La gestione di un'installazione di PostgreSQL implica l'ispezione e il controllo su un'ampia gamma di aspetti nello stack software/infrastruttura su cui viene eseguito PostgreSQL. Questo deve coprire:
- Ottimizzazione dell'applicazione relativa all'utilizzo/transazioni/connessioni del database
- Codice database (query, funzioni)
- Sistema di database (prestazioni, HA, backup)
- Hardware/Infrastruttura (dischi, CPU/Memoria)
Il core di PostgreSQL fornisce il livello di database su cui confidiamo che i nostri dati vengano archiviati, elaborati e serviti. Fornisce inoltre tutta la tecnologia per avere un sistema veramente moderno, efficiente, affidabile e sicuro. Ma spesso questa tecnologia non è disponibile come prodotto raffinato e pronto per l'uso di classe business/enterprise nella distribuzione principale di PostgreSQL. Invece, ci sono molti prodotti/soluzioni della comunità PostgreSQL o offerte commerciali che soddisfano tali esigenze. Tali soluzioni vengono fornite come perfezionamenti di facile utilizzo delle tecnologie di base, o estensioni delle tecnologie di base o anche come integrazione tra i componenti PostgreSQL e altri componenti del sistema. Nel nostro precedente blog intitolato Dieci consigli per entrare in produzione con PostgreSQL, abbiamo esaminato alcuni di quegli strumenti che possono aiutare a gestire un'installazione di PostgreSQL in produzione. In questo blog esploreremo più in dettaglio gli aspetti che devono essere trattati quando si gestisce un'installazione di PostgreSQL in produzione e gli strumenti più comunemente utilizzati a tale scopo. Tratteremo i seguenti argomenti:
- Distribuzione
- Gestione
- Ridimensionamento
- Monitoraggio
Distribuzione
In passato, le persone scaricavano e compilavano PostgreSQL a mano, quindi configuravano i parametri di runtime e il controllo dell'accesso degli utenti. Ci sono ancora alcuni casi in cui ciò potrebbe essere necessario, ma quando i sistemi sono maturati e hanno iniziato a crescere, è emersa la necessità di modi più standardizzati per distribuire e gestire Postgresql. La maggior parte dei sistemi operativi fornisce pacchetti per installare, distribuire e gestire i cluster PostgreSQL. Debian ha standardizzato il proprio layout di sistema supportando molte versioni di Postgresql e molti cluster per versione contemporaneamente. Il pacchetto debian postgresql-common fornisce gli strumenti necessari. Ad esempio, per creare un nuovo cluster (chiamato i18n_cluster) per PostgreSQL versione 10 in Debian, possiamo farlo dando i seguenti comandi:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsQuindi aggiorna systemd:
$ sudo systemctl daemon-reloade infine avvia e utilizza il nuovo cluster:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(notare che Debian gestisce diversi cluster utilizzando diverse porte 5432, 5433 e così via)
Con l'aumento della necessità di implementazioni più automatizzate e massicce, sempre più installazioni utilizzano strumenti di automazione come Ansible, Chef e Puppet. Oltre all'automazione e alla riproducibilità delle distribuzioni, gli strumenti di automazione sono ottimi perché rappresentano un ottimo modo per documentare la distribuzione e la configurazione di un cluster. D'altra parte, l'automazione si è evoluta fino a diventare un vasto campo a sé stante, che richiede persone qualificate per scrivere, gestire ed eseguire script automatizzati. Maggiori informazioni sul provisioning PostgreSQL sono disponibili in questo blog:Diventa un DBA PostgreSQL:Provisioning and Deployment.
