Le principali modifiche apportate alla stima della cardinalità a partire dalla versione di SQL Server 2014 sono descritte nel white paper di Microsoft Ottimizzazione dei piani di query con lo strumento per la stima della cardinalità di SQL Server 2014 di Joe Sack, Yi Fang e Vassilis Papadimos.
Una di queste modifiche riguarda la stima dei unioni semplici con un singolo predicato di uguaglianza o disuguaglianza utilizzando istogrammi statistici. Nella sezione intitolata "Join Estimate Algorithm Changes", il documento ha introdotto il concetto di "allineamento grossolano" utilizzando i limiti minimi e massimi dell'istogramma:
Per i join con un singolo predicato di uguaglianza o disuguaglianza, il CE legacy unisce gli istogrammi sulle colonne di join allineando i due istogrammi passo dopo passo utilizzando l'interpolazione lineare. Questo metodo potrebbe comportare stime di cardinalità incoerenti. Pertanto, il nuovo CE ora utilizza un algoritmo di stima del join più semplice che allinea gli istogrammi utilizzando solo i limiti minimi e massimi dell'istogramma.Sebbene potenzialmente meno coerente, il CE legacy può produrre stime delle condizioni di unione semplice leggermente migliori a causa dell'allineamento dell'istogramma passo dopo passo. Il nuovo CE utilizza un allineamento grossolano. Tuttavia, la differenza nelle stime potrebbe essere abbastanza piccola da causare meno problemi di qualità del piano.
Come uno dei revisori tecnici dell'articolo, ho ritenuto che un po' più di dettagli su questo cambiamento sarebbe stato utile, ma questo non è arrivato alla versione finale. Questo articolo aggiunge alcuni di questi dettagli.
Esempio di allineamento dell'istogramma grossolano
L'allineamento grossolano esempio nel White Paper utilizza la versione Data Warehouse del database di esempio AdventureWorks. Nonostante il nome, il database è piuttosto piccolo; il backup è di soli 22,3 MB e si espande a circa 200 MB. Può essere scaricato tramite i collegamenti nella pagina della documentazione relativa all'installazione e alla configurazione di AdventureWorks.
La query che ci interessa si unisce a FactResellerSales e FactCurrencyRate tabelle.
SELECT
FRS.ProductKey,
FRS.OrderDateKey,
FRS.DueDateKey,
FRS.ShipDateKey,
FCR.DateKey,
FCR.AverageRate,
FCR.EndOfDayRate,
FCR.[Date]
FROM dbo.FactResellerSales AS FRS
JOIN dbo.FactCurrencyRate AS FCR
ON FCR.CurrencyKey = FRS.CurrencyKey; Questo è un semplice equijoin su una singola colonna quindi si qualifica per la stima della cardinalità e della selettività dell'unione utilizzando l'allineamento grossolano dell'istogramma.
Istogrammi
Gli istogrammi di cui abbiamo bisogno sono associati al CurrencyKey colonna su ogni tabella unita. In una nuova copia del database AdventureWorksDW, le statistiche preesistenti per il più grande FactResellerSales tabella sono basati su un campione. Per massimizzare la riproducibilità e rendere i calcoli dettagliati il più semplici possibile da seguire (evitando il ridimensionamento), la prima cosa che faremo è aggiornare le statistiche utilizzando una scansione completa:
UPDATE STATISTICS dbo.FactCurrencyRate WITH FULLSCAN; UPDATE STATISTICS dbo.FactResellerSales WITH FULLSCAN;
Queste tabelle hanno il vantaggio demo-friendly di creare maxdiff piccoli e semplici istogrammi:
DBCC SHOW_STATISTICS
(FactResellerSales, CurrencyKey)
WITH HISTOGRAM;
DBCC SHOW_STATISTICS
(FactCurrencyRate, [PK_FactCurrencyRate_CurrencyKey_DateKey])
WITH HISTOGRAM;
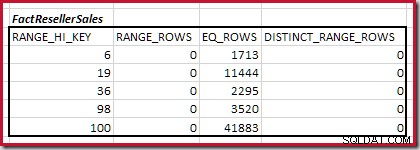
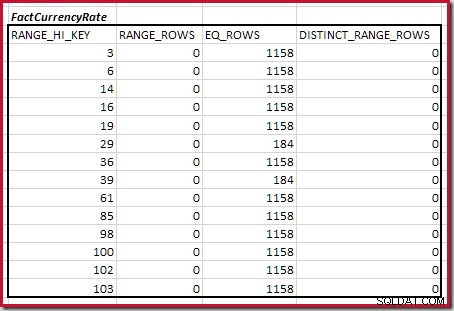
Combinazione di passaggi dell'istogramma di corrispondenza minima
Il primo passo nell'allineamento grossolano il calcolo consiste nel trovare il contributo alla cardinalità del join fornito dal passaggio dell'istogramma di corrispondenza più basso. Per i nostri istogrammi di esempio, il valore del passaggio di corrispondenza minimo è su RANGE_HI_KEY = 6 :
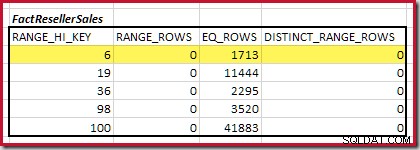
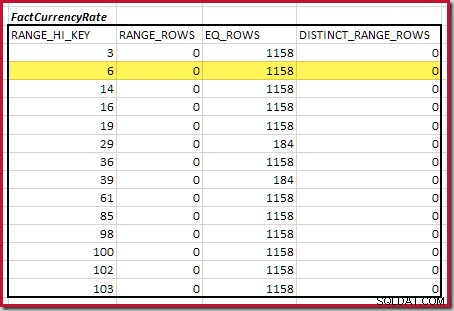
La cardinalità equijoin stimata solo per questo passaggio evidenziato è 1.713 * 1.158 =1.983.654 righe .
