Il raggruppamento è una caratteristica importante che aiuta a organizzare e organizzare i dati. Esistono molti modi per farlo e uno dei metodi più efficaci è la clausola SQL GROUP BY.
Puoi utilizzare SQL GROUP BY per dividere le righe nei risultati in gruppi con una funzione di aggregazione . Sembra facile sommare, fare la media o contare i record con esso.
Ma lo stai facendo bene?
"Giusto" può essere soggettivo. Quando viene eseguito senza errori critici con un output corretto, è considerato a posto. Tuttavia, deve essere anche veloce.
In questo articolo verrà presa in considerazione anche la velocità. Vedrai molte analisi delle query utilizzando letture logiche e piani di esecuzione in tutti i punti.
Cominciamo.
1. Filtra in anticipo
Se sei confuso su quando usare WHERE e HAVING, questo è per te. Perché a seconda della condizione che fornisci, entrambi possono dare lo stesso risultato.
Ma sono diversi.
HAVING filtra i gruppi utilizzando le colonne nella clausola SQL GROUP BY. WHERE filtra le righe prima che si verifichino raggruppamenti e aggregazioni. Pertanto, se filtri utilizzando la clausola HAVING, il raggruppamento si verifica per tutti righe restituite.
E questo è un male.
Come mai? La risposta breve è:è lento. Dimostriamolo con 2 query. Controlla il codice qui sotto. Prima di eseguirlo in SQL Server Management Studio, premi prima Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analisi
Le 2 istruzioni SELECT sopra restituiranno le stesse righe. Entrambi sono corretti nel restituire gli ordini di prodotti per mese nell'anno 2012. Ma il primo SELECT ha richiesto 136 ms. per funzionare sul mio laptop, mentre un altro ha impiegato 764 ms.!
Perché?
Controlliamo prima le letture logiche nella Figura 1. STATISTICS IO ha restituito questi risultati. Quindi, l'ho incollato in StatisticsParser.com per l'output formattato.
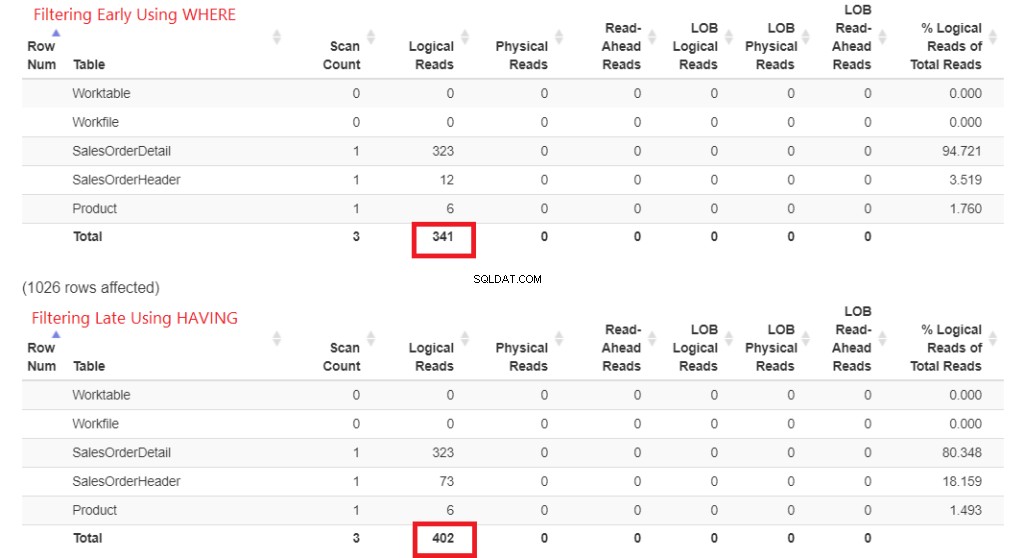
Figura 1 . Letture logiche del filtraggio anticipato utilizzando WHERE rispetto al filtraggio tardivo utilizzando HAVING.
Guarda le letture logiche totali di ciascuno. Per comprendere questi numeri, più letture logiche sono necessarie, più lenta sarà la query. Quindi, dimostra che l'utilizzo di HAVING è più lento e il filtraggio anticipato con WHERE è più veloce.
