In questo post, discuteremo il meccanismo di blocco di SQL Server e come monitorare il blocco di SQL Server con le viste a gestione dinamica standard di SQL Server. Prima di iniziare a spiegare l'architettura di blocco di SQL Server, prendiamoci un momento per descrivere cos'è il database ACID (Atomicity, Consistency, Isolation, and Durability). Il database ACID può essere spiegato come teoria del database. Se un database è chiamato database relazionale, deve soddisfare i requisiti di Atomicità, Coerenza, Isolamento e Durabilità. Ora spiegheremo brevemente questi requisiti.
Atomicità :Riflette il principio di indivisibilità che descriviamo come la caratteristica principale del processo di transazione. Un blocco di transazione non può essere lasciato incustodito. La metà del blocco di transazione rimanente causa l'incoerenza dei dati. O viene eseguita l'intera transazione o la transazione torna all'inizio. Cioè, tutte le modifiche apportate dalla transazione vengono annullate e riportate allo stato precedente.
Coerenza :Esiste una regola che stabilisce la sottostruttura della regola di non divisibilità. I dati della transazione devono fornire coerenza. In altre parole, se l'operazione di aggiornamento viene eseguita in una transazione, è necessario eseguire tutte le transazioni rimanenti oppure annullare l'operazione di aggiornamento. Questi dati sono molto importanti in termini di coerenza.
Isolamento :Questo è un pacchetto di richiesta per ogni database di transazione. Le modifiche apportate da un pacchetto di richiesta devono essere visibili a un'altra transazione prima che sia completata. Ogni transazione deve essere elaborata separatamente. Tutte le transazioni devono essere visibili a un'altra transazione dopo che si sono verificate.
Durata: Le transazioni possono eseguire operazioni complesse con i dati. Per proteggere tutte queste transazioni, devono essere resistenti a un errore di transazione. I problemi di sistema che possono verificarsi in SQL Server devono essere preparati e resilienti contro interruzioni di corrente, sistema operativo o altri errori indotti dal software.
Transazione: La transazione è la pila più piccola del processo che non può essere divisa in parti più piccole. Inoltre, alcuni gruppi di processi di transazione possono essere eseguiti in sequenza ma, come spiegato nel principio dell'atomicità, se anche una delle transazioni fallisce, tutti i blocchi di transazione falliranno.
Blocco: Il blocco è un meccanismo per garantire la coerenza dei dati. SQL Server blocca gli oggetti all'avvio della transazione. Al termine della transazione, SQL Server rilascia l'oggetto bloccato. Questa modalità di blocco può essere modificata in base al tipo di processo di SQL Server e al livello di isolamento. Queste modalità di blocco sono:
Blocca gerarchia: SQL Server ha una gerarchia di blocchi che acquisisce gli oggetti di blocco in questa gerarchia. Un database si trova in cima alla gerarchia e una riga in fondo. L'immagine seguente illustra la gerarchia dei blocchi di SQL Server.

Blocchi condivisi (S): Questo tipo di blocco si verifica quando l'oggetto deve essere letto. Questo tipo di blocco non causa molti problemi.
Lucchetti esclusivi (X): Quando si verifica questo tipo di blocco, si verifica per impedire ad altre transazioni di modificare o accedere a un oggetto bloccato.
Aggiorna (U) blocchi: Questo tipo di blocco è simile al blocco esclusivo ma presenta alcune differenze. Possiamo suddividere l'operazione di aggiornamento in diverse fasi:fase di lettura e fase di scrittura. Durante la fase di lettura, SQL Server non desidera che altre transazioni abbiano accesso a questo oggetto da modificare. Per questo motivo, SQL Server utilizza il blocco degli aggiornamenti.
Blocchi di intenti: Il blocco dell'intento si verifica quando SQL Server desidera acquisire il blocco condiviso (S) o il blocco esclusivo (X) su alcune delle risorse inferiori nella gerarchia dei blocchi. In pratica, quando SQL Server acquisisce un blocco su una pagina o riga, nella tabella è richiesto il blocco dell'intento.
