Al giorno d'oggi, è comune vedere una grande quantità di dati nel database di un'azienda, ma a seconda delle dimensioni, potrebbe essere difficile da gestire e le prestazioni potrebbero essere compromesse durante il traffico elevato se non lo configuriamo o implementiamo in modo corretto . In generale, se abbiamo un database enorme e vogliamo avere un tempo di risposta basso, vorremo ridimensionarlo. PostgreSQL non fa eccezione a questo punto. Esistono molti approcci disponibili per ridimensionare PostgreSQL, ma prima impariamo cos'è il ridimensionamento.
La scalabilità è la proprietà di un sistema/database per gestire una quantità crescente di richieste aggiungendo risorse.
Le ragioni di questa quantità di richieste potrebbero essere temporali, ad esempio, se stiamo lanciando uno sconto su una vendita, o permanente, per un aumento di clienti o dipendenti. In ogni caso, dovremmo essere in grado di aggiungere o rimuovere risorse per gestire questi cambiamenti in base alle richieste o all'aumento del traffico.
In questo blog, vedremo come possiamo ridimensionare il nostro database PostgreSQL e quando è necessario farlo.
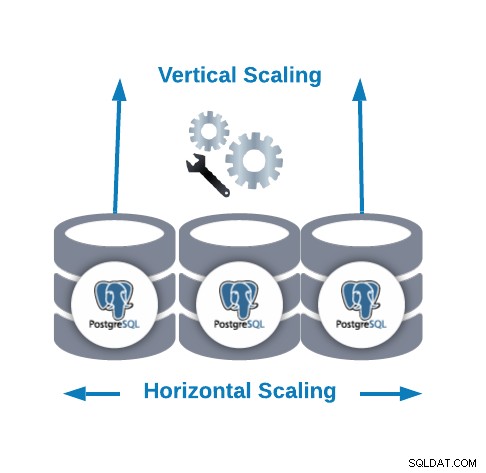
Ridimensionamento orizzontale e ridimensionamento verticale
Esistono due modi principali per ridimensionare il nostro database...
- Ridimensionamento orizzontale (scale-out):viene eseguito aggiungendo più nodi di database creando o aumentando un cluster di database.
- Ridimensionamento verticale (scale-up):viene eseguito aggiungendo più risorse hardware (CPU, memoria, disco) a un nodo di database esistente.
Per il ridimensionamento orizzontale, possiamo aggiungere più nodi di database come nodi slave. Può aiutarci a migliorare le prestazioni di lettura bilanciando il traffico tra i nodi. In questo caso, dovremo aggiungere un sistema di bilanciamento del carico per distribuire il traffico al nodo corretto a seconda della policy e dello stato del nodo.
Per evitare un singolo punto di errore aggiungendo un solo servizio di bilanciamento del carico, dovremmo considerare l'aggiunta di due o più nodi del servizio di bilanciamento del carico e l'utilizzo di uno strumento come "Keepalived", per garantire la disponibilità.
Poiché PostgreSQL non ha il supporto multi-master nativo, se vogliamo implementarlo per migliorare le prestazioni di scrittura dovremo utilizzare uno strumento esterno per questa attività.
Per il ridimensionamento verticale, potrebbe essere necessario modificare alcuni parametri di configurazione per consentire a PostgreSQL di utilizzare una risorsa hardware nuova o migliore. Vediamo alcuni di questi parametri dalla documentazione di PostgreSQL.
- work_mem:specifica la quantità di memoria da utilizzare per le operazioni di ordinamento interno e le tabelle hash prima di scrivere su file su disco temporanei. Diverse sessioni in esecuzione potrebbero eseguire tali operazioni contemporaneamente, quindi la memoria totale utilizzata potrebbe essere molte volte il valore di work_mem.
- maintenance_work_mem:specifica la quantità massima di memoria da utilizzare per le operazioni di manutenzione, come VACUUM, CREATE INDEX e ALTER TABLE ADD FOREIGN KEY. Impostazioni più grandi potrebbero migliorare le prestazioni per l'aspirazione e il ripristino dei dump del database.
- autovacuum_work_mem:specifica la quantità massima di memoria che deve essere utilizzata da ciascun processo di lavoro di autovacuum.
- autovacuum_max_workers:specifica il numero massimo di processi di autovacuum che possono essere eseguiti in qualsiasi momento.
- max_worker_processes:imposta il numero massimo di processi in background che il sistema può supportare. Specifica il limite del processo come aspirazione, checkpoint e altri lavori di manutenzione.
