PostgreSQL viene fornito con un eccellente set di funzionalità, senza eguali nello spazio RDBMS open source. È per lo più facile da imparare e da usare, specialmente per gli sviluppatori di applicazioni. Tuttavia, alcune parti sono, beh, semplicemente non facili. Richiedono lavoro per essere configurati e corretti e in genere sono anche mission-critical.
Gestione della connessione
PostgreSQL lancia un nuovo processo, chiamato processo back-end , per gestire ogni connessione. Ciò è in contrasto con le moderne architetture di gestione delle connessioni basate su eventloop/threadpool che si trovano in altri software server comparabili. La generazione di un processo completo richiede più tempo e risorse e si manifesta con un aumento delle latenze delle query nelle applicazioni in cui le connessioni vengono aperte e chiuse a una velocità elevata.
Nella maggior parte delle distribuzioni, il pool di connessioni è richiesto a un certo livello. A livello di applicazione, questo può essere l'utilizzo delle funzionalità del tuo linguaggio di programmazione/libreria. Ad esempio sql/DB.SetMaxIdleConns può essere utilizzato per aumentare il riutilizzo della connessione da una singola applicazione Go.
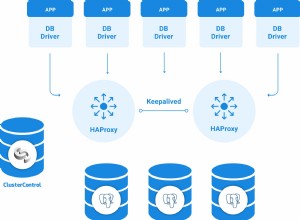
Spesso, tuttavia, dovrai utilizzare un pool di connessioni di terze parti o una soluzione di bilanciamento del carico. I pool di connessioni mantengono un pool di connessioni inattive al server Postgres a monte, che vengono assegnate e inviate tramite proxy alle connessioni client in entrata. In genere analizzano l'SQL inviato dai client per riconoscere i limiti delle transazioni e i DML di modifica dei dati per implementare funzionalità come il pool di connessioni a livello di transazione e le repliche di lettura.
PgBouncer è un popolare pooler a connessione singola, leggero e spesso eseguito insieme a PostgreSQL nello stesso sistema.
PgPool è più versatile di PgBouncer. Ad esempio, può anche eseguire il bilanciamento del carico e la replica.
Tuttavia, il pool di connessioni porta una serie di mal di testa. In primo luogo, è un'ulteriore parte mobile che è stata mantenuta nella distribuzione. Anche l'impostazione dell'autenticazione è una seccatura se si dispone di client che utilizzano credenziali o meccanismi di autenticazione diversi. Alcune funzionalità a livello di connessione come LISTEN/NOTIFY, istruzioni preparate, tabelle temporanee e simili potrebbero richiedere una configurazione aggiuntiva o modifiche al lato client per funzionare.
Aggiornamenti a zero tempi di inattività
L'aggiornamento di PostgreSQL tra versioni minori (13.x -> 13.y) comporta l'installazione del nuovo pacchetto e il riavvio del processo del server. Anche se il riavvio del processo del server interromperà necessariamente tutti i client connessi, è comunque una richiesta ragionevole, dato che il tempo di inattività è legato alla durata di un riavvio del servizio.
L'aggiornamento tra le versioni principali (12.x -> 13.y), tuttavia, è molto più importante. In genere, più dati ci sono, più doloroso è il processo.
Il metodo più semplice, che funziona solo per piccole quantità di dati (diciamo decine di GB), è scaricare i dati dalla vecchia versione e ripristinarli in un server di nuova versione. Un'altra opzione è usare pg_upgrade, che richiede una danza orchestrata che coinvolgono i binari di entrambe le versioni di Postgres.
In entrambi i casi, i database rimarrebbero inattivi per un considerevole lasso di tempo.
Idealmente, dovrebbe essere possibile replicare su un nuovo server di versione e promuovere il nuovo server di versione come server primario. Tuttavia, non è possibile eseguire la replica in streaming su un server di standby con una versione principale diversa. La replica logica, sebbene sembri adatta al lavoro, ha alcuni problemi che devono essere aggirati per garantire la replica completa.
La maggior parte delle soluzioni HA per Postgres si basa sulla replica in streaming, pertanto non è possibile aggiornare i nodi in un cluster uno alla volta.
L'attuale stato dell'arte consiste nell'utilizzare la replica logica, aggirando i limiti della replica logica e possibilmente implicando funzionalità restrittive che le applicazioni possono utilizzare (come i DDL) durante la fase di aggiornamento.
Alta disponibilità
PostgreSQL viene fornito con tutte le funzionalità di basso livello necessarie per creare una soluzione HA:replica con feedback, replica a cascata, replica sincrona, standby, hot standby, promozione standby e così via. Tuttavia, in realtà non fornisce una soluzione HA pronta all'uso. Non sono disponibili framework o strumenti per monitorare lo stato e il failover automatico in standby. Non esiste la nozione di cluster HA multinodo.
Dovrai configurare ed eseguire una soluzione di terze parti per creare distribuzioni Postgres ad alta disponibilità. I preferiti attuali sonopg_auto_failover e Patroni. Mentre Patroni fa affidamento su un archivio di configurazione ad alta disponibilità esistente come ZooKeeper o etcd, pg_auto_failover può farne a meno.
Valutare, implementare e testare uno di questi in produzione richiede tempo e fatica. I playbook di monitoraggio, avvisi e operazioni devono essere impostati e gestiti.
