Routing delle transazioni primaverili
Per prima cosa creeremo un DataSourceType Java Enum che definisce le nostre opzioni di instradamento delle transazioni:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
Per instradare le transazioni di lettura-scrittura al nodo primario e le transazioni di sola lettura al nodo Replica, possiamo definire un ReadWriteDataSource che si connette al nodo primario e a un ReadOnlyDataSource che si connettono al nodo Replica.
L'instradamento delle transazioni in lettura-scrittura e sola lettura viene eseguito da Spring AbstractRoutingDataSource astrazione, implementata da TransactionRoutingDatasource , come illustrato dal diagramma seguente:
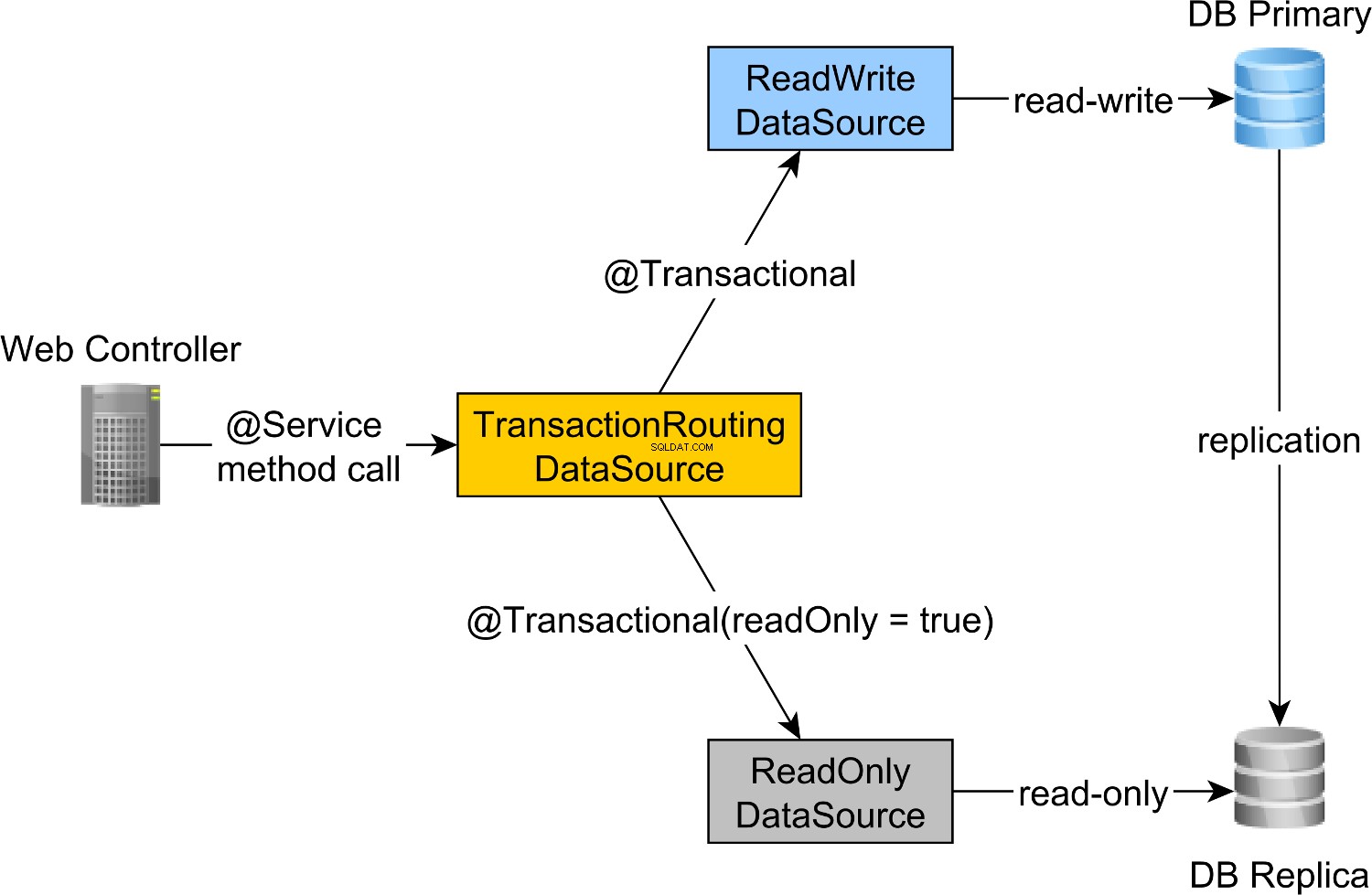
Il TransactionRoutingDataSource è molto facile da implementare e si presenta come segue:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
Fondamentalmente, ispezioniamo il TransactionSynchronizationManager di Spring classe che memorizza il contesto transazionale corrente per verificare se la transazione Spring attualmente in esecuzione è di sola lettura o meno.