- max_parallel_workers:imposta il numero massimo di lavoratori che il sistema può supportare per operazioni parallele. I lavoratori paralleli vengono presi dal pool di processi di lavoro stabiliti dal parametro precedente.
- max_parallel_maintenance_workers:imposta il numero massimo di lavoratori paralleli che possono essere avviati da un singolo comando di utilità. Attualmente, l'unico comando di utilità parallela che supporta l'uso di lavoratori paralleli è CREATE INDEX e solo durante la creazione di un indice B-tree.
- efficace_cache_size:imposta l'ipotesi del pianificatore sulla dimensione effettiva della cache del disco disponibile per una singola query. Questo è preso in considerazione nelle stime del costo dell'utilizzo di un indice; un valore più alto rende più probabile l'utilizzo di scansioni dell'indice, un valore più basso rende più probabile l'utilizzo di scansioni sequenziali.
- shared_buffers:imposta la quantità di memoria utilizzata dal server di database per i buffer di memoria condivisa. Di solito sono necessarie impostazioni significativamente superiori al minimo per ottenere buone prestazioni.
- temp_buffers:imposta il numero massimo di buffer temporanei utilizzati da ciascuna sessione del database. Questi sono buffer locali di sessione utilizzati solo per l'accesso alle tabelle temporanee.
- efficace_io_concurrency:imposta il numero di operazioni di I/O del disco simultanee che PostgreSQL prevede possano essere eseguite simultaneamente. L'aumento di questo valore aumenterà il numero di operazioni di I/O che ogni singola sessione PostgreSQL tenta di avviare in parallelo. Attualmente, questa impostazione influisce solo sulle scansioni dell'heap bitmap.
- max_connections:determina il numero massimo di connessioni simultanee al server di database. L'aumento di questo parametro consente a PostgreSQL di eseguire più processi di back-end contemporaneamente.
A questo punto, c'è una domanda che dobbiamo porci. Come possiamo sapere se abbiamo bisogno di ridimensionare il nostro database e come possiamo sapere il modo migliore per farlo?
Monitoraggio
Il ridimensionamento del nostro database PostgreSQL è un processo complesso, quindi dovremmo controllare alcune metriche per poter determinare la migliore strategia per ridimensionarlo.
Possiamo monitorare l'utilizzo di CPU, memoria e disco per determinare se ci sono problemi di configurazione o se effettivamente è necessario ridimensionare il nostro database. Ad esempio, se vediamo un carico elevato del server ma l'attività del database è bassa, probabilmente non è necessario ridimensionarlo, dobbiamo solo controllare i parametri di configurazione per abbinarlo alle nostre risorse hardware.
Il controllo dello spazio su disco utilizzato dal nodo PostgreSQL per database può aiutarci a confermare se abbiamo bisogno di più disco o anche di un partizionamento di una tabella. Per controllare lo spazio su disco utilizzato da un database/tabella possiamo usare alcune funzioni PostgreSQL come pg_database_size o pg_table_size.
Dal lato del database, dovremmo controllare
- Quantità di connessione
- Esecuzione di query
- Utilizzo dell'indice
- Gonfia
- Ritardo di replica
Queste potrebbero essere metriche chiare per confermare se è necessario ridimensionare il nostro database.
ClusterControl come sistema di dimensionamento e monitoraggio
ClusterControl può aiutarci a far fronte a entrambi i modi di ridimensionamento visti in precedenza ea monitorare tutte le metriche necessarie per confermare il requisito di ridimensionamento. Vediamo come...
Se non stai ancora utilizzando ClusterControl, puoi installarlo e distribuire o importare il tuo attuale database PostgreSQL selezionando l'opzione "Importa" e segui i passaggi per sfruttare tutte le funzionalità di ClusterControl come backup, failover automatico, avvisi, monitoraggio, e altro ancora.
