
Autore ospite:Bert Wagner (@bertwagner)
L'eliminazione dei join è una delle molte tecniche utilizzate da Query Optimizer di SQL Server per creare piani di query efficienti. In particolare, l'eliminazione dei join si verifica quando SQL Server può stabilire l'uguaglianza utilizzando la logica di query o vincoli di database attendibili per eliminare i join non necessari. Guarda una versione video completa di questo post sul mio canale YouTube.
Unisciti all'eliminazione in azione
Il modo più semplice per spiegare l'eliminazione dei join è attraverso una serie di demo. Per questi esempi utilizzerò il database demo di WideWorldImporters.
Per iniziare, vedremo come funziona l'eliminazione dei join quando è presente una chiave esterna:
SELECT il.* FROM Sales.InvoiceLines il INNER JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID;
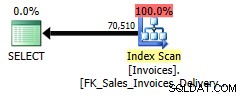
In questo esempio, stiamo restituendo dati solo da Sales.InvoiceLines in cui si trova un InvoiceID corrispondente in Sales.Invoices. Anche se potresti aspettarti che il piano di esecuzione mostri un operatore di join nelle tabelle Sales.InvoiceLines e Sales.Invoices, SQL Server non si preoccupa mai di guardare Sales.Invoices:

SQL Server evita di unirsi alla tabella Sales.Invoices perché considera attendibile l'integrità referenziale gestita dal vincolo di chiave esterna definito in InvoiceID tra Sales.InvoiceLines e Sales.Invoices; se esiste una riga in Sales.InvoiceLines, una riga con il valore corrispondente per InvoiceID deve esistono in Sales.Invoices. E poiché stiamo restituendo solo i dati dalla tabella Sales.InvoiceLines, SQL Server non ha bisogno di leggere alcuna pagina da Sales.Invoices.
Possiamo verificare che SQL Server stia utilizzando il vincolo di chiave esterna per eliminare il join eliminando il vincolo ed eseguendo nuovamente la nostra query:
ALTER TABLE [Sales].[InvoiceLines] DROP CONSTRAINT [FK_Sales_InvoiceLines_InvoiceID_Sales_Invoices];
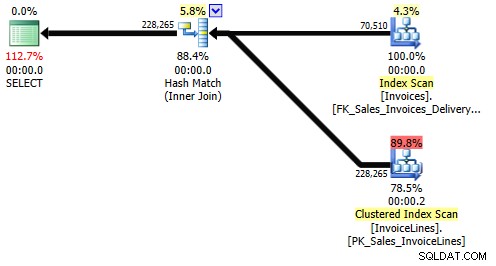
Senza informazioni sulla relazione tra le nostre due tabelle, SQL Server è costretto a eseguire un join, scansionando un indice nella nostra tabella Sales.Invoices per trovare gli InvoiceID corrispondenti.
Dal punto di vista dell'I/O, SQL Server deve leggere altre 124 pagine da un indice nella tabella Sales.Invoices, solo perché è in grado di utilizzare un indice stretto (colonna singola) creato da un diverso vincolo di chiave esterna. Questo scenario potrebbe risultare molto peggiore su tabelle più grandi o non indicizzate in modo appropriato.

Limiti
Sebbene l'esempio precedente mostri le nozioni di base su come funziona l'eliminazione dei join, dobbiamo essere consapevoli di alcuni avvertimenti.
Innanzitutto, aggiungiamo nuovamente il nostro vincolo di chiave esterna:
ALTER TABLE [Sales].[InvoiceLines] WITH NOCHECK ADD CONSTRAINT [FK_Sales_InvoiceLines_InvoiceID_Sales_Invoices] FOREIGN KEY([InvoiceID]) REFERENCES [Sales].[Invoices] ([InvoiceID]);
Se eseguiamo nuovamente la nostra query di esempio, noteremo che non otteniamo un piano che mostra l'eliminazione dei join; invece otteniamo un piano che scansiona entrambe le nostre tabelle unite.
Il motivo per cui ciò si verifica è perché, quando abbiamo aggiunto nuovamente il nostro vincolo di chiave esterna, SQL Server non sa se nel frattempo sono stati modificati dei dati. Eventuali dati nuovi o modificati potrebbero non aderire a questo vincolo, quindi SQL Server non può fidarsi della validità dei nostri dati:
SELECT
f.name AS foreign_key_name
,OBJECT_NAME(f.parent_object_id) AS table_name
,COL_NAME(fc.parent_object_id, fc.parent_column_id) AS constraint_column_name
,OBJECT_NAME (f.referenced_object_id) AS referenced_object
,COL_NAME(fc.referenced_object_id, fc.referenced_column_id) AS referenced_column_name
,f.is_not_trusted
FROM
sys.foreign_keys AS f
INNER JOIN sys.foreign_key_columns AS fc
ON f.object_id = fc.constraint_object_id
WHERE
f.parent_object_id = OBJECT_ID('Sales.InvoiceLines');