Gestione
La gestione di un sistema attivo comporta attività quali:pianificazione dei backup e monitoraggio del loro stato, ripristino di emergenza, gestione della configurazione, gestione dell'elevata disponibilità e gestione automatica del failover. Il backup di un cluster Postgresql può essere eseguito in vari modi. Strumenti di basso livello:
- pg_dump tradizionale (backup logico)
- backup a livello di file system (backup fisico)
- pg_basebackup (backup fisico)
O di livello superiore:
- Barista
- PgBackRest
Ciascuno di questi modi copre diversi casi d'uso e scenari di ripristino e varia in complessità. Il backup di PostgreSQL è strettamente correlato alle nozioni di PITR, archiviazione e replica WAL. Nel corso degli anni la procedura di acquisizione, test e infine (incrociamo le dita!) Utilizzando i backup con PostgreSQL si è evoluta fino a diventare un compito complesso. Si può trovare una bella panoramica delle soluzioni di backup per PostgreSQL in questo blog:I migliori strumenti di backup per PostgreSQL.
Per quanto riguarda l'elevata disponibilità e il failover automatico, il minimo indispensabile che un'installazione deve avere per implementarlo è:
- Una primaria attiva
- Un WAL che accetta hot standby trasmesso in streaming dal primario
- In caso di errore primario, un metodo per dire al primario che non è più il primario (a volte chiamato STONITH)
- Un meccanismo heartbeat per verificare la connettività tra i due server e l'integrità del server primario
- Un metodo per eseguire il failover (ad es. tramite pg_ctl promote o trigger file)
- Una procedura automatizzata per ricreare il vecchio primario come nuovo standby:una volta rilevata un'interruzione o un guasto sul primario, allora uno standby deve essere promosso come nuovo primario. La vecchia primaria non è più valida o utilizzabile. Quindi il sistema deve disporre di un modo per gestire questo stato tra il failover e la ricreazione del vecchio server primario come nuovo standby. Questo stato è chiamato stato degenerato e PostgreSQL fornisce uno strumento chiamato pg_rewind per accelerare il processo di riportare il vecchio primario allo stato sincronizzabile dal nuovo primario.
- Un metodo per eseguire passaggi su richiesta/pianificati
Uno strumento ampiamente utilizzato che gestisce tutto quanto sopra è Repmgr. Descriveremo la configurazione minima che consentirà un passaggio di successo. Iniziamo con un PostgreSQL 10.4 primario funzionante in esecuzione su FreeBSD 11.1, costruito e installato manualmente, e repmgr 4.0 anch'esso compilato e installato manualmente per questa versione (10.4). Useremo due host chiamati fbsd (192.168.1.80) e fbsdclone (192.168.1.81) con versioni identiche di PostgreSQL e repmgr. Sul primary (inizialmente fbsd , 192.168.1.80) ci assicuriamo che siano impostati i seguenti parametri PostgreSQL:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Quindi creiamo l'utente repmgr (come superutente) e il database:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgre configurare il controllo dell'accesso basato sull'host in pg_hba.conf inserendo le seguenti righe in alto:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustCi assicuriamo di configurare l'accesso senza password per l'utente repmgr in tutti i nodi del cluster, nel nostro caso fbsd e fbsdclone impostando authorized_keys in .ssh e quindi condividendo .ssh. Quindi creiamo repmrg.conf sul primario come:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Quindi registriamo il primario:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredE controlla lo stato del cluster:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Ora lavoriamo in standby impostando repmgr.conf come segue:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Inoltre ci assicuriamo che la directory dei dati specificata nella riga sopra esista, sia vuota e abbia i permessi corretti:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataOra dobbiamo clonare nel nostro nuovo standby:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"E avvia lo standby:
example@sqldat.com:~ % pg_ctl -D data startA questo punto la replica dovrebbe funzionare come previsto, verificarlo interrogando pg_stat_replication (fbsd) e pg_stat_wal_receiver (fbsdclone). Il prossimo passo è registrare lo standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerOra possiamo ottenere lo stato del cluster sia sullo standly che sul primary e verificare che lo standby sia registrato:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Supponiamo ora di voler eseguire un passaggio manuale programmato per es. per fare un po' di lavoro di amministrazione su node fbsd. Sul nodo standby, eseguiamo il seguente comando:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyIl passaggio è stato eseguito con successo! Vediamo cosa offre il cluster show:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2I due server si sono scambiati i ruoli! Repmgr fornisce il daemon repmgrd che fornisce monitoraggio, failover automatico e notifiche/avvisi. Combinando repmgrd con pgbouncer, è possibile implementare l'aggiornamento automatico delle informazioni di connessione del database, fornendo così un fencing per il primario guasto (impedendo al nodo guasto qualsiasi utilizzo da parte dell'applicazione) oltre a fornire tempi di inattività minimi per l'applicazione. In schemi più complessi un'altra idea è combinare Keepalived con HAProxy oltre a pgbouncer e repmgr, al fine di ottenere:
- bilanciamento del carico (ridimensionamento)
- alta disponibilità
Si noti che ClusterControl gestisce anche il failover delle configurazioni di replica PostgreSQL e integra HAProxy e VirtualIP per reindirizzare automaticamente le connessioni client al master funzionante. Ulteriori informazioni sono disponibili in questo whitepaper su PostgreSQL Automation.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperRidimensionamento
A partire da PostgreSQL 10 (e 11) non c'è ancora modo di avere la replica multi-master, almeno non dal core PostgreSQL. Ciò significa che solo l'attività di selezione (sola lettura) può essere aumentata. Il ridimensionamento in PostgreSQL si ottiene aggiungendo più hot standby, fornendo così più risorse per l'attività di sola lettura. Con repmgr è facile aggiungere un nuovo standby, come abbiamo visto in precedenza tramite standby clone e registrazione in standby comandi. Gli standby aggiunti (o rimossi) devono essere resi noti alla configurazione del bilanciamento del carico. HAProxy, come menzionato sopra nell'argomento di gestione, è un popolare sistema di bilanciamento del carico per PostgreSQL. Di solito è accoppiato con Keepalived che fornisce IP virtuale tramite VRRP. Una bella panoramica sull'utilizzo di HAProxy e Keepalived insieme a PostgreSQL può essere trovata in questo articolo:PostgreSQL Load Balancing Using HAProxy &Keepalived.
Monitoraggio
Una panoramica di cosa monitorare in PostgreSQL è disponibile in questo articolo:Cose chiave da monitorare in PostgreSQL:analisi del carico di lavoro. Esistono molti strumenti in grado di fornire il monitoraggio del sistema e postgresql tramite plug-in. Alcuni strumenti coprono l'area della presentazione del grafico dei valori storici (munin), altri strumenti coprono l'area del monitoraggio dei dati in tempo reale e forniscono avvisi in tempo reale (nagios), mentre alcuni strumenti coprono entrambe le aree (zabbix). Un elenco di tali strumenti per PostgreSQL può essere trovato qui:https://wiki.postgresql.org/wiki/Monitoring. Uno strumento popolare per il monitoraggio offline (basato su file di registro) è pgBadger. pgBadger è uno script Perl che funziona analizzando il log di PostgreSQL (che di solito copre l'attività di un giorno), estraendo informazioni, calcolando statistiche e infine producendo una pagina html di fantasia che presenta i risultati. pgBadger non è restrittivo sull'impostazione log_line_prefix, potrebbe adattarsi al tuo formato già esistente. Ad esempio, se hai impostato nel tuo postgresql.conf qualcosa come:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'quindi il comando pgbadger per analizzare il file di registro e produrre i risultati potrebbe essere simile a:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger fornisce rapporti per:
- Panoramica delle statistiche (per lo più traffico SQL)
- Connessioni (al secondo, per database/utente/host)
- Sessioni (numero, tempi di sessione, per database/utente/host/applicazione)
- Punti di controllo (buffer, file wal, attività)
- Utilizzo dei file temporanei
- Attività di vuoto/analisi (per tabella, tuple/pagine rimosse)
- Blocca
- Query (per tipo/database/utente/host/applicazione, durata per utente)
- Top (query:più lenta, che richiede tempo, più frequente, normalizzata più lenta)
- Eventi (Errori, Avvisi, Fatal, ecc.)
