Che cos'è l'ottimizzazione delle query in SQL Server? È un argomento importante. Ogni tecnica o problema necessita di un articolo separato per coprire le basi. Ma quando stai appena iniziando a migliorare il tuo gioco con le query, hai bisogno di qualcosa di più semplice su cui fare affidamento. Questo è l'obiettivo di questo articolo.
Potresti dire che le tue query sono ottimali, tutto funziona bene e gli utenti sono felici. Naturalmente, le prestazioni non sono tutto. Anche i risultati dovrebbero essere corretti. Che si tratti di un join, di una sottoquery, di un sinonimo, di un CTE, di una vista o altro, deve funzionare in modo accettabile.
E alla fine della giornata, puoi tornare a casa con i tuoi utenti. Non vuoi rimanere in ufficio a risolvere le query lente durante la notte.
Prima di iniziare, ti assicuro che il viaggio non sarà difficile. Questo sarà solo un primer. Avremo esempi che non saranno troppo estranei anche a te. Infine, quando sarai pronto per uno studio più approfondito, ti presenteremo alcuni link che potrai consultare.
Cominciamo.
1. L'ottimizzazione delle query SQL inizia dalla progettazione e dall'architettura
Sorpreso? L'ottimizzazione delle query SQL non è un ripensamento o un aiuto quando qualcosa si rompe. La tua query viene eseguita alla velocità consentita dal tuo design. Stiamo parlando di tabelle normalizzate, tipi di dati corretti, uso di indici, archiviazione di vecchi dati e qualsiasi delle migliori pratiche che ti vengono in mente.
Una buona progettazione del database funziona in sinergia con l'hardware corretto e le impostazioni di SQL Server. L'hai progettato per funzionare senza intoppi per diversi anni e sentirti ancora nuovo? È un grande sogno, ma abbiamo solo un certo (di solito – breve) periodo di tempo per pensarci.
Non sarà perfetto il primo giorno di produzione, ma avremmo dovuto coprire le basi. Minimizziamo il debito tecnico. Se stai lavorando con una squadra, è fantastico rispetto a uno spettacolo personale. Puoi coprire gran parte delle campane e dei fischietti.
Tuttavia, cosa succede se il database è in esecuzione live e si colpisce il muro delle prestazioni? Ecco alcuni suggerimenti e trucchi per l'ottimizzazione delle query SQL.
2. Individua le query problematiche con il report standard di SQL Server
Durante la codifica, è facile individuare una lunga serie di codice o una procedura memorizzata. Puoi eseguire il debug riga per riga. La linea che è in ritardo è quella da correggere.
Ma cosa succede se il tuo helpdesk ha lanciato una dozzina di biglietti perché è lento? Gli utenti non possono individuare la posizione esatta nel codice e nemmeno l'helpdesk. Il tempo è il tuo peggior nemico.
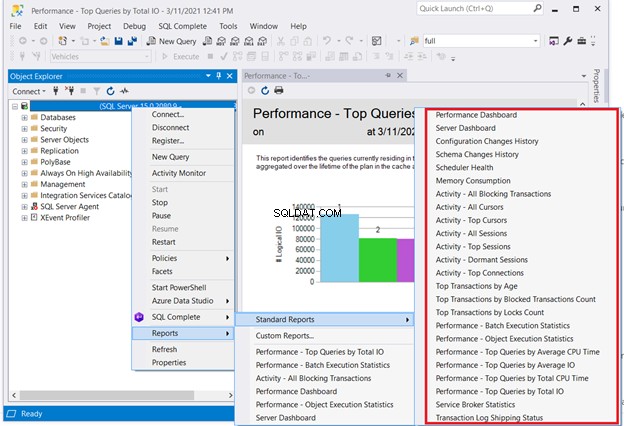
Una soluzione che non richiede la codifica è il controllo dei report standard di SQL Server. Fai clic con il pulsante destro del mouse sul server necessario in SQL Server Management Studio> Rapporti> Rapporti standard . Il nostro punto di interesse potrebbe essere il Dashboard delle prestazioni o Prestazioni – Query principali per I/O totale . Scegli la prima query che funziona male. Quindi avvia l'ottimizzazione della query SQL o l'ottimizzazione delle prestazioni SQL da lì.
3. Ottimizzazione delle query SQL con STATISTICS IO
Dopo aver individuato la query in questione, puoi iniziare a controllare le letture logiche in STATISTICS IO. Questo è uno degli strumenti di ottimizzazione delle query SQL.
Ci sono alcuni punti I/O, ma dovresti concentrarti sulle letture logiche. Più alte sono le letture logiche, più problematiche sono le prestazioni della query.