Naturalmente, questo non significa che AVERE sia inutile. Un'eccezione è quando si utilizza HAVING con un aggregato come HAVING SUM(sod.Linetotal)> 100000 . Puoi combinare una clausola WHERE e una clausola HAVING in una query.
Vedi il piano di esecuzione nella Figura 2.
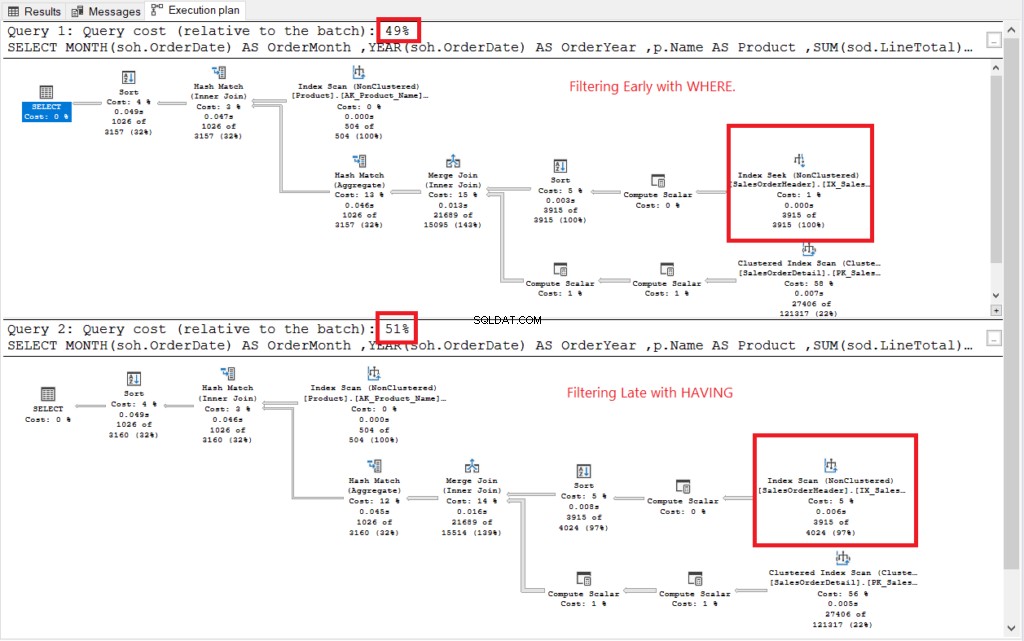
Figura 2 . Piani di esecuzione del filtraggio anticipato rispetto al filtraggio tardivo.
Entrambi i piani di esecuzione sembravano simili ad eccezione di quelli contrassegnati in rosso. Il filtraggio iniziale utilizzava l'operatore di ricerca dell'indice mentre un altro utilizzava la scansione dell'indice. Le ricerche sono più veloci delle scansioni in tabelle di grandi dimensioni.
No ti: Filtrare in anticipo ha un costo inferiore rispetto a filtrare in ritardo. Quindi, la conclusione è che filtrare le righe in anticipo può migliorare le prestazioni.
2. Raggruppa prima, unisciti dopo
Unisciti ad alcuni dei tavoli di cui hai bisogno in un secondo momento può anche migliorare le prestazioni.
Supponiamo che tu voglia avere vendite mensili di prodotti. È inoltre necessario ottenere il nome del prodotto, il numero e la sottocategoria tutti nella stessa query. Queste colonne sono in un'altra tabella. E tutti devono essere aggiunti nella clausola GROUP BY per avere un'esecuzione corretta. Ecco il codice.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Questo funzionerà bene. Ma c'è un modo migliore e più veloce. Ciò non richiederà di aggiungere le 3 colonne per il nome del prodotto, il numero e la sottocategoria nella clausola GROUP BY. Tuttavia, ciò richiederà un po' più di battiture. Eccolo.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analisi
Perché è più veloce? Il si unisce a Prodotto e Sottocategoria di prodotto sono fatti dopo. Entrambi non sono coinvolti nella clausola GROUP BY. Dimostriamolo con i numeri in STATISTICS IO. Vedi figura 4.
