavori.
Stivalizza un ammasso Galera
Galera Cluster è molto popolare quando si implementa l'alta disponibilità per MySQL o MariaDB, ma i comandi di gestione sbagliati possono portare a conseguenze disastrose. Dai un'occhiata a questo post del blog su come avviare un cluster Galera in condizioni diverse. Ciò dimostra che il bootstrap di un cluster Galera ha molte variabili e deve essere eseguito con estrema cura. In caso contrario, potresti perdere dati o causare uno split brain. ClusterControl comprende la topologia del database e sa esattamente cosa fare per avviare correttamente un cluster di database. Per eseguire il bootstrap di un cluster tramite ClusterControl, fare clic su Cluster Actions -> Bootstrap Cluster:
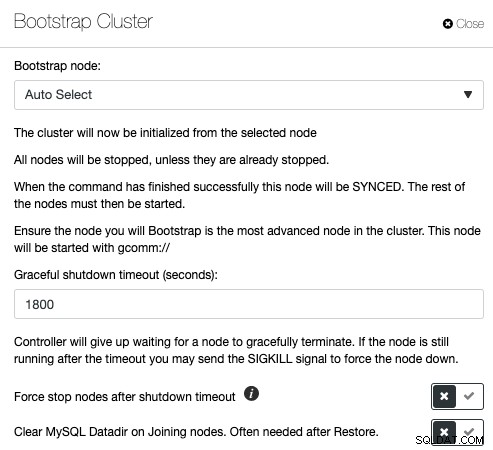
Avrai la possibilità di lasciare che ClusterControl scelga automaticamente il nodo di bootstrap corretto o di eseguire un bootstrap iniziale in cui scegli uno dei nodi del database dall'elenco per diventare il nodo di riferimento ed elimina la datadir MySQL sui nodi joiner per forzare SST da il nodo avviato. Se il processo di bootstrap non riesce, ClusterControl estrarrà il log degli errori MySQL.
Se desideri eseguire un bootstrap manuale, puoi anche utilizzare la funzione "Trova il nodo più avanzato" ed eseguire l'operazione di bootstrap del cluster sul nodo più avanzato riportato da ClusterControl.
Configurazione centralizzata e registrazione
ClusterControl estrae una serie di importanti file di configurazione e registrazione e li visualizza in una struttura ad albero all'interno di ClusterControl. Una visualizzazione centralizzata di questi file è fondamentale per comprendere e risolvere in modo efficiente le configurazioni di database distribuiti. Il modo tradizionale di eseguire il tailing/grepping di questi file è ormai scomparso con ClusterControl. Lo screenshot seguente mostra il file manager di configurazione di ClusterControl che elenca tutti i file di configurazione correlati per questo cluster in un'unica vista (con l'evidenziazione della sintassi, ovviamente):
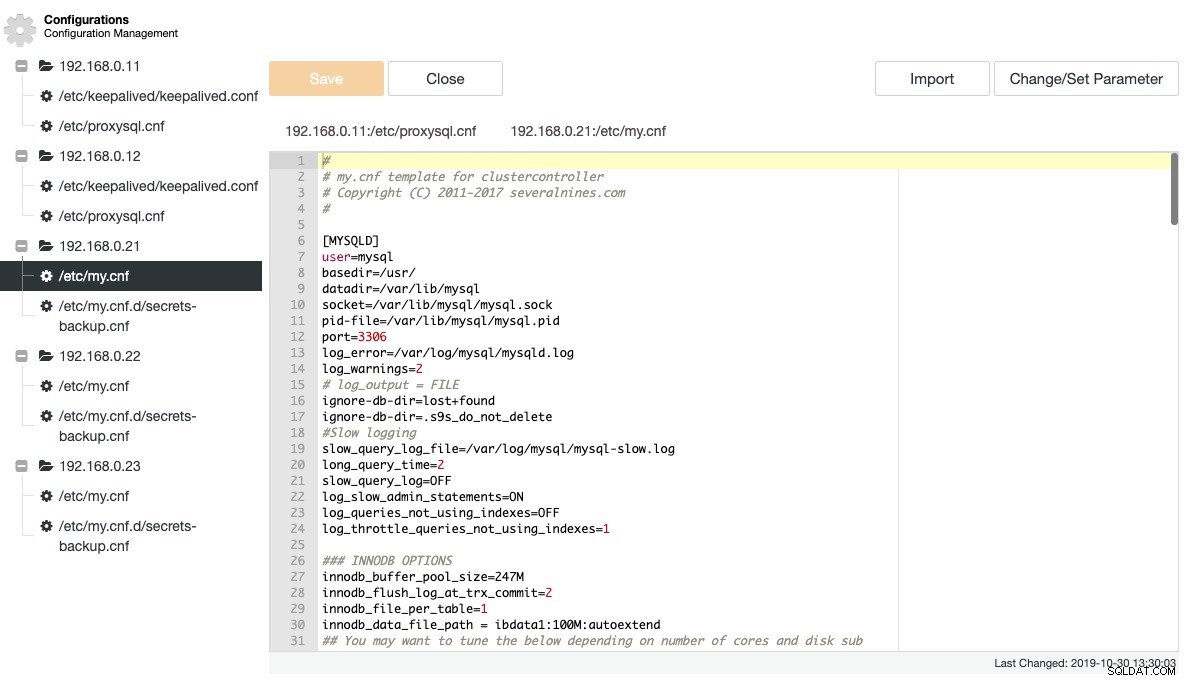