Per ristabilire la fiducia di SQL Server in questo vincolo, dobbiamo verificarne la validità:
ALTER TABLE [Sales].[InvoiceLines] WITH CHECK CHECK CONSTRAINT [FK_Sales_InvoiceLines_InvoiceID_Sales_Invoices];
Su tabelle di grandi dimensioni, questa operazione potrebbe richiedere del tempo, per non parlare del sovraccarico di SQL Server che convalida questi dati durante ogni modifica di inserimento/aggiornamento/eliminazione in corso.
Un'altra limitazione è che SQL Server non può eliminare le tabelle unite quando la query deve restituire dati da quei potenziali candidati all'eliminazione:
SELECT il.*, i.InvoiceDate FROM Sales.InvoiceLines il INNER JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID;
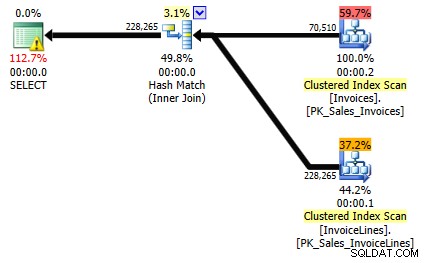
L'eliminazione dei join non si verifica nella query precedente perché stiamo richiedendo che i dati vengano restituiti da Sales.Invoices, costringendo SQL Server a leggere i dati da quella tabella.
Infine, è importante notare che l'eliminazione del join non si verificherà quando la chiave esterna ha più colonne o se le tabelle sono in tempdb. Quest'ultimo è uno dei tanti motivi per cui non dovresti provare a risolvere i problemi di ottimizzazione copiando le tue tabelle in tempdb.
Scenari aggiuntivi
Tabelle multiple
L'eliminazione dei join non si limita solo agli inner join di due tabelle e alle tabelle con vincoli di chiave esterna.
Ad esempio, possiamo creare una tabella aggiuntiva che faccia riferimento alla nostra colonna Sales.Invoices.InvoiceID:
CREATE TABLE Sales.InvoiceClickTracking
(
InvoiceClickTrackingID bigint IDENTITY PRIMARY KEY,
InvoiceID int
-- other fields would go here
);
GO
ALTER TABLE [Sales].[InvoiceClickTracking] WITH CHECK
ADD CONSTRAINT [FK_Sales_InvoiceClickTracking_InvoiceID_Sales_Invoices]
FOREIGN KEY([InvoiceID])
REFERENCES [Sales].[Invoices] ([InvoiceID]); L'unione di questa tabella nella nostra query di esempio originale consentirà inoltre a SQL Server di eliminare la nostra tabella Sales.Invoices:
SELECT il.InvoiceID, ict.InvoiceID FROM Sales.InvoiceLines il INNER JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID INNER JOIN Sales.InvoiceClickTracking ict ON i.InvoiceID = ict.InvoiceID;
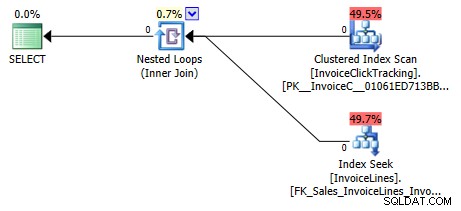
SQL Server può eliminare la tabella Sales.Invoices a causa dell'associazione transitiva tra le relazioni di queste tabelle.
Vincoli unici
Invece di un vincolo di chiave esterna, SQL Server eseguirà anche l'eliminazione dei join se può considerare attendibile la relazione dati con un vincolo univoco:
ALTER TABLE [Sales].[InvoiceClickTracking] DROP CONSTRAINT [FK_Sales_InvoiceClickTracking_InvoiceID_Sales_Invoices]; GO ALTER TABLE Sales.InvoiceClickTracking ADD CONSTRAINT UQ_InvoiceID UNIQUE (InvoiceID); GO SELECT i.InvoiceID FROM Sales.InvoiceClickTracking ict RIGHT JOIN Sales.Invoices i ON ict.InvoiceID = i.InvoiceID;