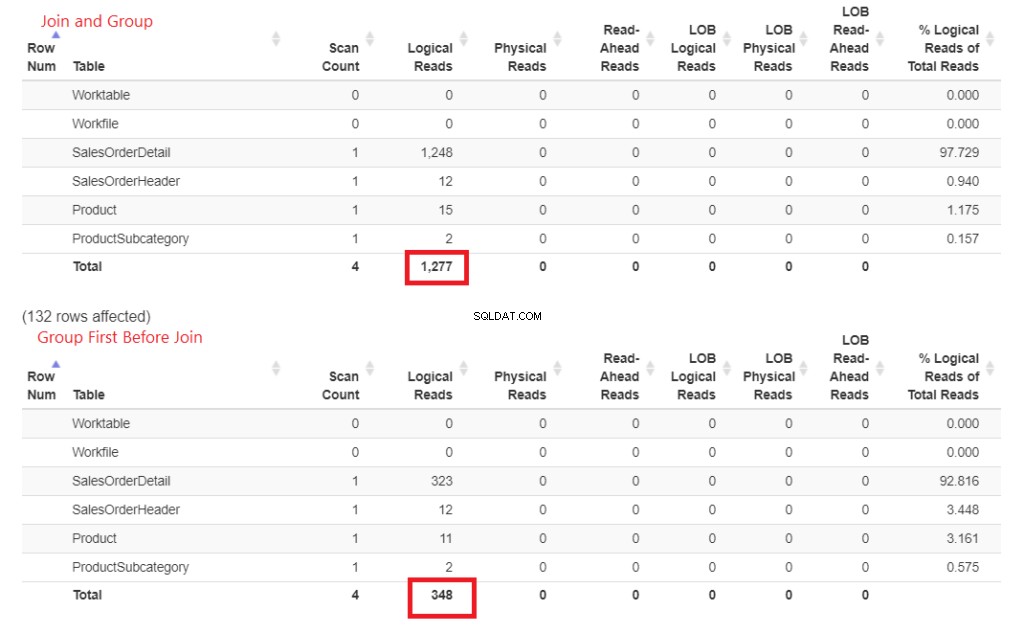
Figura 3 . L'unione anticipata e il raggruppamento hanno consumato più letture logiche rispetto all'unione successiva.
Vedi quelle letture logiche? La differenza è grande e il vincitore è ovvio.
Confrontiamo il piano di esecuzione delle 2 query per vedere il motivo dietro i numeri sopra. Innanzitutto, vedere la Figura 4 per il piano di esecuzione della query con tutte le tabelle unite quando raggruppate.
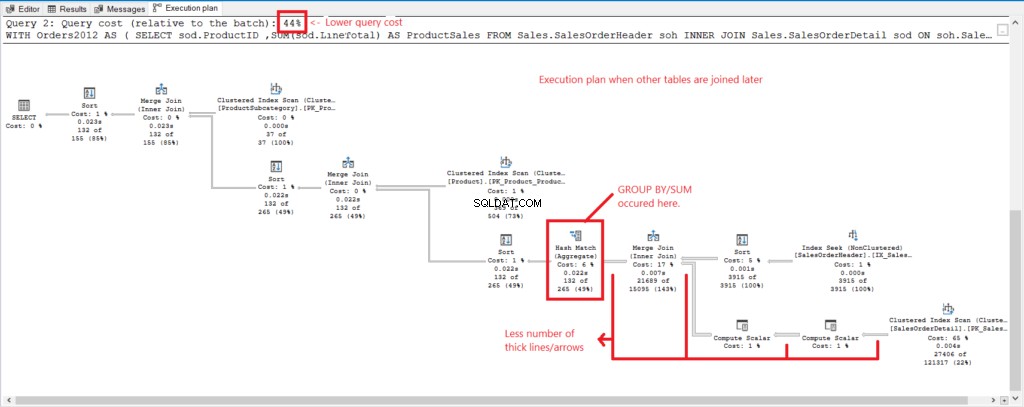
Figura 4 . Piano di esecuzione quando tutte le tabelle sono unite.
E abbiamo le seguenti osservazioni:
- GRUPPO PER e SOMMA sono stati eseguiti alla fine del processo dopo aver unito tutti i tavoli.