Dopo tutte queste brevi spiegazioni, cercheremo di trovare una risposta su come identificare le serrature. SQL Server offre molte viste a gestione dinamica per accedere alle metriche. Per identificare i blocchi di SQL Server, possiamo utilizzare sys.dm_tran_locks Visualizza. In questa visualizzazione, possiamo trovare molte informazioni sulle risorse di gestione dei blocchi attualmente attive.
Nel primo esempio creeremo una tabella demo che non include indici e proveremo ad aggiornare questa tabella demo.
CREATE TABLE TestBlock(Id INT ,Nm VARCHAR(100))INSERT INTO TestBlockvalues(1,'CodingSight')In questo passaggio creeremo una transazione aperta e analizzeremo le risorse bloccate.BEGIN TRANUPDATE TestBlock SET Nm='NewValue_CodingSight ' dove Id=1seleziona @@SPID
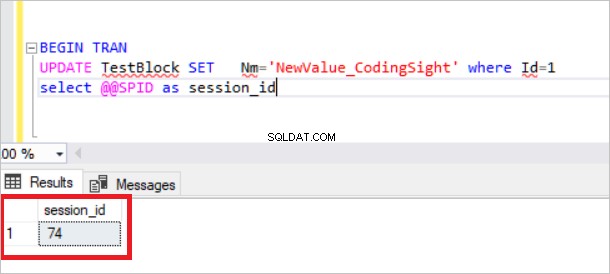
Ora controlleremo la vista sys.dm_tran_lock.
seleziona * da sys.dm_tran_locks DOVE request_session_id=74
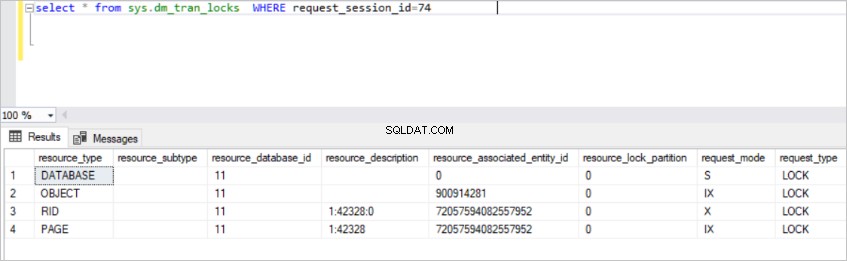
Questa visualizzazione restituisce molte informazioni sulle risorse di blocco attivo. Ma non è possibile comprendere alcuni dei dati in questa vista. Per questo motivo, dobbiamo unirci a sys.dm_tran_locks visualizza ad altre viste.