Riducendo i 3 fattori seguenti, puoi velocizzare le query di ottimizzazione delle prestazioni in SQL:
- letture logiche elevate,
- letture logiche LOB elevate,
- o letture logiche di WorkTable/WorkFile elevate.
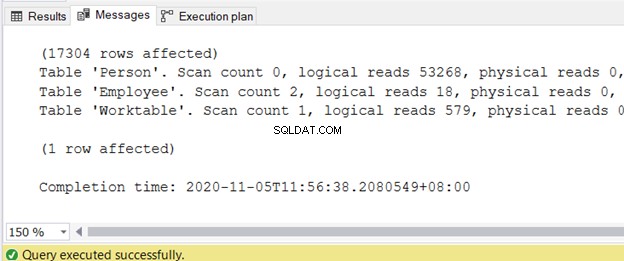
Per ottenere le informazioni sulle letture logiche, attiva STATISTICS IO nella finestra della query di SQL Server Management Studio.
IMPOSTA STATISTICHE IO ON
È possibile ottenere l'output nella scheda Messaggi al termine della query. La figura 2 mostra l'output di esempio:
Ho scritto un articolo separato sulla riduzione delle letture logiche in 3 Nasty I/O Statistics che ritardano le prestazioni delle query SQL. Fare riferimento ad esso per i passaggi esatti e gli esempi di codice con letture logiche elevate e i modi per ridurle.
4. Ottimizzazione delle query SQL con piani di esecuzione
Le letture logiche da sole non ti daranno il quadro completo. La serie di passaggi scelti da Query Optimizer racconterà la storia del tuo set di risultati. Come inizia tutto dopo aver eseguito la query?
La figura 3 di seguito è un diagramma di ciò che accade dopo aver attivato l'esecuzione fino al momento in cui si ottiene il set di risultati.
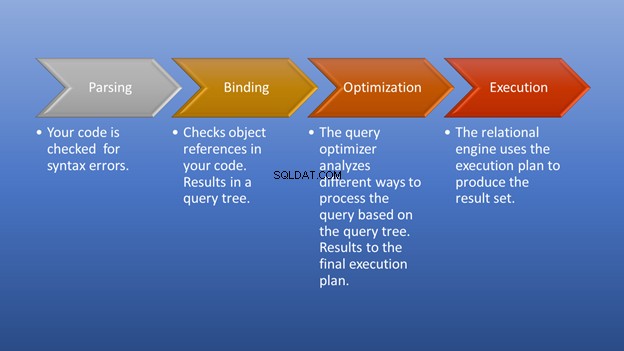
L'analisi e il collegamento avverranno in un lampo. La parte fantastica è la fase di ottimizzazione, che è il nostro obiettivo. In questa fase, Query Optimizer svolge un ruolo fondamentale nella selezione del miglior piano di esecuzione possibile. Sebbene questa parte richieda alcune risorse, consente di risparmiare molto tempo quando sceglie un piano di esecuzione efficiente. Ciò avviene in modo dinamico, poiché il database cambia nel tempo. In questo modo, il programmatore può concentrarsi su come formare il risultato finale.
Ogni piano considerato da Query Optimizer ha il suo costo di query. Tra le molte opzioni, l'ottimizzatore sceglierà il piano con il costo più ragionevole. Nota :Il costo ragionevole non è uguale al costo minimo. Deve anche considerare quale piano produrrà i risultati più rapidi. Il piano con il minor costo non è sempre il più veloce. Ad esempio, l'ottimizzatore può scegliere di utilizzare diversi core del processore. Chiamiamo questa esecuzione parallela. Ciò consumerà più risorse ma verrà eseguito più velocemente rispetto all'esecuzione seriale.
Un altro punto da considerare è la statistica. Query Optimizer si basa su di esso per creare piani di esecuzione. Se le statistiche sono obsolete, non aspettarti la decisione migliore da Query Optimizer.
Quando il piano è deciso e l'esecuzione procede, vedrai i risultati. E adesso?
Ispeziona il piano di esecuzione delle query in SQL Server
Quando si forma una query, si desidera prima vedere i risultati. I risultati devono essere corretti. Quando lo è, hai finito.
È così?
Se hai poco tempo e il lavoro è in gioco, potresti accettare. Inoltre, puoi sempre tornare. Tuttavia, se sorgono altri problemi, puoi dimenticarli ancora e ancora. E poi, il fantasma del passato ti darà la caccia.
Ora, qual è la cosa migliore da fare dopo aver ottenuto i risultati corretti?
