ClusterControl è programmato con una serie di algoritmi di ripristino per rispondere automaticamente a diversi tipi di errori comuni che interessano i sistemi di database. Comprende diversi tipi di topologie di database e gestione dei processi relativi al database per aiutarti a determinare il modo migliore per ripristinare il cluster. In un certo senso, ClusterControl migliora la disponibilità del database.
Alcuni gestori di topologie coprono solo il ripristino del cluster come MHA, Orchestrator e mysqlfailover, ma devi gestire il ripristino del nodo da solo. ClusterControl supporta il ripristino sia a livello di cluster che di nodo.
Opzioni di configurazione
Ci sono due componenti di ripristino supportati da ClusterControl, ovvero:
- Cluster - Tentativo di ripristinare un cluster a uno stato operativo
- Nodo - Tentativo di ripristinare un nodo in uno stato operativo
Questi due componenti sono le cose più importanti per assicurarsi che la disponibilità del servizio sia la più alta possibile. Se hai già un gestore della topologia su ClusterControl, puoi disabilitare la funzione di ripristino automatico e lasciare che un altro gestore della topologia lo gestisca per te. Hai tutte le possibilità con ClusterControl.
La funzione di ripristino automatico può essere abilitata e disabilitata con un semplice interruttore ON/OFF e funziona per il ripristino di cluster o nodi. Le icone verdi significano abilitato e le icone rosse significano disabilitato. Lo screenshot seguente mostra dove puoi trovarlo nell'elenco dei cluster di database:
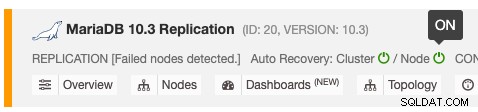
Sono disponibili 3 parametri ClusterControl che possono essere utilizzati per controllare il comportamento di ripristino. Tutti i parametri sono di default su true (impostati con intero booleano 0 o 1):
- enable_autorecovery - Abilita il ripristino di cluster e nodi. Questo parametro è il superset di enable_cluster_recovery e enable_node_recovery. Se è impostato su 0, i parametri del sottoinsieme verranno disattivati.
- enable_cluster_recovery - ClusterControl eseguirà il ripristino del cluster se abilitato.
- enable_node_recovery - ClusterControl eseguirà il ripristino del nodo se abilitato.
Il ripristino del cluster copre il tentativo di ripristino di visualizzare l'intera topologia del cluster. Ad esempio, una replica master-slave deve avere almeno un master attivo in un dato momento, indipendentemente dal numero di slave disponibili. ClusterControl tenta di correggere la topologia almeno una volta per i cluster di replica, ma all'infinito per la replica multi-master come NDB Cluster e Galera Cluster.
Il ripristino del nodo copre i problemi di ripristino del nodo, come se un nodo fosse stato arrestato senza che ClusterControl fosse a conoscenza, ad esempio tramite il comando di arresto del sistema dalla console SSH o se fosse stato interrotto dal processo OOM.
Recupero del nodo
ClusterControl è in grado di ripristinare un nodo del database in caso di guasto intermittente monitorando il processo e la connettività ai nodi del database. Per il processo, funziona in modo simile a systemd, dove si assicurerà che il servizio MySQL sia avviato e in esecuzione, a meno che non sia stato interrotto intenzionalmente tramite l'interfaccia utente di ClusterControl.
Se il nodo torna in linea, ClusterControl stabilirà una connessione al nodo del database ed eseguirà le azioni necessarie. Quello che segue è ciò che ClusterControl farebbe per ripristinare un nodo:
- Aspetterà che systemd/chkconfig/init avvii i servizi/processi monitorati per 30 secondi
- Se i servizi/processi monitorati sono ancora inattivi, ClusterControl proverà ad avviare automaticamente il servizio database.
- Se ClusterControl non è in grado di ripristinare i servizi/processi monitorati, verrà generato un allarme.
Si noti che se l'arresto del database viene avviato dall'utente, ClusterControl non tenterà di ripristinare il nodo particolare. Si aspetta che l'utente lo riavvii tramite ClusterControl UI andando su Node -> Node Actions -> Start Node o usando il comando del sistema operativo in modo esplicito.
