I registri delle transazioni sono una componente vitale e importante dell'architettura del database. In questo articolo parleremo dei log delle transazioni di SQL Server, dell'importanza e del loro ruolo nella migrazione del database.
Introduzione
Parliamo di diverse opzioni per eseguire i backup di SQL Server. SQL Server supporta tre diversi tipi di backup.
1. Completo
2. Differenziale
3. Registro delle transazioni
Prima di passare ai concetti del registro delle transazioni, discutiamo di altri tipi di backup di base in SQL Server.
Un backup completo è una copia di tutto. Come suggerisce il nome, eseguirà il backup di tutto. Eseguirà il backup di tutti i dati, ogni oggetto del database come file, file-group, tabelle, ecc.:– Un backup completo è una base per qualsiasi altro tipo di backup.
Un backup differenziale eseguirà il backup dei dati che sono stati modificati dall'ultimo backup completo.
La terza opzione è un backup del registro delle transazioni, che registrerà tutte le istruzioni che emettiamo al database nel registro delle transazioni. Il log delle transazioni è un meccanismo noto come “WAL” (Write-Ahead-Logging). Scrive ogni informazione prima nel registro delle transazioni e poi nel database. In altre parole, il processo in genere non aggiorna direttamente il database. Questa è l'unica opzione disponibile completa con il modello di ripristino completo del database. In altri modelli di ripristino, i dati sono parziali o non ci sono dati sufficienti nel registro. Ad esempio, il record di registro durante la registrazione dell'inizio di una nuova transazione (il record di registro LOP_BEGIN_XACT) conterrà l'ora di inizio della transazione e i record di registro LOP_COMMIT_XACT (o LOP_ABORT_XACT) registreranno l'ora in cui la transazione è stata confermata (o interrotta).
Per trovare gli elementi interni del registro delle transazioni online, puoi eseguire una query sulla funzione sys.fn_dblog.
La funzione di sistema sys.fn_dblog accetta due parametri, primo, inizio LSN e fine LSN della transazione. Per impostazione predefinita, è impostato su NULL. Se è impostato su NULL, restituirà tutti i record di registro dal file di registro delle transazioni.
USE WideWorldImporters GO SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Log Record Fixed Length], [Log Record Length] [Transaction SID], [SPID], [Begin Time], * FROM fn_dblog(null,null)

Come tutti sappiamo, le transazioni sono memorizzate in formato binario e non è in un formato leggibile. Per leggere il file di registro delle transazioni offline, puoi utilizzare fn_dump_dblog.
interroghiamo il file di registro delle transazioni per vedere chi ha abbandonato l'oggetto utilizzando fn_dump_dblog.
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], SUSER_SNAME ([Transaction SID]) AS DBUser
FROM fn_dump_dblog (
NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE
Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT')
AND [Transaction Name] LIKE '%DROP%'
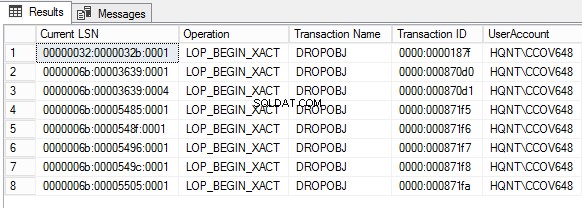
Useremo la funzione fn_dblog() per leggere la parte attiva del log delle transazioni per trovare l'attività che viene eseguita sui dati. Una volta cancellato il registro delle transazioni, è necessario eseguire una query sui dati da un file di registro utilizzando fn_dump_dblog().
Questa funzione fornisce lo stesso set di righe di fn_dblog(), ma ha alcune funzionalità interessanti che lo rendono utile in alcuni scenari di risoluzione dei problemi e ripristino. In particolare, può leggere non solo il registro delle transazioni del database corrente, ma anche i backup dei registri delle transazioni su disco o nastro.
Per ottenere l'elenco degli oggetti eliminati utilizzando il file di transazione, eseguire la query seguente. Inizialmente, i dati vengono scaricati nella tabella temporanea. In alcuni casi, l'esecuzione di fun_dump_dblog() richiede un po' più di tempo per essere eseguita. Quindi, è meglio acquisire i dati nella tabella temporanea.