Il determineCurrentLookupKey restituisce il valore del discriminatore che verrà utilizzato per scegliere il JDBC in lettura-scrittura o in sola lettura DataSource .
Configurazione dell'origine dati JDBC in lettura, scrittura e sola lettura
Il DataSource la configurazione appare come segue:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
Il /META-INF/jdbc-postgresql-replication.properties file di risorse fornisce la configurazione per il DataSource JDBC in lettura-scrittura e sola lettura componenti:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
Il jdbc.url.primary la proprietà definisce l'URL del nodo primario mentre il jdbc.url.replica definisce l'URL del nodo Replica.
Il readWriteDataSource Il componente Spring definisce il DataSource JDBC in lettura e scrittura mentre readOnlyDataSource il componente definisce il JDBC di sola lettura DataSource .
Si noti che sia le origini dati di lettura-scrittura che di sola lettura utilizzano HikariCP per il pool di connessioni.
Il actualDataSource funge da facciata per le origini dati in lettura-scrittura e sola lettura ed è implementato utilizzando il TransactionRoutingDataSource utilità.
Il readWriteDataSource è registrato utilizzando il DataSourceType.READ_WRITE chiave e il readOnlyDataSource utilizzando il DataSourceType.READ_ONLY chiave.
Quindi, quando si esegue un @Transactional di lettura e scrittura metodo, il readWriteDataSource verrà utilizzato durante l'esecuzione di un @Transactional(readOnly = true) metodo, il readOnlyDataSource verrà invece utilizzato.
Nota che le additionalProperties il metodo definisce il hibernate.connection.provider_disables_autocommit Proprietà Hibernate, che ho aggiunto a Hibernate per posticipare l'acquisizione del database per le transazioni RESOURCE_LOCAL JPA.
Non solo hibernate.connection.provider_disables_autocommit consente di utilizzare meglio le connessioni al database, ma è l'unico modo in cui possiamo far funzionare questo esempio poiché, senza questa configurazione, la connessione viene acquisita prima di chiamare la determineCurrentLookupKey metodo TransactionRoutingDataSource .
I restanti componenti Spring necessari per la creazione di JPA EntityManagerFactory sono definiti da AbstractJPAConfiguration classe base.
Fondamentalmente, il actualDataSource viene ulteriormente avvolto da DataSource-Proxy e fornito a JPA EntityManagerFactory . Puoi controllare il codice sorgente su GitHub per maggiori dettagli.
Tempo di prova
Per verificare se l'instradamento delle transazioni funziona, abiliteremo il log delle query PostgreSQL impostando le seguenti proprietà in postgresql.conf file di configurazione:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
Il log_min_duration_statement l'impostazione della proprietà è per la registrazione di tutte le istruzioni PostgreSQL mentre la seconda aggiunge il nome del database al log SQL.
Quindi, quando chiami il newPost e findAllPostsByTitle metodi, come questo:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
Possiamo vedere che PostgreSQL registra i seguenti messaggi:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
Le istruzioni di registro che utilizzano high_performance_java_persistence prefisso sono stati eseguiti sul nodo primario mentre quelli che utilizzano il high_performance_java_persistence_replica sul nodo Replica.
Quindi, tutto funziona come un incantesimo!
Tutto il codice sorgente può essere trovato nel mio repository GitHub Java Persistence ad alte prestazioni, quindi puoi provarlo anche tu.
Conclusione
Devi assicurarti di impostare la dimensione giusta per i tuoi pool di connessioni perché ciò può fare un'enorme differenza. Per questo, consiglio di utilizzare Flexy Pool.
Devi essere molto diligente e assicurarti di contrassegnare tutte le transazioni di sola lettura di conseguenza. È insolito che solo il 10% delle tue transazioni sia di sola lettura. Potrebbe essere che tu disponga di un'applicazione di questo tipo o stai utilizzando transazioni di scrittura in cui emetti solo istruzioni di query?
Per l'elaborazione in batch, hai sicuramente bisogno di transazioni di lettura e scrittura, quindi assicurati di abilitare il batching JDBC, in questo modo:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
Per il batch puoi anche utilizzare un DataSource separato che utilizza un pool di connessioni diverso che si connette al nodo primario.
Assicurati solo che la dimensione totale della tua connessione di tutti i pool di connessione sia inferiore al numero di connessioni con cui è stato configurato PostgreSQL.
Ogni processo batch deve utilizzare una transazione dedicata, quindi assicurati di utilizzare una dimensione batch ragionevole.
Inoltre, vuoi mantenere i blocchi e completare le transazioni il più velocemente possibile. Se il processore batch utilizza processi di elaborazione simultanei, assicurati che la dimensione del pool di connessioni associato sia uguale al numero di lavoratori, in modo che non aspettino che altri rilasci le connessioni.