Unimenti esterni
Finché SQL Server può dedurre i vincoli di relazione, anche altri tipi di join possono subire l'eliminazione delle tabelle. Ad esempio:
SELECT il.InvoiceID FROM Sales.InvoiceLines il LEFT JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID
Poiché abbiamo ancora il nostro vincolo di chiave esterna che impone che ogni InvoiceID in Sales.InvoiceLines debba avere un InvoiceID corrispondente in Sales.Invoices, SQL Server non ha problemi a restituire tutto da Sales.InvoiceLINEs senza la necessità di unirsi a Sales.Invoices:

Nessun vincolo richiesto
Se SQL Server può garantire che non avrà bisogno di dati da una determinata tabella, può potenzialmente eliminare un join.
Non si verifica alcuna eliminazione di join in questa query perché SQL Server non è in grado di identificare se la relazione tra Sales.Invoices e Sales.InvoiceLines è 1 a 1, 1 a 0 o 1 a molti. È obbligato a leggere Sales.InvoiceLines per determinare se vengono trovate righe corrispondenti:
SELECT i.InvoiceID FROM Sales.InvoiceLines il RIGHT JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID;
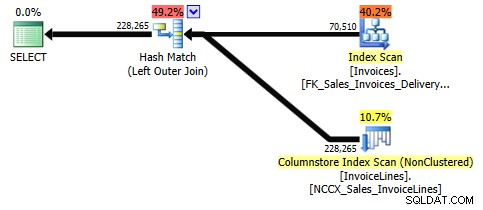
Tuttavia, se specifichiamo di volere un set DISTINCT di i.InvoiceIDs, ogni valore univoco di Sales.Invoices viene restituito da SQL Server indipendentemente dalla relazione che tali righe hanno con Sales.InvoiceLines.
-- Just to prove no foreign key is at play here ALTER TABLE [Sales].[InvoiceLines] DROP CONSTRAINT [FK_Sales_InvoiceLines_InvoiceID_Sales_Invoices]; GO -- Our distinct result set SELECT DISTINCT i.InvoiceID FROM Sales.InvoiceLines il RIGHT JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID;
Viste
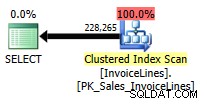
Un vantaggio dell'eliminazione dei join è che può funzionare con le viste, anche se la query della vista sottostante non è in grado di utilizzare l'eliminazione dei join:
-- Add back our FK ALTER TABLE [Sales].[InvoiceLines] WITH CHECK ADD CONSTRAINT [FK_Sales_InvoiceLines_InvoiceID_Sales_Invoices] FOREIGN KEY([InvoiceID]) REFERENCES [Sales].[Invoices] ([InvoiceID]); GO -- Create our view using a query that cannot use join elimination CREATE VIEW Sales.vInvoicesAndInvoiceLines AS SELECT i.InvoiceID, i.InvoiceDate, il.Quantity, il.TaxRate FROM Sales.InvoiceLines il INNER JOIN Sales.Invoices i ON il.InvoiceID = i.InvoiceID; GO -- Join elimination works because we do not select any -- columns from the underlying Sales.Invoices table SELECT Quantity, TaxRate FROM Sales.vInvoicesAndInvoiceLines;
Conclusione
L'eliminazione dei join è un'ottimizzazione eseguita da SQL Server quando determina che può fornire un set di risultati accurato senza dover leggere i dati da tutte le tabelle specificate nella query inviata. Questa ottimizzazione può fornire miglioramenti significativi delle prestazioni riducendo il numero di pagine che SQL Server deve leggere, tuttavia spesso va a scapito della necessità di mantenere determinati vincoli del database. Possiamo refactoring delle query per ottenere i piani di esecuzione più semplici forniti dall'eliminazione dei join, tuttavia avere Query Optimizer semplifichi automaticamente i nostri piani rimuovendo i join non necessari è un bel vantaggio.
Ancora una volta, ti invito a guardare la versione video completa di questo post.
Informazioni sull'autore
 Bert è uno sviluppatore di business intelligence di Cleveland, Ohio. Ama scrivere query rapide e gli piace aiutare gli altri a imparare a essere risolutori di problemi SQL autosufficienti. Bert scrive su SQL Server su bertwagner.com e crea video YouTube di SQL Server su youtube.com/c/bertwagner.
Bert è uno sviluppatore di business intelligence di Cleveland, Ohio. Ama scrivere query rapide e gli piace aiutare gli altri a imparare a essere risolutori di problemi SQL autosufficienti. Bert scrive su SQL Server su bertwagner.com e crea video YouTube di SQL Server su youtube.com/c/bertwagner. 