Per ottenere un ID oggetto dalla colonna Informazioni sul blocco, esegui la query seguente.
SELECT * INTO TEMP FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction ID] in( SELECT DISTINCT [Transaction ID] FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction Name] LIKE '%DROP%') and [Lock Information] like '%ACQUIRE_LOCK_SCH_M OBJECT%'
Per ottenere un ID oggetto dalla colonna Informazioni sul blocco, esegui la query seguente.
SELECT DISTINCT [Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4,
Substring([Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4) objectid
from temp
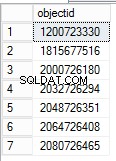
L'object_id può essere trovato manipolando il valore della colonna Lock Information. Per trovare il nome dell'oggetto per l'ID oggetto corrispondente, ripristinare il database dal backup subito prima che la tabella venisse eliminata. Dopo il ripristino, puoi interrogare la vista di sistema per ottenere il nome dell'oggetto.
USE AdventureWorks2016; GO SELECT name, object_id from sys.objects WHERE object_id = '1815677516';
Ora, vediamo le diverse forme degli stessi dettagli di transazione utilizzando sys.dn_dblog, sys.fn_full_dblog. La funzione di sistema fn_full_dblog funziona solo con SQL Server 2017.
Interroga per recuperare le prime 10 transazioni utilizzando fn_dblog.
SELECT TOP 10 * FROM sys.fn_dblog(null,null)

Da SQL Server 2017 in poi, puoi usare fn_full dblog.
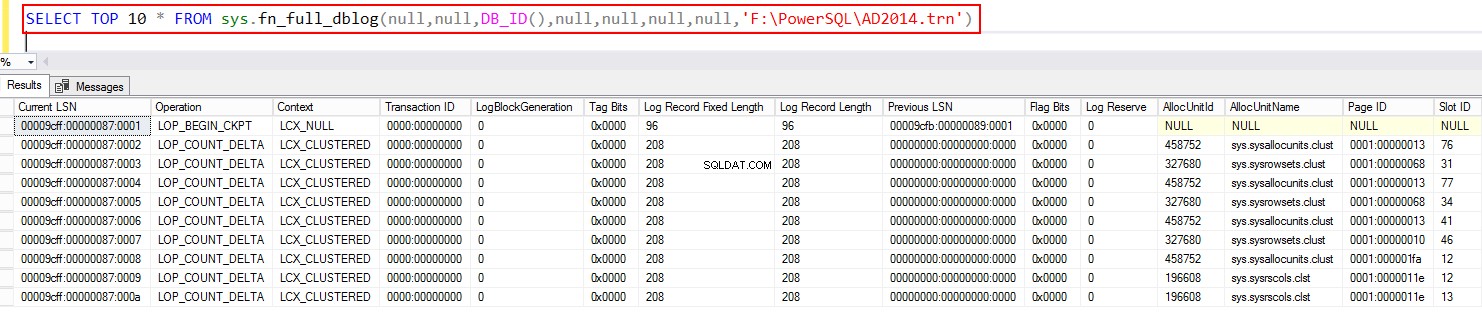
SELECT TOP 10 * FROM sys.fn_full_dblog(null,null,DB_ID(),null,null,null,null,NULL)

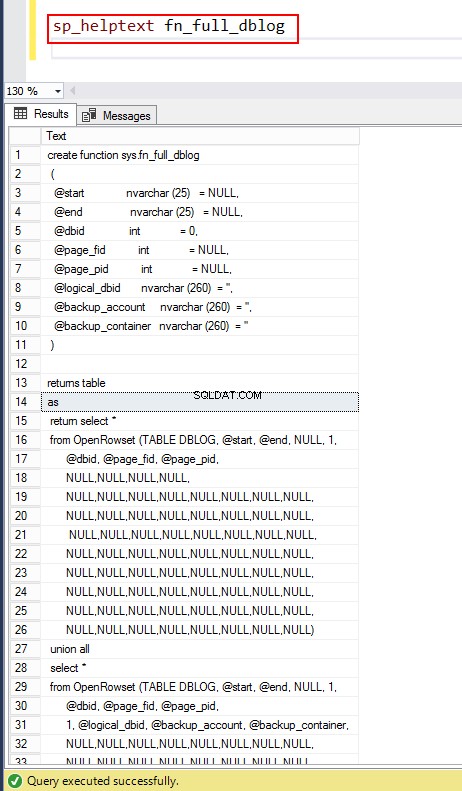
Puoi approfondire ulteriormente la funzione di sistema usando sp_helptext fn_full_dblog.