END indexes.name AS index_name, dm_tran_locks.resource_type, dm_tran_locks.resource_description, dm_tran_locks.resource_associated_entity_id, dm_tran_locks.request_mode, dm_tran_locks.request_statusFROM sys.dm_tran_locksLEFT JOIN sys.partitions ON partitions.hobt_id =dm_tran_locks.resource_associated_entity_idLEFT JOIN sys.indexes ON indexes.OBJECT_ID =partitions .OBJECT_ID AND indexes.index_id =partitions.index_idWHERE Resource_associated_entity_id> 0 AND Resource_database_id =DB_ID() e request_session_id=74ORDER BY request_session_id, Resource_associated_entity_id
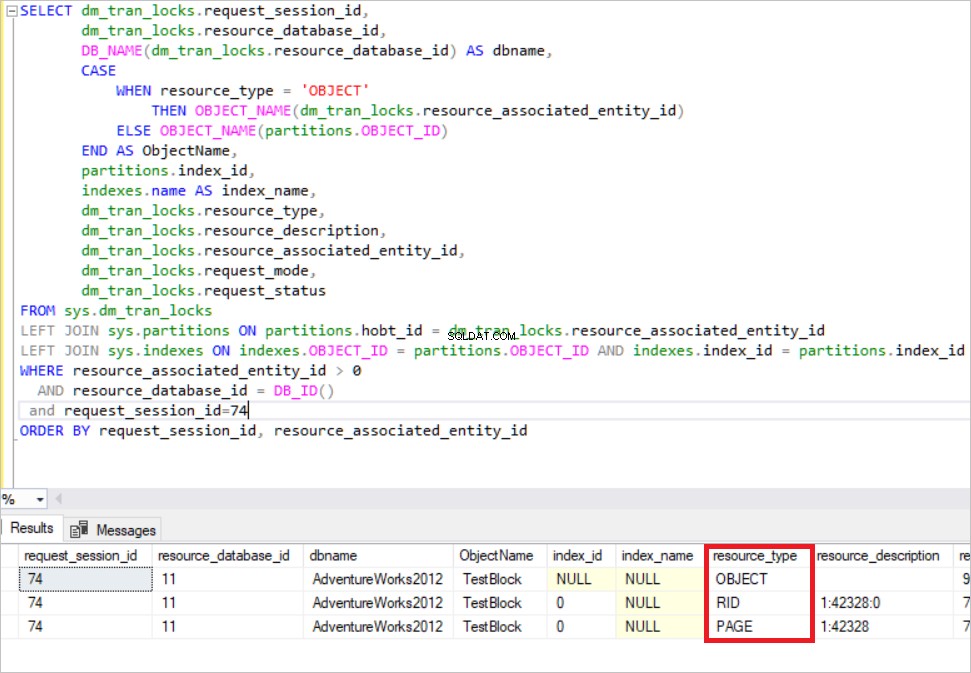
Nell'immagine sopra, puoi vedere le risorse bloccate. SQL Server acquisisce il blocco esclusivo in quella riga. (RID :un identificatore di riga utilizzato per bloccare una singola riga all'interno di un heap) Allo stesso tempo, SQL Server acquisisce il blocco esclusivo dell'intento nella pagina e il TestBlock tavolo. Significa che nessun altro processo non può leggere questa risorsa finché SQL Server non rilascia i blocchi. Questo è il meccanismo di blocco di base in SQL Server.