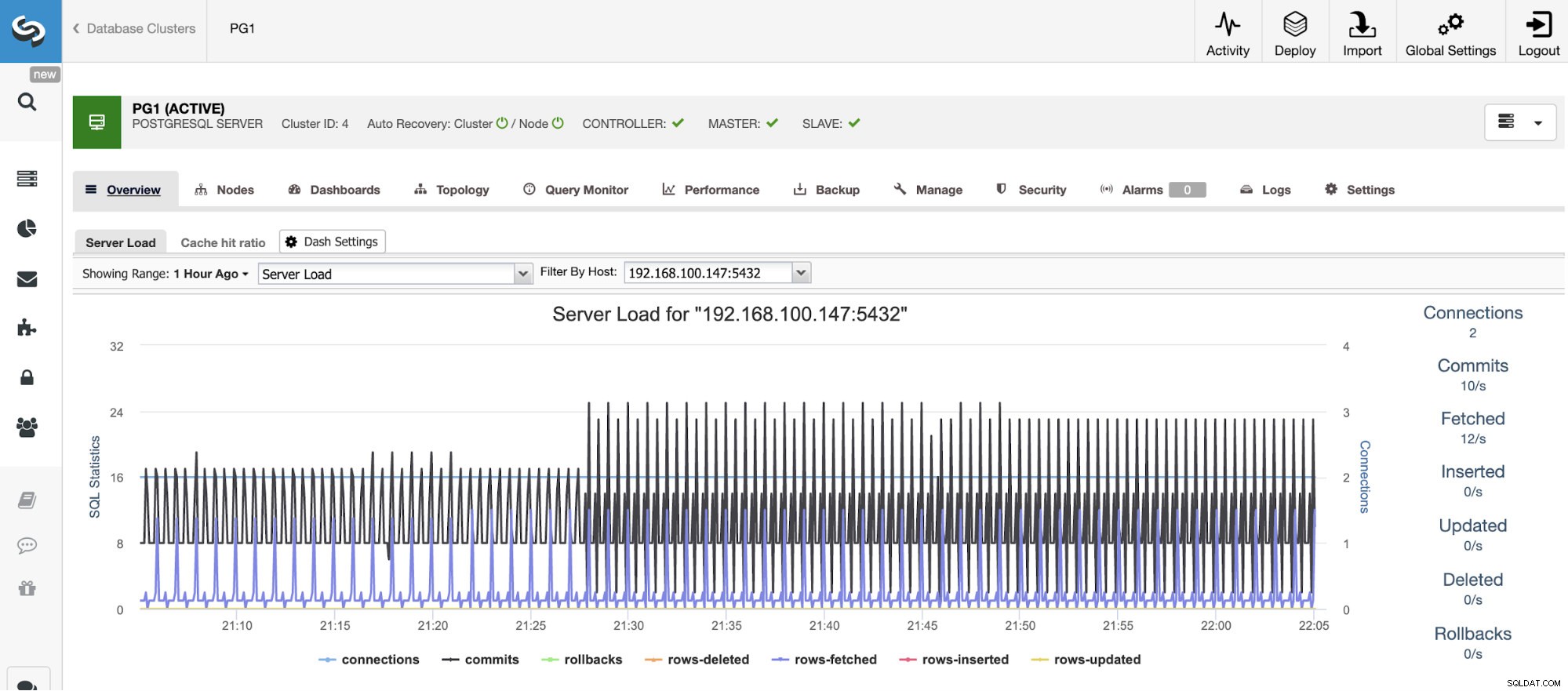
Ridimensionamento orizzontale
Per il ridimensionamento orizzontale, se andiamo alle azioni del cluster e selezioniamo "Aggiungi slave di replica", possiamo creare una nuova replica da zero o aggiungere un database PostgreSQL esistente come replica.
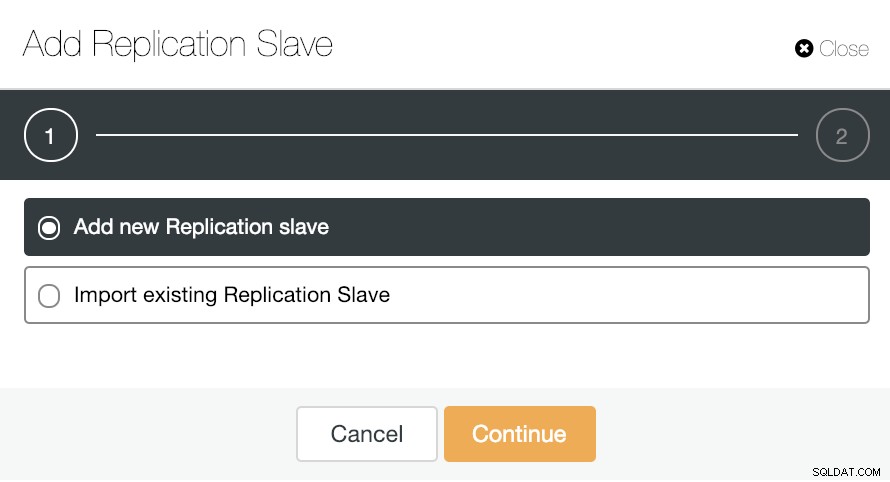
Vediamo come aggiungere un nuovo slave di replica può essere un compito davvero facile.