Esamina il Piano di esecuzione effettivo o le Statistiche delle query in tempo reale !
Quest'ultimo è utile se la tua query è lenta e vuoi vedere cosa succede ogni secondo mentre le righe vengono elaborate.
A volte, la situazione ti costringerà a ispezionare immediatamente il piano. Per iniziare, premi CTRL-M oppure fai clic su Includi piano di esecuzione effettivo dalla barra degli strumenti di SQL Server Management Studio. Se preferisci dbForge Studio per SQL Server, vai a Query Profiler – fornisce le stesse informazioni + alcuni campanelli e fischietti che non puoi trovare in SSMS.
Abbiamo visto il Piano di esecuzione effettivo . Procediamo oltre.
Manca un indice o suggerimenti sull'indice?
Un indice mancante è facile da individuare:ricevi immediatamente l'avviso.
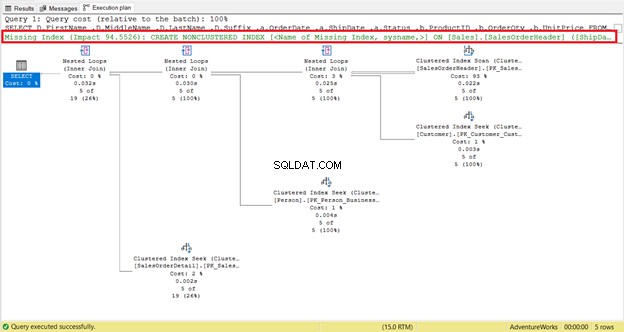
Per ottenere un codice istantaneo per creare l'indice, fai clic con il pulsante destro del mouse sull'Indice mancante messaggio (riquadro rosso). Quindi seleziona Dettagli indice mancanti . Apparirà una nuova finestra di query con il codice per creare l'indice mancante. Crea l'indice.
Questa parte è facile da seguire. È un buon punto di partenza per ottenere un'esecuzione più rapida. Ma in alcuni casi, non ci sarà alcun effetto. Come mai? Alcune colonne necessarie per la tua query non sono nell'indice. Pertanto, verrà ripristinata una scansione dell'indice cluster.
È necessario riesaminare il piano di esecuzione dopo aver creato l'indice per verificare se sono necessarie colonne incluse. Quindi, regola l'indice di conseguenza ed esegui nuovamente la query. Dopodiché, controlla di nuovo il piano di esecuzione.
Ma cosa succede se non mancano gli indici?
Leggi il Piano di Esecuzione
Devi conoscere alcune cose di base per iniziare:
- Operatori
- Proprietà
- Direzione di lettura
- Avvertenze
OPERATORI
Query Optimizer utilizza una sorta di mini-programmi chiamati operatori. Ne hai visti alcuni nella Figura 4 – Ricerca di indici cluster , Scansione indice cluster , Loop nidificati e Seleziona .
Per ottenere un elenco completo con nomi, icone e descrizioni, puoi controllare questo riferimento da Microsoft.
PROPRIETA'
I diagrammi grafici non sono sufficienti per capire cosa sta succedendo dietro le quinte. È necessario scavare più a fondo nelle proprietà di ciascun operatore. Ad esempio, la Scansione indice cluster in Figura 4 ha le seguenti Proprietà:
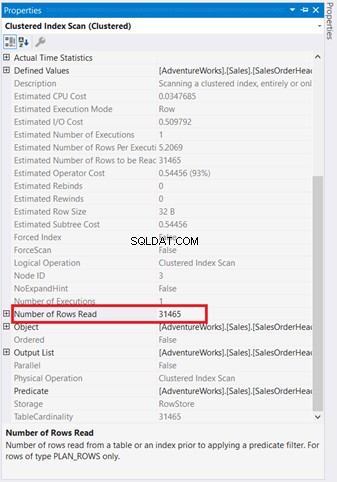
Se lo esaminerai attentamente, la scansione dell'indice cluster l'operatore è terribile. Come mostra la Figura 5, leggeva 31.465 righe, ma il set di risultati finale è di sole 5 righe. Ecco perché nella figura 4 è presente una raccomandazione sull'indice per ridurre il numero di righe lette. Anche le letture logiche della query sono elevate e questo spiega il motivo.
Per saperne di più su queste proprietà, controlla l'elenco delle proprietà comuni dell'operatore e delle proprietà del piano.
DIREZIONE DI LETTURA
In generale, è come leggere i manga giapponesi, da destra a sinistra. Segui le frecce che puntano a sinistra. Ecco un semplice esempio di dbForge Studio per SQL Server.