- Molte linee e frecce più spesse:questo spiega le 1.277 letture logiche.
- Le 2 query combinate costituiscono il 100% del costo della query. Ma il piano di questa query ha un costo della query più elevato (56%).
Ora, ecco un piano di esecuzione quando ci riuniamo per primi e ci uniamo al Prodotto e Sottocategoria di prodotto tabelle dopo. Dai un'occhiata alla Figura 5.
Figura 5 . Piano di esecuzione al termine del primo gruppo, iscrizione dopo.
E abbiamo le seguenti osservazioni nella Figura 5.
- GRUPPO PER e SOMMA sono finiti in anticipo.
- Meno numero di linee spesse e frecce:questo spiega solo le 348 letture logiche.
- Costo della query inferiore (44%).
3. Raggruppa una colonna indicizzata
Ogni volta che SQL GROUP BY viene eseguito su una colonna, tale colonna dovrebbe avere un indice. Aumenterai la velocità di esecuzione dopo aver raggruppato la colonna con un indice. Modifichiamo la query precedente e utilizziamo la data di spedizione al posto della data dell'ordine. La colonna della data di spedizione non ha un indice in SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Premi Ctrl-M, quindi esegui la query sopra in SSMS. Quindi, crea un indice non cluster in ShipDate colonna. Prendere nota delle letture logiche e del piano di esecuzione. Infine, riesegui la query sopra in un'altra scheda della query. Nota le differenze nelle letture logiche e nei piani di esecuzione.
Ecco il confronto delle letture logiche nella Figura 6.
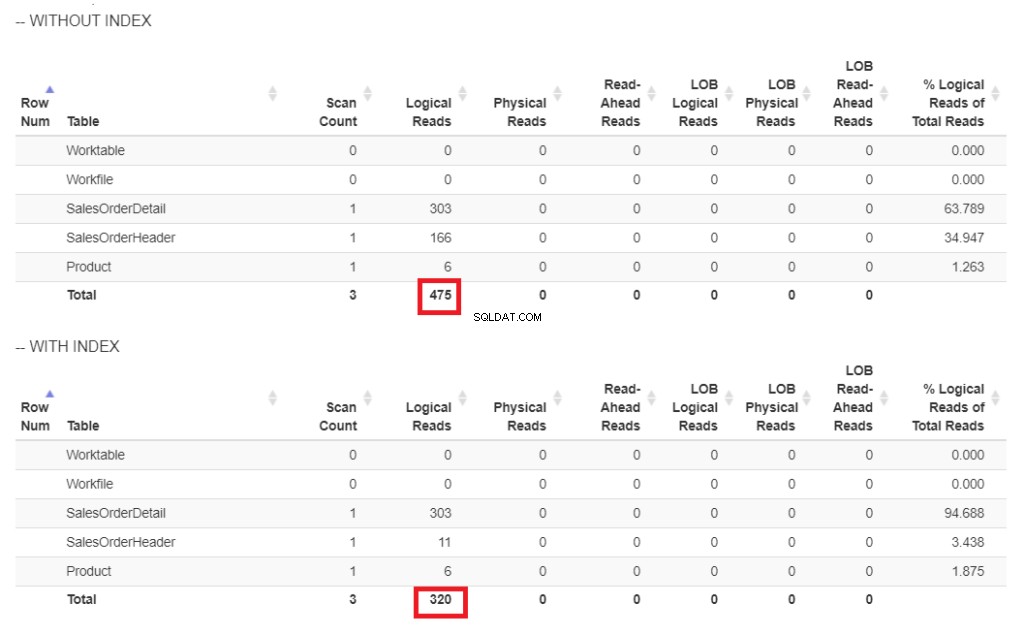
Figura 6 . Letture logiche del nostro esempio di query con e senza un indice su ShipDate.
Nella Figura 6 sono presenti letture logiche più elevate della query senza un indice su ShipDate .
Ora disponiamo del piano di esecuzione quando nessun indice su ShipDate esiste nella Figura 7.