Passi corrispondenti rimanenti
Successivamente, dobbiamo identificare l'intervallo dell'istogramma RANGE_HI_KEY aumenta al massimo per possibili partite di equijoin. Ciò comporta l'avanzamento dal minimo trovato in precedenza fino a quando uno degli input dell'istogramma esaurisce le righe. Gli intervalli equijoin corrispondenti per l'esempio corrente sono evidenziati di seguito:
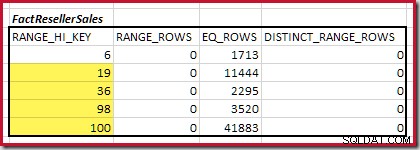
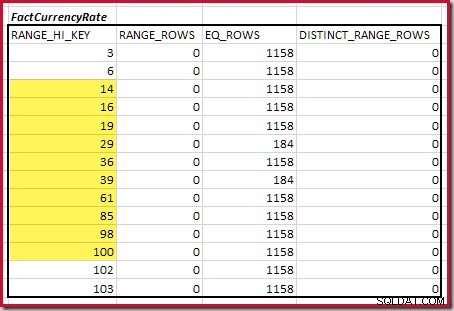
Questi due intervalli rappresentano le righe rimanenti che potrebbero contribuire alla cardinalità di equigiunzione.
Stima basata sulla frequenza grossolana
La domanda ora è come eseguire una grossolana stima della cardinalità equijoin dei passaggi evidenziati, utilizzando le informazioni disponibili.
Lo stimatore di cardinalità originale avrebbe eseguito un allineamento dell'istogramma passo-passo a grana fine utilizzando l'interpolazione lineare, valutato il contributo di unione di ogni passo (proprio come abbiamo fatto per il valore del passo minimo prima) e sommato ogni contributo di passo per acquisire un preventivo di adesione completo. Sebbene questa procedura abbia molto senso intuitivo, l'esperienza pratica è stata che questo approccio a grana fine aggiungeva un sovraccarico computazionale e poteva produrre risultati di qualità variabile.
Lo stimatore originale aveva un altro modo per stimare la cardinalità dei join quando le informazioni sull'istogramma non erano disponibili o valutate euristicamente come inferiori. Questa è nota come stima basata sulla frequenza e utilizza le seguenti definizioni:
- C – la cardinalità (numero di righe)
- D – il numero di valori distinti
- F – la frequenza (numero di righe) per ogni valore distinto
- Nota C =D * F per definizione
L'effetto di un equijoin delle relazioni R1 e R2 su ciascuna di queste proprietà è il seguente:
- F' =F1 * F2
- D' =MIN(D1; D2) – assumendo il contenimento
- C' =D' * F' (di nuovo, per definizione)
Siamo dopo C', la cardinalità dell'equijoin. Sostituendo D' e F' nella formula ed espandendo:
- C' =RE' * FA'
- C' =MIN(D1; D2) * F1 * F2
- C' =MIN(D1 * F1 * F2; D2 * F1 * F2)
- ora, poiché C1 =D1 * F1 e C2 =D2 * F2:
- C' =MIN(C1 * F2, C2 * F1)
- infine, poiché F =C/D (anche per definizione):
- C' =MIN(C1 * C2 / D2; C2 * C1 / RE1)
Notando che C1 * C2 è il prodotto delle due cardinalità di input (cartesiano join), è chiaro che il minimo di tali espressioni sarà quello con il maggior numero di valori distinti:
- C' =(C1 * C2) / MAX(D1; D2)
Nel caso in cui tutto ciò sembri un po' astratto, un modo intuitivo per pensare alla stima dell'equigiunzione basata sulla frequenza è considerare che ogni valore distinto da una relazione si unirà con un numero di righe (la frequenza media) nell'altra relazione. Se abbiamo 5 valori distinti su un lato, e ogni valore distinto sull'altro lato appare in media 3 volte, una stima equijoin ragionevole (ma grossolana) è 5 * 3 =15.