Il ripristino include tutti i servizi relativi al database come ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus exporters e garbd. Particolare attenzione agli esportatori Prometheus dove ClusterControl utilizza un programma chiamato "daemon" per demonizzare il processo di esportazione. ClusterControl proverà a connettersi alla porta di ascolto dell'esportatore per il controllo e la verifica dello stato. Pertanto, si consiglia di aprire le porte di esportazione dal server ClusterControl e Prometheus per assicurarsi che non vi siano falsi allarmi durante il ripristino.
Recupero del cluster
ClusterControl comprende la topologia del database e segue le migliori pratiche nell'esecuzione del ripristino. Per un cluster di database dotato di tolleranza agli errori incorporata come Galera Cluster, NDB Cluster e MongoDB Replicaset, il processo di failover verrà eseguito automaticamente dal server di database tramite calcolo del quorum, heartbeat e cambio di ruolo (se presente). ClusterControl monitora il processo e apporta le modifiche necessarie alla visualizzazione, ad esempio riflettendo le modifiche nella vista Topologia e adattando il componente di monitoraggio e gestione per il nuovo ruolo, ad esempio, nuovo nodo primario in un set di repliche.
Per le tecnologie di database che non dispongono di una tolleranza agli errori incorporata con ripristino automatico come la replica MySQL/MariaDB e la replica in streaming PostgreSQL/TimescaleDB, ClusterControl eseguirà le procedure di ripristino seguendo le best practice fornite dal fornitore di database. Se il ripristino non riesce, è necessario l'intervento dell'utente e, naturalmente, riceverai una notifica di allarme al riguardo.
In una topologia mista/ibrida, ad esempio uno slave asincrono collegato a un cluster Galera o un cluster NDB, il nodo verrà ripristinato da ClusterControl se il ripristino del cluster è abilitato.
Il ripristino del cluster non si applica al server MySQL autonomo. Tuttavia, si consiglia di attivare sia il ripristino del nodo che del cluster per questo tipo di cluster nell'interfaccia utente di ClusterControl.
Replica MySQL/MariaDB
ClusterControl supporta il ripristino della seguente configurazione di replica MySQL/MariaDB:
- Master-slave con MySQL GTID
- Master-slave con MariaDB GTID
- Master-slave senza GTID (sia MySQL che MariaDB)
- Master-master con MySQL GTID
- Master-master con MariaDB GTID
- Slave asincrono collegato a un cluster Galera
ClusterControl rispetterà i seguenti parametri durante l'esecuzione del ripristino del cluster:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- utente_repl
- replica_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replica_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Per maggiori dettagli su ciascuno dei parametri, fare riferimento alla pagina della documentazione.
ClusterControl rispetterà le seguenti regole durante il monitoraggio e la gestione di una replica master-slave:
- Tutti i nodi verranno avviati con read_only=ON e super_read_only=ON (indipendentemente dal suo ruolo).
- Un solo master (read_only=OFF) può operare in un dato momento.
- Fai affidamento sulla variabile MySQL report_host per mappare la topologia.
- Se sono presenti due o più nodi che hanno read_only=OFF alla volta, ClusterControl imposterà automaticamente read_only=ON su entrambi i master, per proteggerli da scritture accidentali. È necessario l'intervento dell'utente per selezionare il master effettivo disabilitando la sola lettura. Vai a Nodi -> Azioni nodo -> Disattiva sola lettura.
Nel caso in cui il master attivo si interrompa, ClusterControl tenterà di eseguire il failover del master nel seguente ordine:
- Dopo 3 secondi di irraggiungibilità del master, ClusterControl lancerà un allarme.
- Verifica la disponibilità degli slave, almeno uno degli slave deve essere raggiungibile da ClusterControl.
- Scegli lo schiavo come candidato per diventare un maestro.
- ClusterControl calcolerà la probabilità di transazioni errate se GTID è abilitato.
- Se non viene rilevata alcuna transazione errante, il prescelto verrà promosso come nuovo master.
- Crea e concedi l'utente di replica per essere utilizzato dagli slave.
- Cambia master per tutti gli slave che puntavano dal vecchio master al nuovo master.
- Avvia lo slave e abilita la sola lettura.
- Svuota i log su tutti i nodi.
- Se la promozione dello slave non riesce, ClusterControl interromperà il processo di ripristino. Per attivare nuovamente il processo di ripristino è necessario l'intervento dell'utente o il riavvio del servizio cmon.