ClusterControl elimina la ripetitività durante la modifica di un'opzione di configurazione di un cluster di database. La modifica di un'opzione di configurazione su più nodi può essere eseguita tramite un'unica interfaccia e verrà applicata di conseguenza al nodo del database. Quando fai clic su "Modifica/Imposta parametro", puoi selezionare le istanze del database che desideri modificare e specificare il gruppo di configurazione, il parametro e il valore:
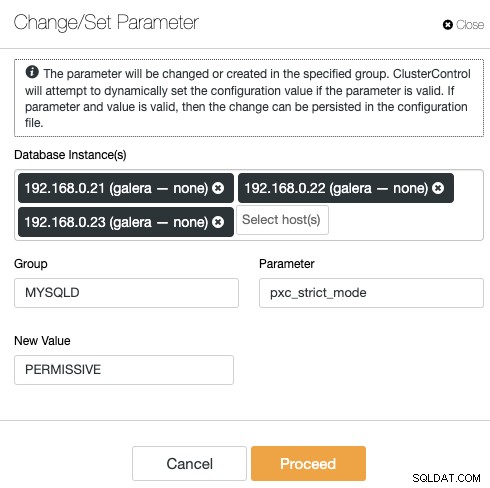
Puoi aggiungere un nuovo parametro nel file di configurazione o modificare un parametro esistente . Il parametro verrà applicato al runtime dei nodi del database scelti e nel file di configurazione se l'opzione supera il processo di convalida delle variabili. Alcune variabili potrebbero richiedere il riavvio del server, che verrà quindi consigliato da ClusterControl.
Clonazione del cluster di database
Con ClusterControl, puoi clonare rapidamente un cluster MySQL Galera esistente in modo da avere una copia esatta del set di dati sull'altro cluster. ClusterControl esegue l'operazione di clonazione in linea, senza alcun blocco o tempi di inattività del cluster esistente. È come un'operazione di scalabilità orizzontale del cluster, tranne per il fatto che entrambi i cluster sono indipendenti l'uno dall'altro al termine della sincronizzazione. Il cluster clonato non deve necessariamente avere le stesse dimensioni del cluster di quello esistente. Potremmo iniziare con un "cluster a un nodo" e scalarlo con più nodi di database in una fase successiva.
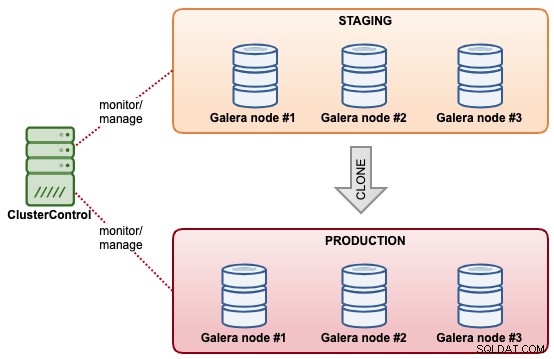
Un'altra funzionalità simile offerta da ClusterControl è "Crea cluster da backup". Questa funzionalità è stata introdotta in ClusterControl 1.7.1, in particolare per i cluster Galera Cluster e PostgreSQL in cui è possibile creare un nuovo cluster dal backup esistente. Contrariamente alla clonazione del cluster, questa operazione non apporta un carico aggiuntivo al cluster di origine con il compromesso che il cluster clonato non sarà nello stesso stato del cluster di origine.
Abbiamo trattato questo argomento in dettaglio in questo post del blog, Come creare un clone del cluster di database MySQL o PostgreSQL.