Questo non è un pennello così ampio come potrebbe sembrare. Ricorda che la cardinalità e i valori distinti numeri sopra non provengono dall'intera relazione, ma solo dai passaggi di corrispondenza sopra il minimo. Da qui una stima grossolana tra valori minimo e massimo.
Calcolo della frequenza
Possiamo ottenere ciascuno di questi parametri dai passaggi dell'istogramma evidenziati.
- La cardinalità C è la somma di
EQ_ROWSeRANGE_ROWS. - Il numero di valori distinti D è la somma di
DISTINCT_RANGE_ROWSpiù uno per ogni passaggio.
La cardinalità C1 della corrispondenza di FactResellerSales passi è la somma delle celle evidenziate:
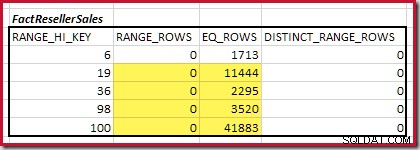
Questo dà C1 =59.142 righe.
Non ci sono righe di intervallo distinte, quindi gli unici valori distinti provengono dai limiti dei quattro passaggi stessi, dando D1 =4 .
Per la seconda tabella:
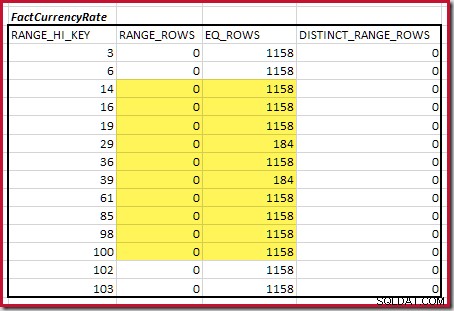
Questo dà C2 =9.632 . Anche in questo caso non ci sono righe di intervallo distinte, quindi i valori distinti provengono dai limiti dei dieci passaggi, D2 =10.
Completamento della stima dell'equijoin
Ora abbiamo tutti i numeri di cui abbiamo bisogno per la formula equijoin:
- C' =(C1 * C2) / MAX(D1; D2)
- C' =(59142 * 9632) / MAX(4; 10)
- C' =569655744 / 10
- C' =56.965.574,4
Ricorda, questo è il contributo dei passaggi dell'istogramma al di sopra del limite minimo corrispondente. Per completare la stima della cardinalità del join, dobbiamo aggiungere il contributo dei valori minimi del passaggio di corrispondenza, che era 1.713 * 1.158 =1.983.654 righe.
La stima finale dell'equijoin è quindi 56.965.574,4 + 1.983.654 =58.949.228,4 righe o 58.949.200 a sei cifre significative.
Questo risultato è confermato nel piano di esecuzione stimato per la query di origine:
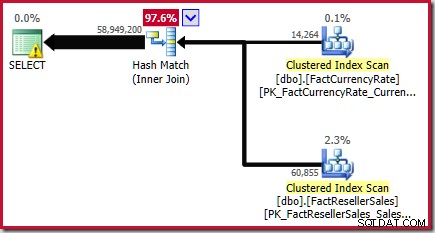
Come indicato nel Libro bianco, questa non è una stima ottimale. Il numero effettivo di righe restituite da questa query è 70.470.090 . La stima prodotta dallo stimatore di cardinalità ("legacy") originale, utilizzando l'allineamento dell'istogramma passo dopo passo, è di 70.470.100 righe.
Risultati migliori sono spesso possibili con il metodo più fine, ma solo se le statistiche sono un'ottima rappresentazione della distribuzione dei dati sottostante. Non si tratta semplicemente di mantenere aggiornate le statistiche o di utilizzare la popolazione di scansione completa. L'algoritmo utilizzato per racchiudere le informazioni in un massimo di 201 passaggi dell'istogramma non è perfetto e, in ogni caso, molte distribuzioni di dati del mondo reale semplicemente non sono in grado di garantire tale fedeltà dell'istogramma. In media, le persone dovrebbero scoprire che il metodo più grossolano fornisce stime perfettamente adeguate e una maggiore stabilità con il nuovo CE.