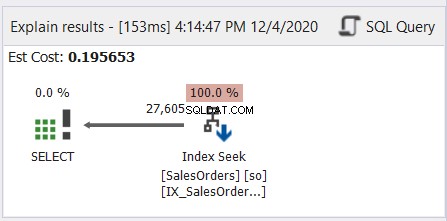
Come mostra la Figura 6, la freccia punta a sinistra dall'operatore Index Seek all'operatore SELECT.
Tuttavia, la lettura da destra a sinistra potrebbe non essere sempre corretta. Vedere la Figura 7 con un esempio di SSMS:
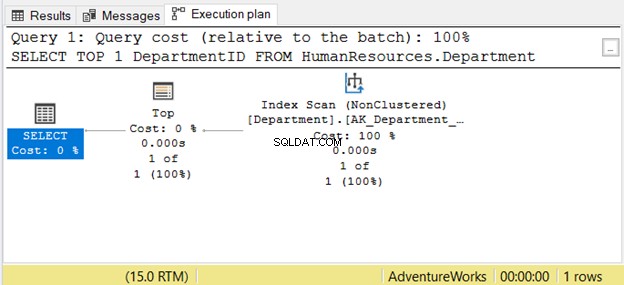
Se lo leggi da destra a sinistra, vedrai che la scansione dell'indice l'output dell'operatore è 1 di 1 riga. Come potrebbe sapere solo 1 riga da recuperare? È a causa del Top operatore. Questo ci confonderà se lo leggiamo da destra a sinistra.
Per comprendere meglio questo caso, leggilo come "l'operatore SELECT utilizza Top per recuperare 1 riga utilizzando Index Scan". Quello è da sinistra a destra.
Cosa dovremmo usare? Da destra a sinistra o da sinistra a destra?
È un po' entrambe le cose, qualunque cosa ti aiuti a capire il piano.
Mentre la freccia ci dà la direzione del flusso di dati, il suo spessore ci dà alcuni suggerimenti sulla dimensione dei dati. Facciamo nuovamente riferimento alla Figura 4.
La scansione dell'indice cluster andando al Nesd Loop ha una freccia più spessa rispetto alle altre. Le Proprietà dettagli di Scansione indice nella Figura 5 spiegaci perché è spesso (31.465 righe lette per un risultato finale di 5 righe).
AVVERTENZE
Un'icona di avviso che appare nell'operatore del piano di esecuzione ci dice che è successo qualcosa di brutto in quell'operatore. Ciò può ostacolare l'ottimizzazione delle query SQL consumando più risorse.
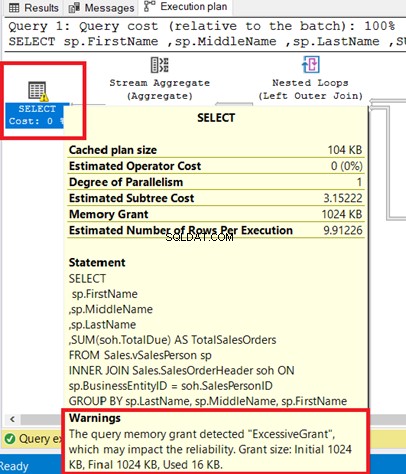
È possibile visualizzare l'avviso nell'operatore SELECT. Passare il mouse su quell'operatore rivela il messaggio di avviso. Una sovvenzione eccessiva ha causato questo avviso.
Contributo eccessivo si verifica quando viene utilizzata meno memoria di quella riservata per la query. Per ulteriori informazioni, fare riferimento a questa documentazione Microsoft.
La Figura 8 mostra la query utilizzata come INNER JOIN di una vista in una tabella. Puoi rimuovere l'avviso unendo le tabelle di base anziché la vista.
Ora che hai un'idea di base sulla lettura dei piani di esecuzione, come definire cosa rallenta la tua query?
Conosci i 5 ladri comuni degli operatori del piano
Il ritardo nell'esecuzione della query è come un crimine. Devi inseguire e arrestare questi ladri.
1. Scansione indice cluster o non cluster
Il primo ladro di cui tutti vengono a conoscenza è Clustered o Scansione indice non cluster . La sua conoscenza comune nell'ottimizzazione delle query SQL che le scansioni sono cattive e le ricerche sono buone. Ne abbiamo visto uno nella Figura 4. A causa dell'indice mancante, la Scansione dell'indice cluster legge 31.465 per ottenere 5 righe.
Tuttavia, non è sempre così. Considera 2 query sulla stessa tabella nella Figura 9. Una avrà una ricerca e un'altra avrà una scansione.