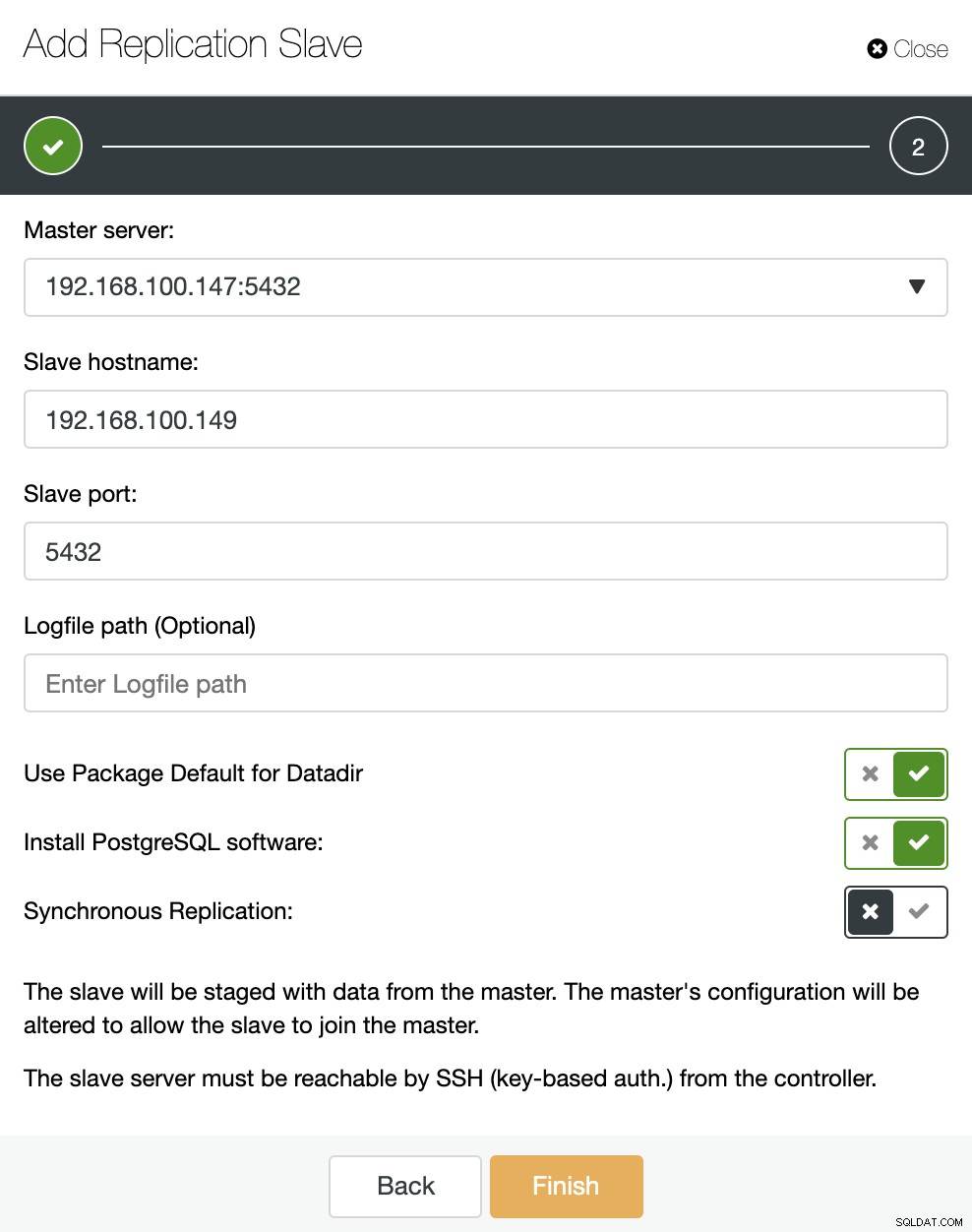
Come puoi vedere nell'immagine, dobbiamo solo scegliere il nostro server Master, inserire l'indirizzo IP per il nostro nuovo server slave e la porta del database. Quindi, possiamo scegliere se vogliamo che ClusterControl installi il software per noi e se lo slave di replica deve essere sincrono o asincrono.