Secondo esempio
Questo si basa un po' sull'esempio precedente e non richiede il download di un database di esempio.
DROP TABLE IF EXISTS
dbo.R1,
dbo.R2;
CREATE TABLE dbo.R1 (n integer NOT NULL);
CREATE TABLE dbo.R2 (n integer NOT NULL);
INSERT dbo.R1
(n)
VALUES
(1), (2), (3), (4), (5), (6), (7), (8), (9), (10),
(6), (6), (6), (6), (6), (6), (6), (6), (6), (6),
(6), (6), (6), (6), (6), (6), (6), (6), (6);
INSERT dbo.R2
(n)
VALUES
(5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15),
(10), (10);
CREATE STATISTICS stats_n ON dbo.R1 (n) WITH FULLSCAN;
CREATE STATISTICS stats_n ON dbo.R2 (n) WITH FULLSCAN; Gli istogrammi che mostrano i passaggi minimi corrispondenti sono:
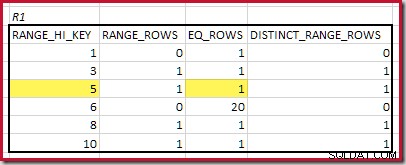
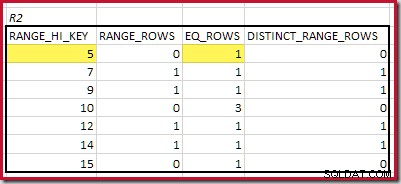
Il RANGE_HI_KEY più basso che corrisponde è 5. Il valore di EQ_ROWS è 1 in entrambi, quindi la cardinalità equijoin stimata è 1 * 1 =1 riga .
Il RANGE_HI_KEY più alto corrispondente è 10. Evidenziazione delle righe dell'istogramma R1 per una stima grossolana basata sulla frequenza:
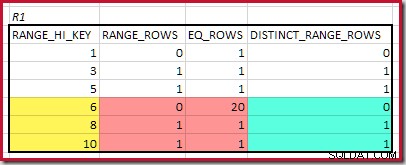
Sommando EQ_ROWS e RANGE_ROWS dà C1 =24 . Il numero di righe distinte è 2 DISTINCT_RANGE_ROWS (valori distinti tra i passaggi) più 3 per i valori distinti associati a ciascun limite del passaggio, dando D1 =5 .
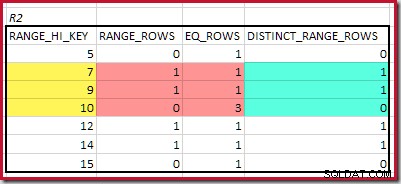
Per R2, sommando EQ_ROWS e RANGE_ROWS dà C2 =7 . Il numero di righe distinte è 2 DISTINCT_RANGE_ROWS (valori distinti tra passaggi) più 3 per i valori distinti associati a ciascun limite di passaggio, dando D2 =5 .
La stima equijoin C' è:
- C' =(C1 * C2) / MAX(D1; D2)
- C' =(24 * 7) / 5
- C' =33,6
Aggiunta nella 1 riga dalla corrispondenza del passaggio minimo fornisce una stima totale di 34,6 righe per l'equijoin:
SELECT
R1.n,
R2.n
FROM dbo.R1 AS R1
JOIN dbo.R2 AS R2
ON R2.n = R1.n; Il piano di esecuzione stimato mostra una stima che corrisponde al nostro calcolo:

Questo non è esattamente corretto, ma lo stimatore di cardinalità "legacy" non fa di meglio, stimando 15,25 righe contro 27 effettive:

Per un trattamento completo, dovremmo anche aggiungere un contributo finale dalla corrispondenza dei passi nulli dell'istogramma, ma questo è raro per gli equijoin (che sono tipicamente scritti per rifiutare i valori nulli) e un'estensione relativamente semplice per il lettore interessato.
Pensieri finali
Si spera che i dettagli nell'articolo colmino alcune lacune per chiunque si sia mai chiesto un "allineamento grossolano". Si noti che questa è solo una piccola componente nello stimatore di cardinalità. Esistono molti altri concetti e algoritmi importanti utilizzati per la stima dei join, in particolare il modo in cui vengono valutati i predicati non-join e come vengono gestiti i join più complessi. Molte delle parti veramente importanti sono trattate abbastanza bene nel Libro bianco.