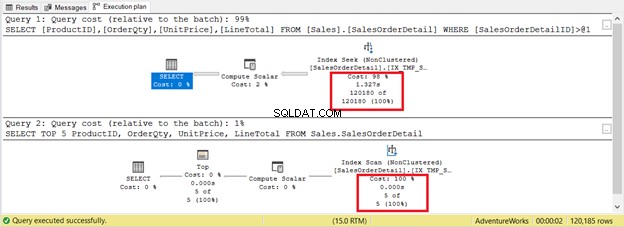
Se basi i criteri solo sul numero di record, la scansione dell'indice vince con solo 5 record contro 120.180. L'esecuzione della ricerca dell'indice richiederà più tempo.
Ecco un altro caso in cui scansionare o cercare quasi non ha importanza. Restituiscono gli stessi 6 record dalla stessa tabella. Le letture logiche sono le stesse e il tempo trascorso è zero in entrambi i casi. La tabella è molto piccola con solo 6 record. Includi il piano di esecuzione effettivo ed esegui le istruzioni seguenti.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Quindi, salva il piano di esecuzione per un confronto successivo. Fai clic con il pulsante destro del mouse sul piano di esecuzione> Salva piano di esecuzione con nome .
Ora, esegui la query seguente.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Quindi, fai clic con il pulsante destro del mouse sul Piano di esecuzione e seleziona Confronta Showplan . Quindi, seleziona il file che hai salvato in precedenza. Dovresti avere lo stesso output della Figura 10 di seguito.
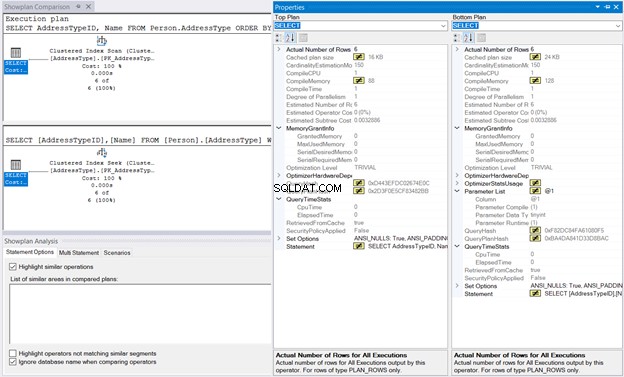
Il MemoryGrant e QueryTimeStats sono gli stessi. La memoria di compilazione da 128 KB utilizzato nella Ricerca di indici cluster rispetto agli 88 KB della scansione dell'indice cluster è quasi trascurabile. Senza queste cifre da confrontare, l'esecuzione sarà la stessa.
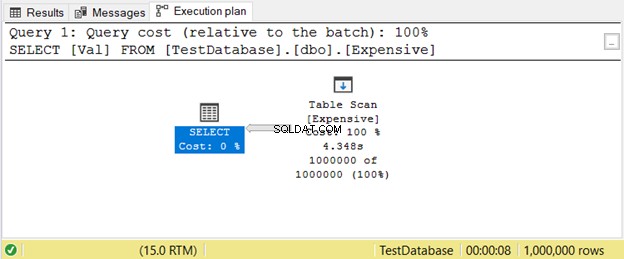
2. Evitare le scansioni delle tabelle
Questo succede quando non hai un indice. Invece di cercare valori utilizzando un indice, SQL Server eseguirà la scansione delle righe una per una finché non ottiene ciò di cui hai bisogno nella query. Questo ritarderà molto su tavoli di grandi dimensioni. La soluzione semplice è aggiungere l'indice appropriato.
Ecco un esempio di un piano di esecuzione con Scansione tabella operatore nella Figura 11.
3. Gestione delle prestazioni di ordinamento
Come deriva dal nome, cambia l'ordine delle righe. Questa può essere un'operazione costosa.
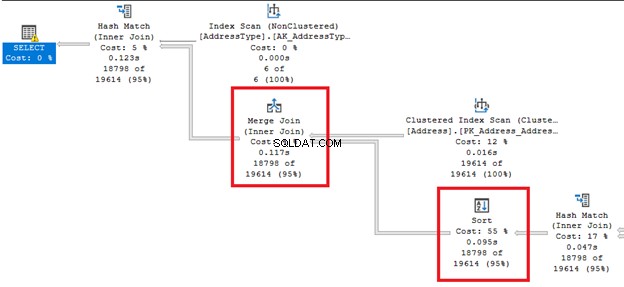
Guarda quelle grosse linee di frecce a destra e a sinistra di Ordina operatore. Poiché Query Optimizer ha deciso di eseguire un Unisci unione , un ordinamento è obbligatorio. Si noti inoltre che ha il costo percentuale più alto di tutti gli operatori (55%).