Quindi, interroga il file di backup usando la funzione di sistema usando fn_full_dblog. Anche in questo caso, questo è applicabile solo da SQL Server 2017 in poi.
Ripristino puntuale
Supponiamo che tu abbia l'elenco dell'intero backup del registro, quindi quando intendi ripristinare i registri, hai la possibilità di eseguire un ripristino point-in-time dei dati. Pertanto, nel processo di ripristino del registro, non è necessario ripristinare tutti i dati, è possibile ripristinarli fino a, prima o dopo ogni singola transazione. Quindi, se il database si arresta in modo anomalo in un momento specifico e disponiamo sia di backup completo che di backup del registro, dovremmo essere in grado di ripristinare prima il backup completo e quindi ripristinare il backup del registro e, nel processo, ripristinare l'ultimo registro fino a un determinato momento , e ciò lascerebbe il database nello stato esatto in cui si trovava prima che si verificasse questo problema.
I backup dei log sono VLDB (Very Large Database) piuttosto comuni e i database più critici. Si consiglia sempre di testare il processo di ripristino. Ogni volta che si eseguono backup del database, si consiglia di pensare bene al processo di ripristino e di testare sempre il processo di ripristino più spesso.
È sempre utile alleviare il test del processo di ripristino di tanto in tanto, quindi assicurati solo che il processo esegua i backup normalmente.
Scenari
Parliamo di uno scenario, in cui è necessario ripristinare un database molto grande e sappiamo tutti che normalmente può richiedere diverse ore, ed è qualcosa di cui tutti dovrebbero essere consapevoli. Se stai pianificando la migrazione del database con zero perdite di dati e finestre di interruzione più piccole, potrebbe comunque essere un grosso problema. Quindi assicurati di fare affidamento sul backup del registro delle transazioni per accelerare il processo.
Consideriamo un altro scenario in cui stai eseguendo una migrazione di database affiancata tra due diverse versioni di SQL Server; sei coinvolto nella migrazione del database alla stessa versione del software sulla destinazione e ciò include il trasferimento di sistema operativo, database, applicazione e rete ecc:-; migrazione del database da un componente hardware a un altro; cambiare sia il software che l'hardware. Il processo di migrazione del database è sempre la sfida in cui la perdita di dati è sempre possibile ed è soggetta all'ambiente.
Best practice per la migrazione del database
Discutiamo le pratiche standard di gestione della migrazione del database.
La migrazione deve essere eseguita in modo transazionale per evitare incoerenze nei dati. I soliti passaggi del processo di migrazione sono convenzionalmente i seguenti:
- Interrompi il servizio dell'applicazione:è qui che iniziano i tempi di inattività
- Avvia il backup del registro, dipende dalle tue esigenze
- Imposta il database in modalità di ripristino in modo che non vengano apportate ulteriori modifiche al database
- Sposta i file di registro
- Ripristina i file di registro delle transazioni del database:a condizione che tu abbia già ripristinato il backup completo del database sulla destinazione e lasciato il database in stato di ripristino.
- Clone gli accessi e correggi gli utenti orfani
- Crea lavori
- Installa l'applicazione
- Configura rete:modifica le voci DNS
- Riconfigura le impostazioni dell'applicazione
- Avvia il servizio dell'applicazione
- Verifica l'applicazione
Per iniziare
In questo articolo, discuteremo come gestire la migrazione di database OLTP di grandi dimensioni. Discuteremo le strategie per utilizzare le tecniche del server SQL e gli strumenti di terze parti per la sicurezza dei dati insieme a un'interruzione minima o nulla della disponibilità del sistema di produzione. Durante il processo, c'è sempre la possibilità di perdere i dati. Pensi che la gestione senza interruzioni delle transazioni sia una buona strategia? Se "sì", quali sono le tue opzioni preferite?