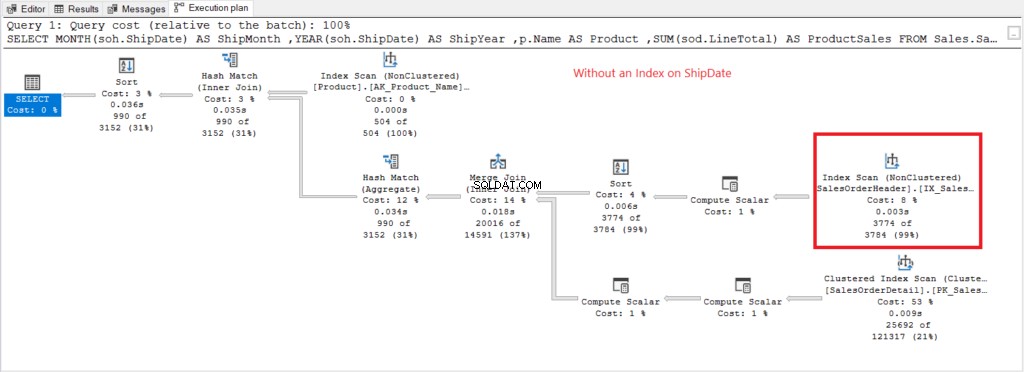
Figura 7 . Piano di esecuzione quando si utilizza GROUP BY su ShipDate non indicizzato.
La scansione dell'indice l'operatore utilizzato nel piano in Figura 7 spiega le letture logiche superiori (475). Ecco un piano di esecuzione dopo aver indicizzato la ShipDate colonna.
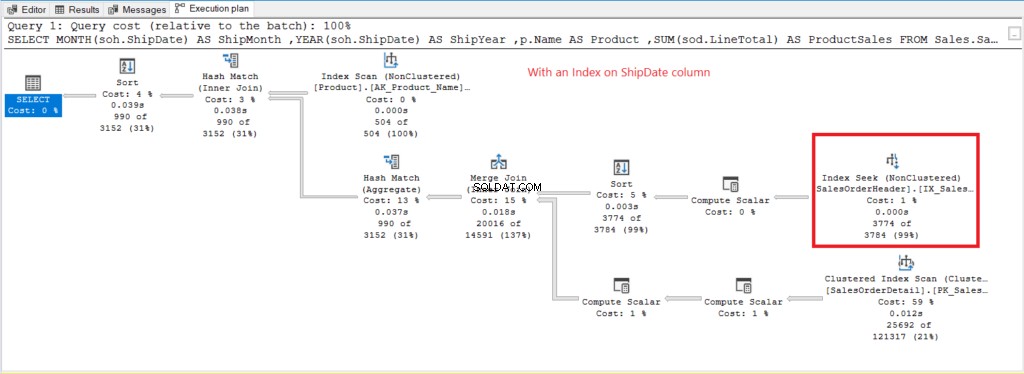
Figura 8 . Piano di esecuzione quando si utilizza GROUP BY su ShipDate indicizzato.
Invece di Index Scan, viene utilizzato un Index Seek dopo aver indicizzato il ShipDate colonna. Questo spiega le letture logiche inferiori nella Figura 6.
Pertanto, per migliorare le prestazioni quando utilizzi GROUP BY, considera l'indicizzazione delle colonne che hai utilizzato per il raggruppamento.
Da asporto nell'utilizzo di SQL GROUP BY
SQL GROUP BY è facile da usare. Ma devi fare il passo successivo per andare oltre il riepilogo dei dati per i rapporti. Ecco ancora i punti:
- Filtra in anticipo . Rimuovi le righe che non sono necessarie per riepilogare utilizzando la clausola WHERE invece della clausola HAVING.
- Prima raggruppa, poi unisciti . A volte, ci saranno colonne che devi aggiungere oltre alle colonne che stai raggruppando. Invece di includerli nella clausola GROUP BY, dividi la query con un CTE e unisci altre tabelle in un secondo momento.
- Utilizza GROUP BY con colonne indicizzate . Questa cosa di base potrebbe tornare utile quando il database è veloce come una lumaca.
Spero che questo ti aiuti a migliorare il tuo gioco nel raggruppamento dei risultati.
Se ti piace questo post, condividilo sulle tue piattaforme di social media preferite.