L'ordinamento può essere più problematico se SQL Server deve ordinare le righe più volte. Puoi evitare questo operatore se la tabella è preordinata in base ai requisiti della query. Oppure puoi suddividere una singola query in più query.
4. Elimina le ricerche chiave
Nella figura 4 precedente, SQL Server consigliava di aggiungere un altro indice. L'ho fatto, ma non mi ha dato esattamente quello che volevo. Invece, mi ha dato una Ricerca all'indice al nuovo indice abbinato a una Ricerca chiave operatore.
Quindi, il nuovo indice ha aggiunto un passaggio in più.
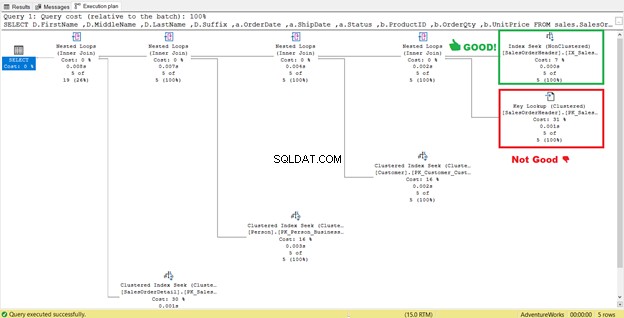
Che cosa significa questa Ricerca chiave operatore fare?
Il Query Processor ha utilizzato un nuovo indice non cluster contrassegnato da una casella verde nella Figura 13. Poiché la nostra query richiede colonne che non si trovano nel nuovo indice, deve ottenere quei dati con l'aiuto di una Ricerca chiave dall'indice cluster. Come facciamo a saperlo? Passando il mouse sulla Ricerca chiave rivela alcune delle sue proprietà e dimostra il nostro punto.
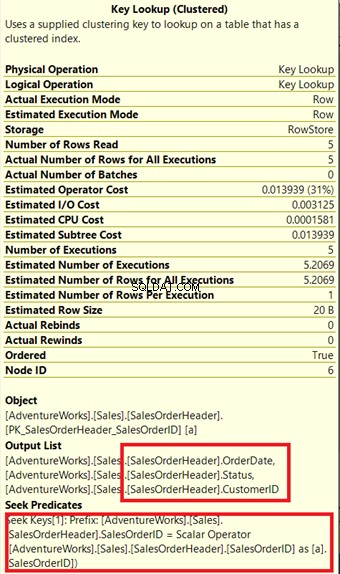
Nella Figura 14, notare l'elenco di output. Dobbiamo recuperare 3 colonne utilizzando PK_SalesOrderHeader_SalesOrderID indice raggruppato. Per rimuoverlo, devi includere queste colonne nel nuovo indice. Ecco il nuovo piano una volta incluse queste colonne.
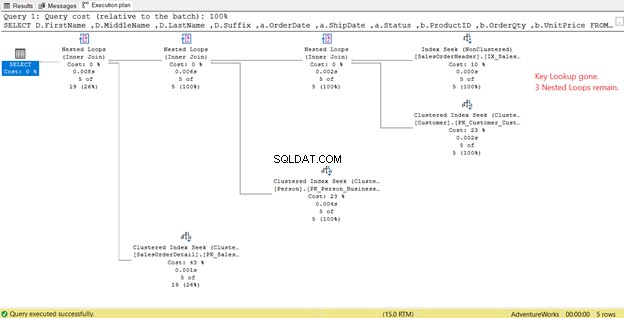
Nella Figura 14 abbiamo visto 4 Cicli nidificati . Il quarto è necessario per la Ricerca chiave aggiunta . Ma dopo aver aggiunto 3 colonne come Colonne incluse nel nuovo indice, solo 3 Cicli nidificati rimanere e la Ricerca chiave è rimosso. Non abbiamo bisogno di ulteriori passaggi.
5. Parallelismo nel piano di esecuzione di SQL Server
Finora, hai visto i piani di esecuzione in esecuzione seriale. Ma ecco il piano che sfrutta l'esecuzione parallela. Ciò significa che più di un processore viene utilizzato da Query Optimizer per eseguire la query. Quando utilizziamo l'esecuzione parallela, vediamo parallelismo operatori nel piano e anche altre modifiche.