Gestione del volume
L'architettura MVCC di PostgreSQL significa che nessun dato viene mai sovrascritto:la modifica di una riga comporta solo la scrittura di una nuova versione della riga su disco. Eliminare una riga significa solo registrare che la riga è invisibile alle transazioni future. Quando una versione di riga è inaccessibile da qualsiasi transazione in corso o futura non è più di alcuna utilità e viene definita "gonfiore". Il processo di raccolta dei rifiuti di questo rigonfiamento è chiamato "vuoto".
Il rigonfiamento è invisibile alle applicazioni e diventa solo il mal di testa del DBA. Per le tabelle con aggiornamenti pesanti, il monitoraggio e la gestione del rigonfiamento è un problema non banale. Il processo di autovacuum aiuta molto, ma potrebbe essere necessario regolare le sue soglie a livello globale o per- tablelevel per garantire che le dimensioni delle tabelle non crescano in modo ingestibile.
Anche gli indici sono influenzati dal rigonfiamento e l'autovuoto non aiuta qui. L'eliminazione delle righe e l'aggiornamento delle colonne indicizzate portano a voci morte negli indici. Carichi di lavoro pesanti con aggiornamenti alle colonne indicizzate possono portare a indici in costante crescita e inefficienti. Non esiste un equivalente del vuoto per gli indici. L'unica soluzione è ricostruire l'intero indice utilizzando REINDEX o utilizzare VACUUM FULL sul tavolo.
A parte un singolo valore per tabella (pg_stat_all_tables.n_dead_tup), Postgres non offre nulla in termini di stima del rigonfiamento in una tabella e niente per gli indici. Il modo più pratico rimane comunque l'esecuzione di una query dall'aspetto spaventoso da check_postgres.
pgmetrics incorpora la query di check_postgres e può produrre output in formato JSON e CSV che include informazioni su dimensioni e bloat per tutte le tabelle e gli indici; che possono essere inseriti in strumenti di monitoraggio o automazione.
pg_repack è un'alternativa popolare aVACUUM FULL:può fare lo stesso lavoro ma senza blocchi. Se sei costretto a fare regolarmente VACUUM FULL, è uno strumento da investigare.
zheap è il nuovo motore di archiviazione perPostgres in sviluppo da anni, che promette di ridurre il rigonfiamento grazie agli aggiornamenti sul posto.
Gestione del piano delle query
Core PostgreSQL offre solo due strumenti rudimentali in questo spazio:
- pg_stat_statements estensione per l'analisi delle query:fornisce il totale e le medie dei tempi di pianificazione e esecuzione delle query, dell'utilizzo del disco e della memoria
- auto_explain estensione, che può stampare i piani di esecuzione delle query nella destinazione del registro di Postgres
Mentre le statistiche fornite da pg_stat_statements sono appena sufficienti per cavarsela, usando auto_explain forzare i piani nei file di registro e quindi estrarli non è altro che un hack soprattutto rispetto ai concorrenti commerciali di Postgres, che offrono funzionalità di cronologia, baseline e gestione dei piani.
L'attuale stato dell'arte con Postgres è quello di estrarre i piani di query del file di registro e archiviarli altrove. Ma forse il problema più handicappante è non essere in grado di associare il piano di query con l'analitica corrispondente da pg_stat_statements. Il modo in cui pgDash fa questo è analizzare entrambi i testi della query SQL da pg_stat_statements e auto_explain output, regolare per la manipolazione eseguita da pg_stat_statements e provare a far corrispondere i due. Richiede un parser SQL completo in dialetto PostgreSQL.
La definizione di base, l'impostazione di criteri per la selezione dei piani, ecc. non sono attualmente possibili in PostgreSQL di base.
Esistono alcune estensioni che sono sostanzialmente versioni migliorate di pg_stat_statements, ma i passaggi aggiuntivi coinvolti nell'utilizzo di un'estensione di terze parti lo rendono una sfida per la maggior parte delle persone, soprattutto se utilizzano un provider Postgres gestito.
Ottimizzazione
PostgreSQL ha una pletora di opzioni di ottimizzazione, a partire da under-configurated-by-defaultshared_bufferssetting. Alcuni sono facili da capire e impostare, come il numero di lavoratori paralleli per varie operazioni (max_worker_processes, max_parallel_* ecc.). Altri sono un po' oscuri (wal_compression, random_page_cost ecc.) ma generalmente vantaggiosi. I più fastidiosi, però, sono quelli che necessitano di informazioni quantificabili sul carico di lavoro.
Ad esempio, se work_mem è troppo basso, le query potrebbero utilizzare file del disco temporanei; se è troppo alto e ci sono abbastanza query simultanee, i processi di backend di Postgres potrebbero essere uccisi dall'OOM. Quindi, come fai a capire su quale numero impostarlo?
In pratica, soprattutto con carichi di lavoro OLTP e carichi di lavoro di applicazioni Web, è impossibile prevedere quale sarebbe il picco di richiesta di memoria per le query. La soluzione migliore è impostarlo su un valore ragionevole, quindi monitorare le query per vedere se qualcuno di loro avrebbe potuto beneficiare di un valore più alto di work_mem.
E come lo fai? Dovrai ottenere l'estensione auto_explain per registrare i piani di esecuzione delle query di ciascuna query, estrarli dai file di registro di Postgres, esaminare ciascun piano di query per vedere se utilizza unioni esterne basate su disco o scansioni dell'heap bitmap con blocchi dell'heap con perdita.
Non impossibile, solo difficile.