- Quando il vecchio master sarà nuovamente disponibile, verrà avviato in sola lettura e non farà parte della replica. È richiesto l'intervento dell'utente.
Contemporaneamente verranno lanciati i seguenti allarmi:
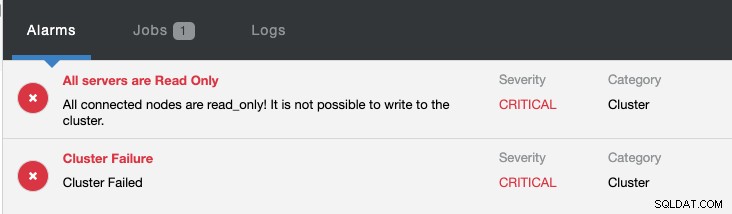
Per ulteriori informazioni su come configurare e gestire il failover della replica MySQL con ClusterControl, consulta Introduzione al failover per la replica MySQL - il blog 101 e il failover automatico della replica MySQL - Novità in ClusterControl 1.4.
Replica in streaming PostgreSQL/TimescaleDB
ClusterControl supporta il ripristino della seguente configurazione di replica PostgreSQL:
- Replica in streaming PostgreSQL
- Replica streaming TimescaleDB
ClusterControl rispetterà i seguenti parametri durante l'esecuzione del ripristino del cluster:
- enable_cluster_autorecovery
- repl_password
- utente_repl
- replica_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Per maggiori dettagli su ciascuno dei parametri, fare riferimento alla pagina della documentazione.
ClusterControl rispetterà le seguenti regole per la gestione e il monitoraggio di una configurazione di replica in streaming PostgreSQL:
- wal_level è impostato su "replica" (o "hot_standby" a seconda della versione di PostgreSQL).
- La variabile archive_mode è impostata su ON sul master.
- Imposta il file recovery.conf sui nodi slave, che trasforma il nodo in hot standby con la sola lettura abilitata.
Nel caso in cui il master attivo si interrompa, ClusterControl tenterà di eseguire il ripristino del cluster nel seguente ordine:
- Dopo 10 secondi di irraggiungibilità del master, ClusterControl lancerà un allarme.
- Dopo 10 secondi di timeout di attesa regolare, ClusterControl avvierà il processo di failover principale.
- Campionare replayLocation e receiveLocation su tutti i nodi disponibili per determinare il nodo più avanzato.
- Promuove il nodo più avanzato come nuovo master.
- Arresta gli schiavi.
- Verifica lo stato di sincronizzazione con pg_rewind.
- Riavvio degli slave con il nuovo master.
- Se la promozione dello slave non riesce, ClusterControl interromperà il processo di ripristino. Per attivare nuovamente il processo di ripristino è necessario l'intervento dell'utente o il riavvio del servizio cmon.
- Quando il vecchio master sarà nuovamente disponibile, sarà costretto a spegnersi e non farà parte della replica. È richiesto l'intervento dell'utente. Vedi più in basso.
Quando il vecchio master torna online, se il servizio PostgreSQL è in esecuzione, ClusterControl forzerà l'arresto del servizio PostgreSQL. Questo serve a proteggere il server da scritture accidentali, poiché verrebbe avviato senza un file di ripristino (recovery.conf), il che significa che sarebbe scrivibile. Dovresti aspettarti che le seguenti righe appaiano in postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL è stato avviato dopo che il server è tornato online intorno alle 05:06:10 ma ClusterControl esegue uno spegnimento rapido 17 secondi dopo che intorno alle 05:06:27. Se questo è qualcosa che non vorresti che fosse, puoi disabilitare momentaneamente il ripristino del nodo per questo cluster.
Consulta Failover automatico di Postgres Replication e Failover per PostgreSQL Replication 101 per ulteriori informazioni su come configurare e gestire il failover della replica PostgreSQL con ClusterControl.
Conclusione
Il ripristino automatico di ClusterControl comprende la topologia del cluster di database ed è in grado di ripristinare un cluster inattivo o degradato in un cluster completamente operativo, migliorando notevolmente il tempo di attività del servizio database. Prova subito ClusterControl e ottieni il massimo in termini di SLA e disponibilità del database. Non conosci i tuoi nove? Dai un'occhiata a questo fantastico calcolatore di nove.