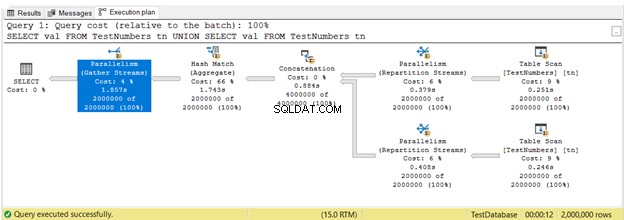
Nella Figura 16, 3 Parallelismo sono stati utilizzati gli operatori. Si noti inoltre che la Scansione tabella l'icona dell'operatore è leggermente diversa. Ciò accade quando viene utilizzata l'esecuzione parallela.
Il parallelismo non è intrinsecamente negativo. Aumenta la velocità delle query utilizzando più core del processore. Tuttavia, utilizza più risorse della CPU. Quando molte delle tue query utilizzano parallelismi, il server rallenta. Potresti voler controllare la soglia di costo per l'impostazione del parallelismo nel tuo SQL Server.
5. Procedure consigliate per l'ottimizzazione delle query SQL
Finora ci siamo occupati dell'ottimizzazione delle query SQL con metodi che portano alla luce problemi difficili da individuare. Ma ci sono modi per individuarlo nel codice. Ecco alcuni odori di codice in SQL.
Utilizzando SELEZIONA *
Di fretta? Quindi digitare * può essere più semplice che specificare i nomi delle colonne. Tuttavia, c'è un problema. Le colonne che non ti servono ritarderanno la tua query.
Ci sono prove. La query di esempio che ho utilizzato per la Figura 15 è questa:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
L'abbiamo già ottimizzato. Ma cambiamo in SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Va bene più breve, ma controlla il piano di esecuzione di seguito:
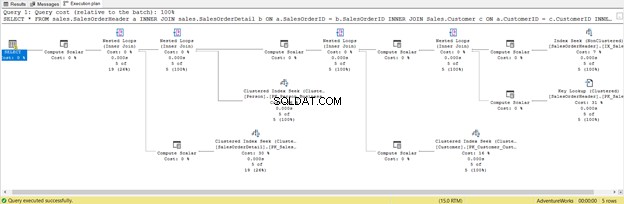
Questa è la conseguenza dell'inclusione di tutte le colonne, anche quelle non necessarie. Ha restituito Ricerca chiave e un sacco di Compute Scalar . In breve, questa query ha un carico pesante e di conseguenza ritarderà. Notare anche l'avviso nell'operatore SELECT. Non c'era prima. Che spreco!
Funzioni in una clausola WHERE o JOIN
Un altro odore di codice è avere una funzione nella clausola WHERE. Considera le seguenti 2 istruzioni SELECT aventi lo stesso set di risultati. La differenza è nella clausola WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
La prima SELECT utilizza le funzioni di data YEAR e MONTH per indicare le date di spedizione entro luglio 2011. La seconda istruzione SELECT utilizza l'operatore BETWEEN con le date letterali.
La prima istruzione SELECT avrà un piano di esecuzione simile alla Figura 4 ma senza la raccomandazione dell'indice. Il secondo avrà un piano di esecuzione migliore simile alla Figura 15.
Quello ottimizzato meglio è ovvio.
Utilizzo dei caratteri jolly
In che modo i caratteri jolly possono influenzare la nostra ottimizzazione delle query SQL? Facciamo un esempio.
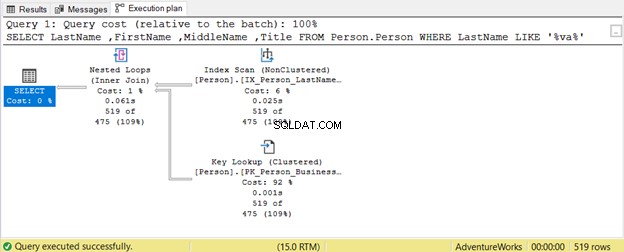
La query tenta di cercare la presenza di una stringa all'interno di Cognome in qualsiasi posizione. Quindi, Cognome LIKE '%va%' . Questo è inefficiente su tabelle di grandi dimensioni perché le righe verranno ispezionate una per una per la presenza di quella stringa. Ecco perché una Scansione dell'indice viene utilizzato. Poiché nessun indice include il Titolo colonna, una Ricerca chiave viene utilizzato anche.
Questo può essere risolto in base alla progettazione.
L'app di chiamata lo richiede? O basterà usare LIKE 'va%'?
COME 'va%' utilizza una Ricerca dell'indice perché la tabella ha un indice su cognome , nome e secondo nome .
Puoi anche aggiungere più filtri nella clausola WHERE per ridurre la lettura dei record?
Le tue risposte a queste domande ti aiuteranno a risolvere questa domanda.