Approfondiamo le opzioni disponibili:
- Backup e ripristino
- Spedizione log
- Mirroring del database
- Strumenti di terze parti
Backup e ripristino
La tecnica di backup e ripristino del database è l'opzione più praticabile per qualsiasi migrazione del database. Se è pianificato e testato correttamente, eviteremo molti errori di migrazione imprevisti. Sappiamo tutti che il backup è un processo online, è facile avviare il backup del registro delle transazioni in modo tempestivo per restringere il numero di transazioni da fornire al nuovo database. Durante la finestra di migrazione, possiamo limitare l'accesso degli utenti al database e avviare un ultimo backup del registro e trasferirlo alla destinazione. In questo modo è possibile ridurre notevolmente i tempi di fermo macchina.
Spedizione log
Comprendiamo tutti l'importanza dei file di registro nel mondo dei database. La tecnica di log shipping offre una buona soluzione di ripristino di emergenza e supporta un accesso limitato in sola lettura ai database secondari, durante l'intervallo tra i processi di ripristino. È essenzialmente un concetto di backup del registro delle transazioni e viene riprodotto su un backup completo su un altro database secondario. Questi database secondari sono copie duplicate del database primario e ripristinano continuamente i backup del registro delle transazioni sulla propria copia, al fine di mantenerlo sincronizzato con il database primario. Poiché il database secondario si trova su hardware separato, in caso di guasto del database primario per qualsiasi motivo, la copia di backup completa del sistema è immediatamente disponibile per l'uso e il traffico di rete può essere semplicemente reindirizzato al server secondario, senza che gli utenti sappiano che un si è verificato un errore. Il log shipping offre un modo semplice ed efficace per gestire la migrazione in misura maggiore nella maggior parte dei casi.
Mirroring
Il mirroring del database è anche un'opzione per la migrazione del database a condizione che sia l'origine che la destinazione siano delle stesse versioni ed edizioni. In sostanza, il mirroring crea due copie duplicate di un database su due istanze hardware. Le transazioni avverrebbero simultaneamente su entrambi i database. Hai la possibilità di portare offline un database di produzione, passare alla versione con mirroring di quel database e consentire agli utenti di continuare ad accedere ai dati come se nulla fosse. In termini di implementazione, ci occupiamo di un server principale, un server mirror e un testimone. Ma sarà una funzionalità deprecata e verrà rimossa dalle versioni future di SQL Server.
Riepilogo
In questo articolo, abbiamo discusso i tipi di backup, il backup del registro delle transazioni in dettaglio, gli standard di migrazione dei dati, il processo e la strategia, abbiamo imparato a utilizzare le tecniche SQL per una gestione efficace delle fasi di migrazione dei dati.
Il meccanismo di scrittura del registro delle transazioni WAL garantisce che le transazioni vengano sempre scritte per prime nel file di registro. In questo modo, SQL Server garantisce che gli effetti di tutte le transazioni salvate verranno alla fine scritti nei file di dati (su disco) e che qualsiasi modifica dei dati su disco originata da transazioni incomplete sarà ROLLBACK e non si rifletterà nei file di dati.
Nella maggior parte dei casi, il ritardo nella sincronizzazione dei dati è imprevisto e la perdita di dati è permanente. Il più delle volte, tutto dipende dalle dimensioni del database e dall'infrastruttura disponibile. Come pratica consigliata, è meglio eseguire le migrazioni manualmente piuttosto che come parte della distribuzione per mantenere le cose separate in modo che l'output possa essere più prevedibile.
Personalmente, preferirei la spedizione dei log per vari motivi:puoi eseguire un backup completo dei dati dal vecchio server con largo anticipo, trasferirlo sul nuovo server, ripristinarlo e quindi applicare le transazioni residue (backup t-log ) dal punto fino al momento del cutover. Il processo è in realtà abbastanza semplice.
La migrazione del database non è difficile se eseguita nel modo giusto. Spero che questo post ti aiuti a eseguire le migrazioni del database in modo più fluido.



