Per intervalli di 15 minuti:
with i as (
select cf.tagindex, min(dateandtime) dateandtime
from contfloattable cf
group by
floor(extract(epoch from dateandtime) / 60 / 15),
cf.tagindex
)
select cf.dateandtime, cf."Val", cf.status, t.tagname
from
contfloattable cf
inner join
conttagtable t on cf.tagindex = t.tagindex
inner join
i on i.tagindex = cf.tagindex and i.dateandtime = cf.dateandtime
order by cf.dateandtime, t.tagname
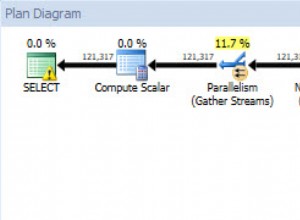
Mostra l'output di spiegazione per questa query (se funziona) in modo che possiamo provare a ottimizzare. Puoi pubblicarlo in questa risposta.
Spiega l'output
"Sort (cost=15102462177.06..15263487805.24 rows=64410251271 width=57)"
" Sort Key: cf.dateandtime, t.tagname"
" CTE i"
" -> HashAggregate (cost=49093252.56..49481978.32 rows=19436288 width=12)"
" -> Seq Scan on contfloattable cf (cost=0.00..38528881.68 rows=1408582784 width=12)"
" -> Hash Join (cost=270117658.06..1067549320.69 rows=64410251271 width=57)"
" Hash Cond: (cf.tagindex = t.tagindex)"
" -> Merge Join (cost=270117116.39..298434544.23 rows=1408582784 width=25)"
" Merge Cond: ((i.tagindex = cf.tagindex) AND (i.dateandtime = cf.dateandtime))"
" -> Sort (cost=2741707.02..2790297.74 rows=19436288 width=12)"
" Sort Key: i.tagindex, i.dateandtime"
" -> CTE Scan on i (cost=0.00..388725.76 rows=19436288 width=12)"
" -> Materialize (cost=267375409.37..274418323.29 rows=1408582784 width=21)"
" -> Sort (cost=267375409.37..270896866.33 rows=1408582784 width=21)"
" Sort Key: cf.tagindex, cf.dateandtime"
" -> Seq Scan on contfloattable cf (cost=0.00..24443053.84 rows=1408582784 width=21)"
" -> Hash (cost=335.74..335.74 rows=16474 width=44)"
" -> Seq Scan on conttagtable t (cost=0.00..335.74 rows=16474 width=44)"
Sembra che tu abbia bisogno di questo indice:
create index cf_tag_datetime on contfloattable (tagindex, dateandtime)
Esegui analyze dopo averlo creato. Ora nota che qualsiasi indice su una tabella grande avrà un impatto significativo sulle prestazioni sulle modifiche ai dati (inserisci ecc.) poiché dovrà essere aggiornato a ogni modifica.
Aggiorna
Ho aggiunto l'indice cf_tag_datetime (tagindex,dateandtime) ed ecco la nuova spiegazione:
"Sort (cost=15349296514.90..15512953953.25 rows=65462975340 width=57)"
" Sort Key: cf.dateandtime, t.tagname"
" CTE i"
" -> HashAggregate (cost=49093252.56..49490287.76 rows=19851760 width=12)"
" -> Seq Scan on contfloattable cf (cost=0.00..38528881.68 rows=1408582784 width=12)"
" -> Hash Join (cost=270179293.86..1078141313.22 rows=65462975340 width=57)"
" Hash Cond: (cf.tagindex = t.tagindex)"
" -> Merge Join (cost=270178752.20..298499296.08 rows=1408582784 width=25)"
" Merge Cond: ((i.tagindex = cf.tagindex) AND (i.dateandtime = cf.dateandtime))"
" -> Sort (cost=2803342.82..2852972.22 rows=19851760 width=12)"
" Sort Key: i.tagindex, i.dateandtime"
" -> CTE Scan on i (cost=0.00..397035.20 rows=19851760 width=12)"
" -> Materialize (cost=267375409.37..274418323.29 rows=1408582784 width=21)"
" -> Sort (cost=267375409.37..270896866.33 rows=1408582784 width=21)"
" Sort Key: cf.tagindex, cf.dateandtime"
" -> Seq Scan on contfloattable cf (cost=0.00..24443053.84 rows=1408582784 width=21)"
" -> Hash (cost=335.74..335.74 rows=16474 width=44)"
" -> Seq Scan on conttagtable t (cost=0.00..335.74 rows=16474 width=44)"
Sembra essere aumentato nel tempo :( Tuttavia, se rimuovo l'ordine per clausola (non esattamente quello di cui ho bisogno, ma funzionerebbe), ecco cosa succede, grande riduzione:
"Hash Join (cost=319669581.62..1127631600.98 rows=65462975340 width=57)"
" Hash Cond: (cf.tagindex = t.tagindex)"
" CTE i"
" -> HashAggregate (cost=49093252.56..49490287.76 rows=19851760 width=12)"
" -> Seq Scan on contfloattable cf (cost=0.00..38528881.68 rows=1408582784 width=12)"
" -> Merge Join (cost=270178752.20..298499296.08 rows=1408582784 width=25)"
" Merge Cond: ((i.tagindex = cf.tagindex) AND (i.dateandtime = cf.dateandtime))"
" -> Sort (cost=2803342.82..2852972.22 rows=19851760 width=12)"
" Sort Key: i.tagindex, i.dateandtime"
" -> CTE Scan on i (cost=0.00..397035.20 rows=19851760 width=12)"
" -> Materialize (cost=267375409.37..274418323.29 rows=1408582784 width=21)"
" -> Sort (cost=267375409.37..270896866.33 rows=1408582784 width=21)"
" Sort Key: cf.tagindex, cf.dateandtime"
" -> Seq Scan on contfloattable cf (cost=0.00..24443053.84 rows=1408582784 width=21)"
" -> Hash (cost=335.74..335.74 rows=16474 width=44)"
" -> Seq Scan on conttagtable t (cost=0.00..335.74 rows=16474 width=44)"
Non ho ancora provato questo indice... lo farò comunque. standby.
Ora guardandolo di nuovo penso che l'indice inverso potrebbe essere ancora migliore in quanto può essere utilizzato non solo nel Merge Join ma anche nel Sort finale :
create index cf_tag_datetime on contfloattable (dateandtime, tagindex)