Conversione implicita
SQL Server esegue la conversione implicita dietro le quinte per riconciliare i tipi di dati durante il confronto dei valori. Ad esempio, è conveniente assegnare un numero a una colonna di stringa senza virgolette. Ma c'è un problema. L'effetto è simile quando si utilizza una funzione in una clausola WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
Il NationalIDNumner è NVARCHAR(15) ma è equivalente a un numero. Verrà eseguito correttamente a causa della conversione implicita. Ma nota il piano di esecuzione nella Figura 19 di seguito.
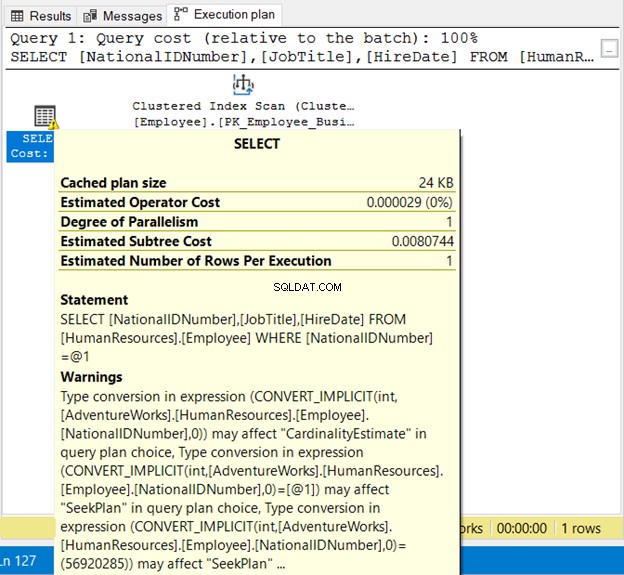
Vediamo 2 cose brutte qui. In primo luogo, l'avvertimento. Quindi, la Scansione dell'indice . La scansione dell'indice è avvenuta a causa della conversione implicita. Pertanto, assicurati di racchiudere le stringhe tra virgolette o testare valori letterali con lo stesso tipo di dati della colonna.
Assunzioni sull'ottimizzazione delle query SQL
Questo è tutto. Le basi dell'ottimizzazione delle query SQL ti hanno fatto sentire un po' pronto per le tue query? Facciamo un riepilogo.
- Se vuoi che le tue query siano ottimizzate, inizia con una buona progettazione del database.
- Se il database è già in produzione, individua le query problematiche utilizzando i report standard di SQL Server.
- Scopri quanto è grande l'impatto della query lenta con letture logiche da STATISTICS IO.
- Immergiti nella storia della tua query lenta con i piani di esecuzione.
- Guarda 4 odori di codice che rallentano le tue query.
Esistono altri suggerimenti per l'ottimizzazione delle query SQL per eseguire rapidamente una query lenta. Come ho detto all'inizio, questo è un argomento importante. Quindi, facci sapere nella sezione Commenti cos'altro ci siamo persi.
E se ti piace questo post, condividilo sulle tue piattaforme di social media preferite.
Più ottimizzazione delle query SQL dagli articoli precedenti
Se hai bisogno di altri esempi, ecco alcuni post utili relativi alle tecniche di ottimizzazione delle query in SQL Server.
- Le sottoquery sono dannose per le prestazioni? Dai un'occhiata a Guida semplice su come utilizzare le sottoquery in SQL Server .
- Utilizzo di HierarchyID rispetto al design genitore/figlio:qual è il più veloce? Visita Come utilizzare SQL Server HierarchyID attraverso semplici esempi .
- Le query del database dei grafici possono superare le prestazioni dei loro equivalenti relazionali in un sistema di raccomandazioni in tempo reale? Dai un'occhiata a Come utilizzare le funzionalità del database di SQL Server Graph .
- Qual è il più veloce:COALESCE o ISNULL? Scoprilo in Risposte principali a 5 domande scottanti sulla funzione SQL COALESCE .
- SELEZIONA DA Visualizza vs. SELEZIONA DA Tabelle di base:quale funzionerà più velocemente? Visita I 3 suggerimenti principali che devi conoscere per scrivere visualizzazioni SQL più veloci .
- CTE vs. Tabelle temporanee vs. Subquery. Scopri quale vincerà in Tutto ciò che devi sapere su SQL CTE in un unico punto .
- Uso di SQL SUBSTRING in una clausola WHERE:una trappola per le prestazioni? Verifica se è vero con gli esempi in Come analizzare le stringhe come un professionista usando la funzione SQL SUBSTRING()?
- SQL UNION ALL è più veloce di UNION. Scopri perché in cheat sheet di SQL UNION con 10 suggerimenti facili e utili .