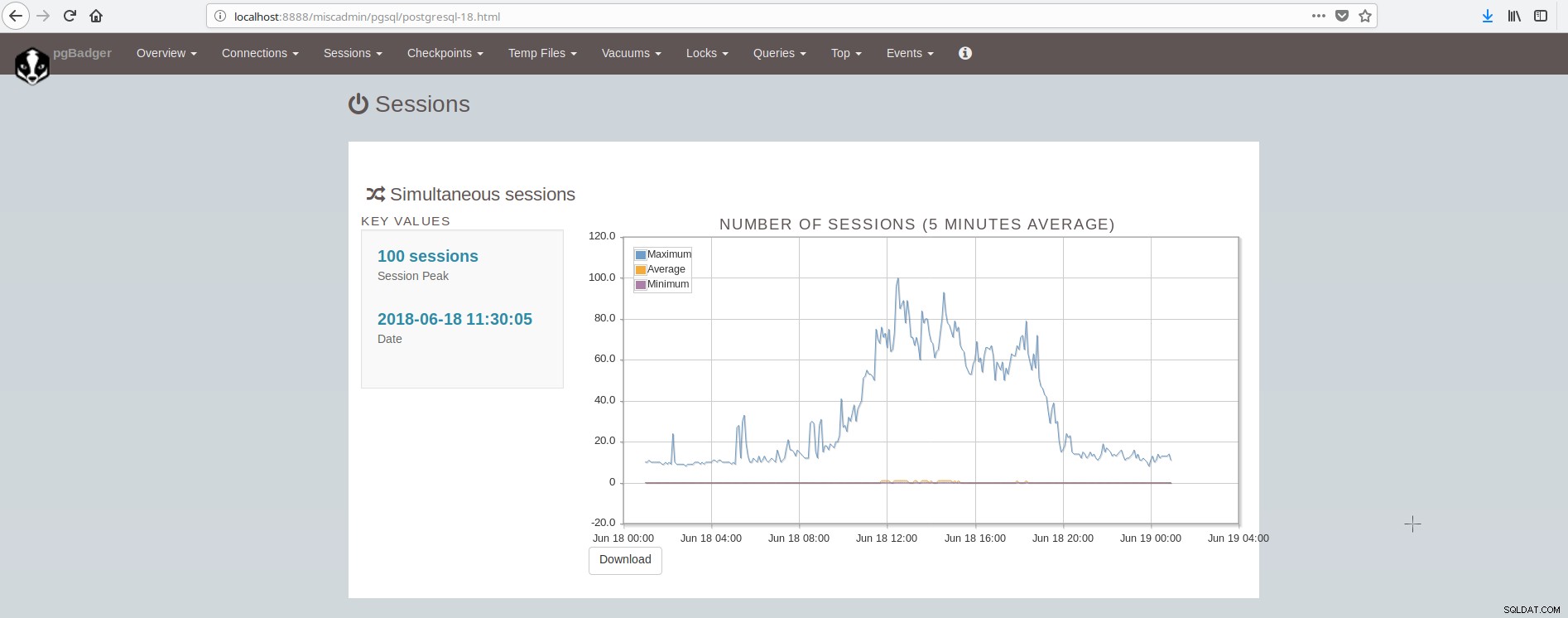
La schermata che mostra le sessioni è simile a:
Come possiamo concludere, l'installazione media di PostgreSQL deve integrare e prendersi cura di molti strumenti per avere un'infrastruttura moderna, affidabile e veloce e questo è abbastanza complesso da ottenere, a meno che non ci siano grandi team coinvolti in postgresql e nell'amministrazione del sistema. Una bella suite che fa tutto quanto sopra e altro è ClusterControl.