Ora popoleremo alcuni dati sintetici sulla nostra tabella di test.
TRUNCATE TABLE TestBlockDECLARE @K AS INT=0WHILE @K <8000BEGININSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' )SET @example@sqldat.com+1 ENDDopo aver completato questo passaggio , eseguiremo due query e controlleremo la vista sys.dm_tran_locks.BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' dove Id<5000
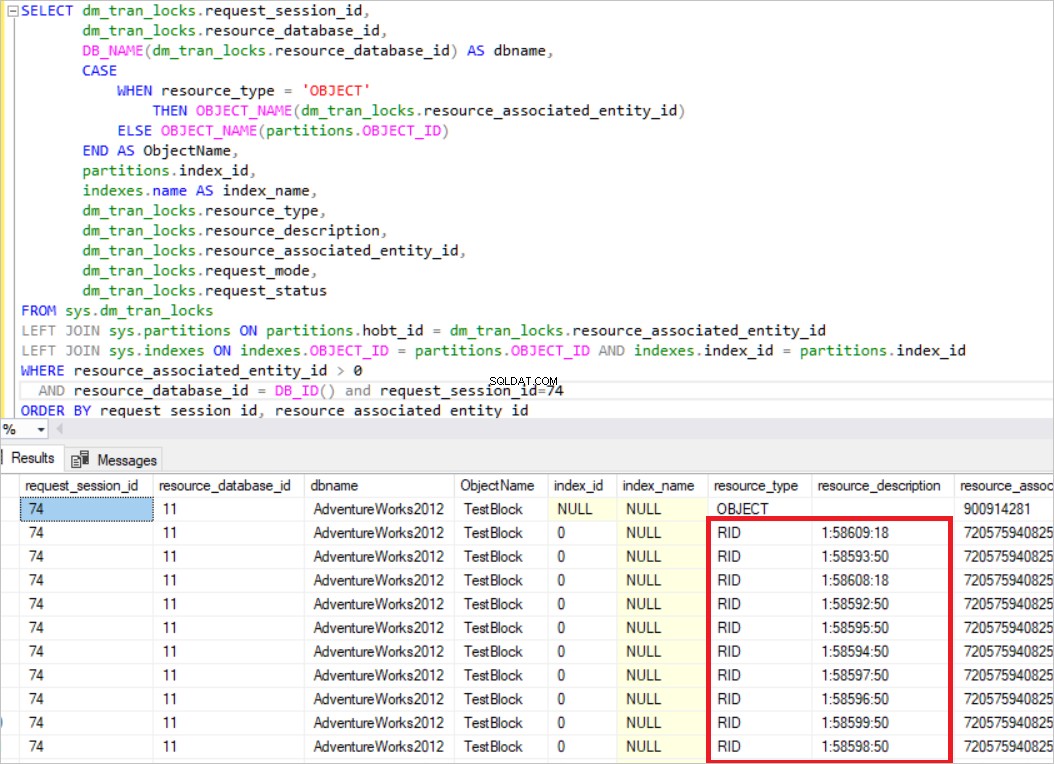
Nella query precedente, SQL Server acquisisce il blocco esclusivo su ogni singola riga. Ora eseguiremo un'altra query.
BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' dove Id<7000
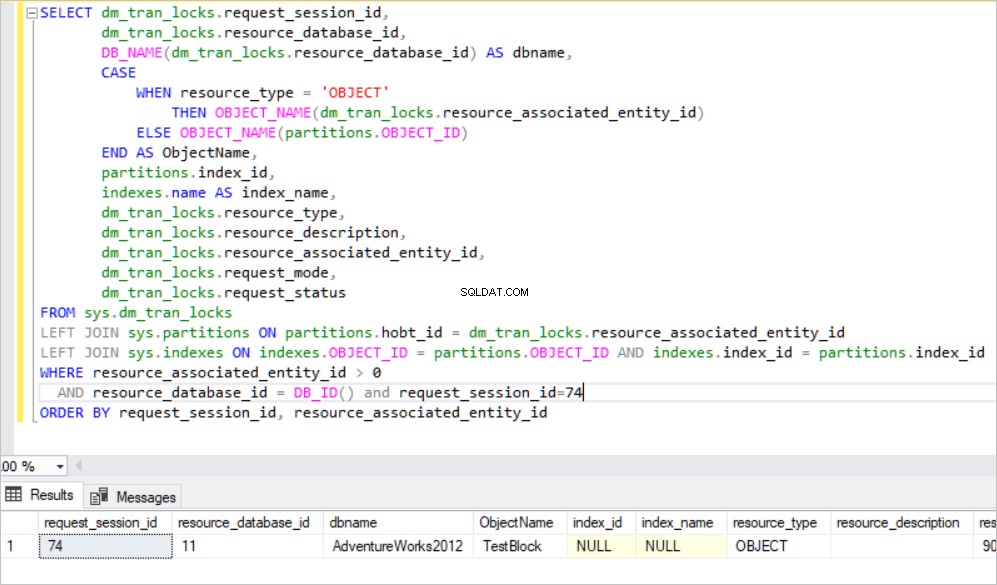
Nella query precedente, SQL Server crea il blocco esclusivo sulla tabella, poiché SQL Server tenta di acquisire molti blocchi RID per queste righe che verranno aggiornate. Questo caso causa un notevole consumo di risorse nel motore di database. Pertanto, SQL Server sposta automaticamente questo blocco esclusivo in un oggetto di livello superiore che si trova nella gerarchia dei blocchi. Definiamo questo meccanismo come Lock Escalation. L'escalation del blocco può essere modificata a livello di tabella.