Ripristina backup fisico
La maggior parte degli strumenti di gestione del database consente il backup di un database e solo pochi di essi supportano il ripristino del database solo del backup logico. ClusterControl supporta il ripristino completo non solo per i backup logici, ma anche per i backup fisici, indipendentemente dal fatto che si tratti di un backup completo o incrementale. Il ripristino di un backup fisico richiede una serie di passaggi critici (soprattutto backup incrementali) che implicano fondamentalmente la preparazione di un backup, la copia dei dati preparati nella directory dei dati, l'assegnazione di autorizzazioni/proprietà corrette e l'avvio del nodo nell'ordine corretto per mantenere la coerenza dei dati tra tutti i membri del cluster. ClusterControl esegue tutte queste operazioni automaticamente.
Puoi anche ripristinare un backup fisico su un altro nodo che non fa parte di un cluster. In ClusterControl l'opzione si chiama "Crea cluster da backup". Puoi iniziare con un "cluster a un nodo" per testare il processo di ripristino su un altro server o per copiare il tuo cluster di database in un'altra posizione.
ClusterControl supporta anche il ripristino di un backup esterno, un backup che non è stato eseguito tramite ClusterControl. È sufficiente caricare il backup sul server ClusterControl e specificare il percorso fisico del file di backup durante il ripristino. ClusterControl si occuperà del resto.
Replica da cluster a cluster
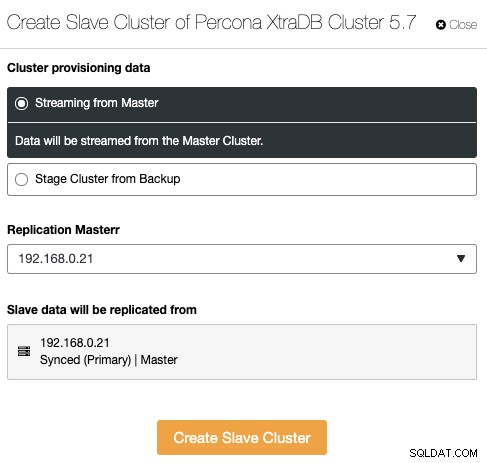
Questa è una nuova funzionalità introdotta in ClusterControl 1.7.4. ClusterControl è ora in grado di gestire e monitorare la replica cluster-cluster, che sostanzialmente estende la replica asincrona del database tra più set di cluster in più posizioni geografiche. Un cluster può essere impostato come cluster master (cluster attivo che elabora letture/scritture) e il cluster slave può essere impostato come cluster di sola lettura (cluster standby che può anche elaborare letture). ClusterControl supporta la replica asincrona cluster-cluster per Galera Cluster (il registro binario deve essere abilitato) e anche la replica master-slave per PostgreSQL Streaming Replication.
Per creare un nuovo cluster replicato da un altro cluster, vai su Azioni cluster -> Crea cluster slave:
Il risultato della distribuzione di cui sopra è presentato chiaramente nel dashboard Elenco cluster di database :
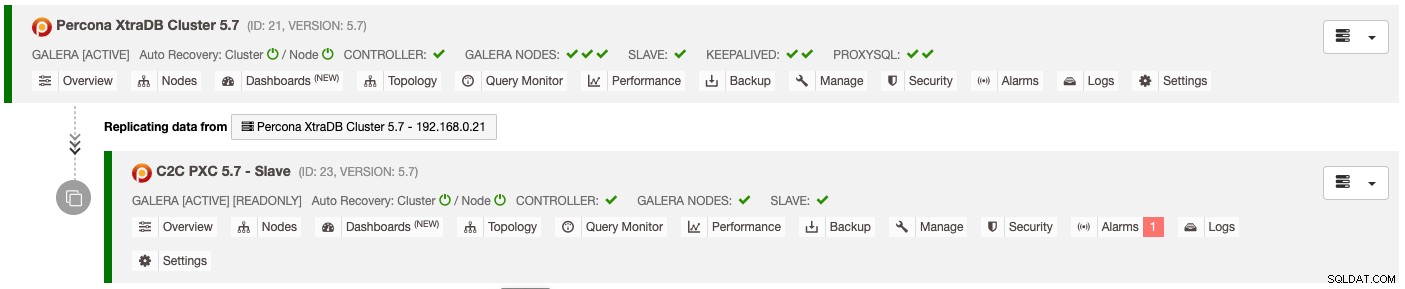
Il cluster slave viene configurato automaticamente come di sola lettura, replicando dal cluster primario e fungendo da cluster di standby. Se il disastro colpisce il cluster principale e desideri attivare il sito secondario, seleziona semplicemente il menu "Disabilita sola lettura" disponibile nel menu a discesa Nodi -> Azioni nodo per promuoverlo come cluster attivo.



