La risposta sarà ovviamente "dipende", ma sulla base di test a tal fine...
Supponendo
- 1 milione di prodotti
productha un indice cluster suproduct_id- La maggior parte (se non tutti) i prodotti hanno informazioni corrispondenti nel
product_codetabella - Indici ideali presenti su
product_codeper entrambe le query.
Il PIVOT la versione richiede idealmente un indice product_code(product_id, type) INCLUDE (code) mentre il JOIN la versione richiede idealmente un indice product_code(type,product_id) INCLUDE (code)
Se questi sono in atto, fornire i piani di seguito
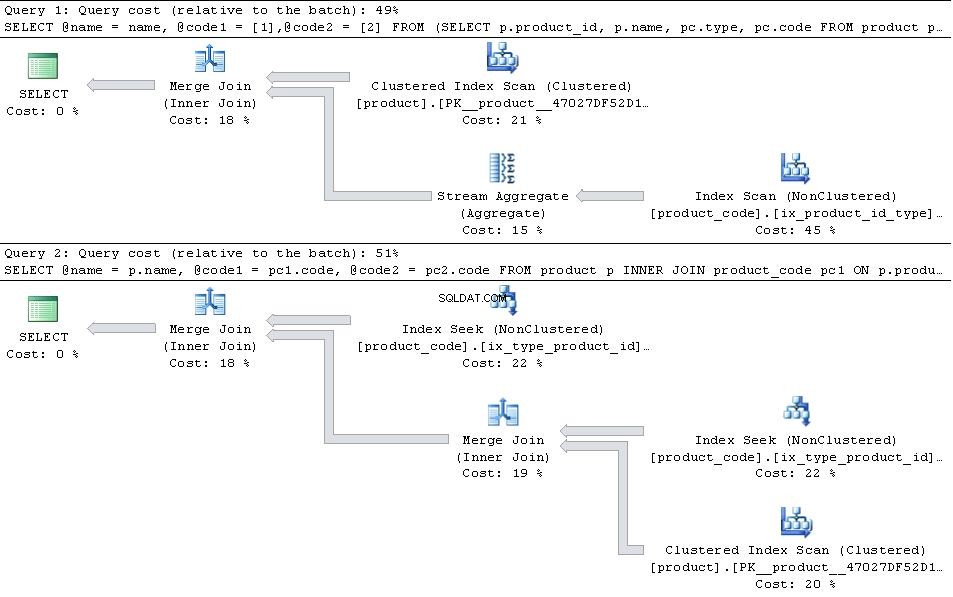
quindi il JOIN la versione è più efficiente.
Nel caso in cui type 1 e type 2 sono gli unici types nella tabella quindi il PIVOT la versione ha leggermente il vantaggio in termini di numero di letture in quanto non deve cercare in product_code due volte, ma questo è più che compensato dal sovraccarico aggiuntivo dell'operatore di aggregazione del flusso
PERNO
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
ISCRIVITI
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Se sono presenti ulteriori type record diversi da 1 e 2 il JOIN la versione aumenterà il suo vantaggio in quanto unisce semplicemente i join nelle sezioni pertinenti di type,product_id index mentre il PIVOT il piano utilizza product_id, type e quindi dovrebbe scansionare il type aggiuntivo righe che sono mescolate con 1 e 2 righe.