ALTER TABLE XX_TableNameSET( LOCK_ESCALATION =AUTO -- o TABLE o DISABLE)GO
Vorrei aggiungere alcune note sull'escalation dei blocchi. Se hai una tabella partizionata, possiamo impostare l'escalation al livello di partizione.
In questo passaggio, eseguiremo una query che crea un blocco nella tabella AdventureWorks HumanResources. Questa tabella ha indici cluster e non cluster.
INIZIO AGGIORNAMENTO TRAN [Risorse umane].[Dipartimento] SET Nome='NuovoNome' dove IDDipartimento=1
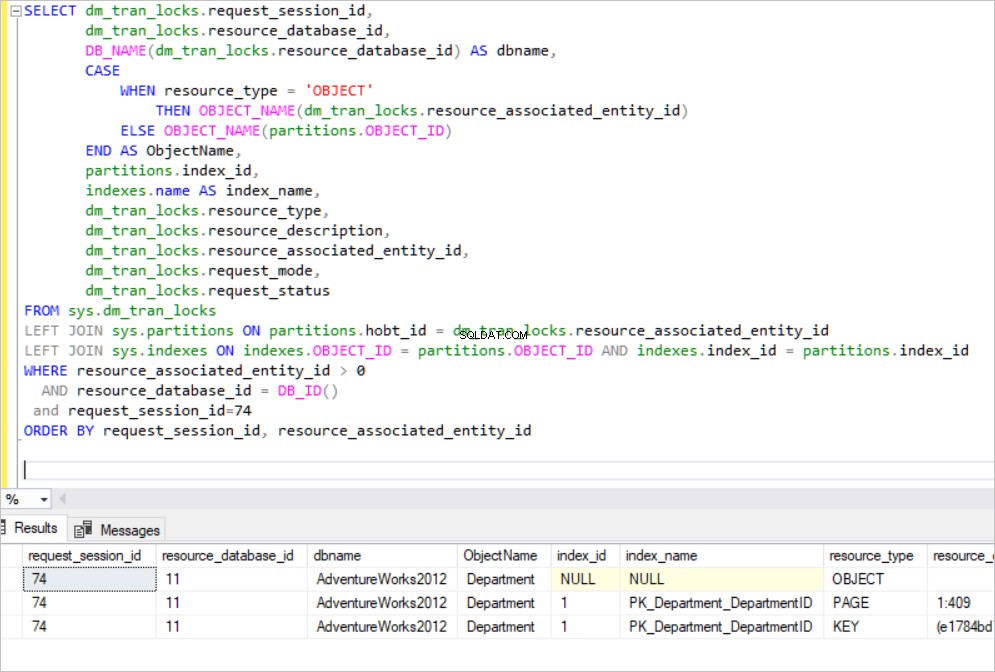
Come puoi vedere nel riquadro dei risultati di seguito, la nostra transazione acquisisce blocchi esclusivi nella chiave dell'indice del cluster PK_Department_DepartmentID e acquisisce anche blocchi esclusivi nella chiave dell'indice non cluster AK_Department_Name. Ora possiamo porre questa domanda "Perché SQL Server blocca un indice non cluster?"
Il Nome la colonna è indicizzata nell'indice non cluster AK_Department_Name e proviamo a cambiare il Nome colonna. In questo caso, SQL Server deve modificare tutti gli indici non cluster su quella colonna. Il livello foglia dell'indice non cluster include ogni valore KEY ordinato.
Conclusioni
In questo articolo abbiamo menzionato le linee principali del meccanismo di blocco di SQL Server e considerato l'uso di sys.dm_tran_locks. La vista sys.dm_tran_locks restituisce molte informazioni sulle risorse di blocco attualmente attive. Se cerchi su Google, puoi trovare molte domande di esempio su questa vista.
Riferimenti
Guida al blocco delle transazioni e al controllo delle versioni delle righe di SQL Server
SQL Server, Blocca oggetto