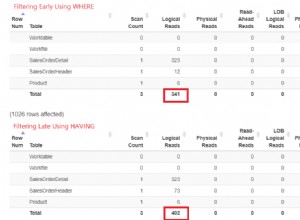
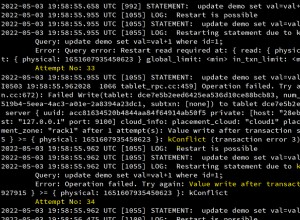
È possibile risolvere il problema forzando le regole di confronto utilizzate in una query in modo che siano regole di confronto particolari, ad es. SQL_Latin1_General_CP1_CI_AS o DATABASE_DEFAULT . Ad esempio:
SELECT MyColumn
FROM FirstTable a
INNER JOIN SecondTable b
ON a.MyID COLLATE SQL_Latin1_General_CP1_CI_AS =
b.YourID COLLATE SQL_Latin1_General_CP1_CI_AS
Nella query precedente, a.MyID e b.YourID sarebbero colonne con un tipo di dati basato su testo. Usando COLLATE forzerà la query a ignorare le regole di confronto predefinite sul database e utilizzare invece le regole di confronto fornite, in questo caso SQL_Latin1_General_CP1_CI_AS .
Fondamentalmente quello che sta succedendo qui è che ogni database ha le proprie regole di confronto che "forniscono regole di ordinamento, proprietà di distinzione tra maiuscole e minuscole e accenti per i tuoi dati" (da https://technet.microsoft.com/en-us/library/ms143726.aspx ) e si applica alle colonne con tipi di dati testuali , per esempio. VARCHAR , CHAR , NVARCHAR , ecc. Quando due database hanno regole di confronto diverse, non è possibile confrontare le colonne di testo con un operatore come uguale (=) senza affrontare il conflitto tra le due regole di confronto disparate.