In questo modo, possiamo aggiungere tutte le repliche che vogliamo e distribuire il traffico di lettura tra di loro utilizzando un bilanciatore di carico, che possiamo implementare anche con ClusterControl.
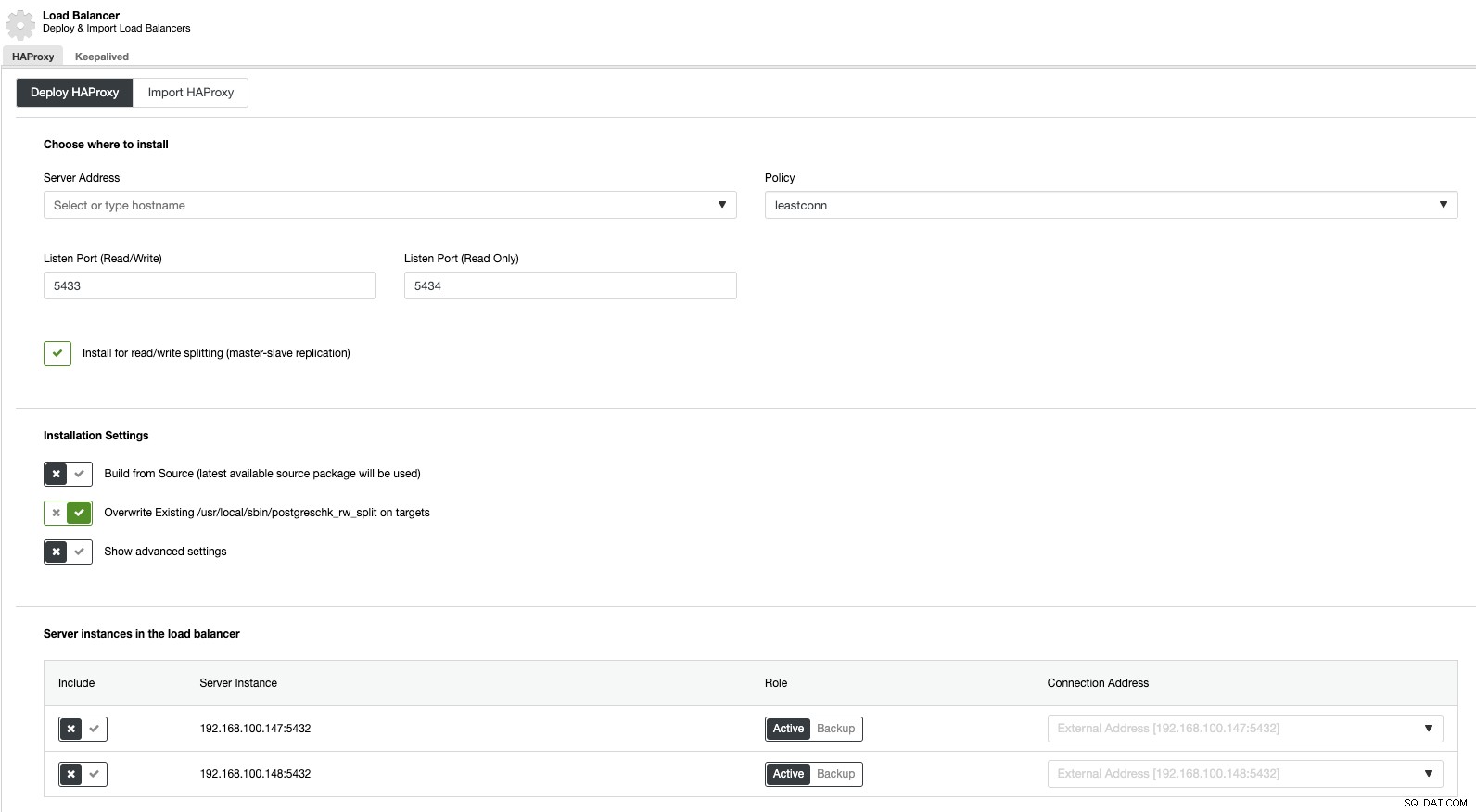
Ora, se andiamo alle azioni del cluster e selezioniamo "Aggiungi Load Balancer", possiamo distribuire un nuovo HAProxy Load Balancer o aggiungerne uno esistente.
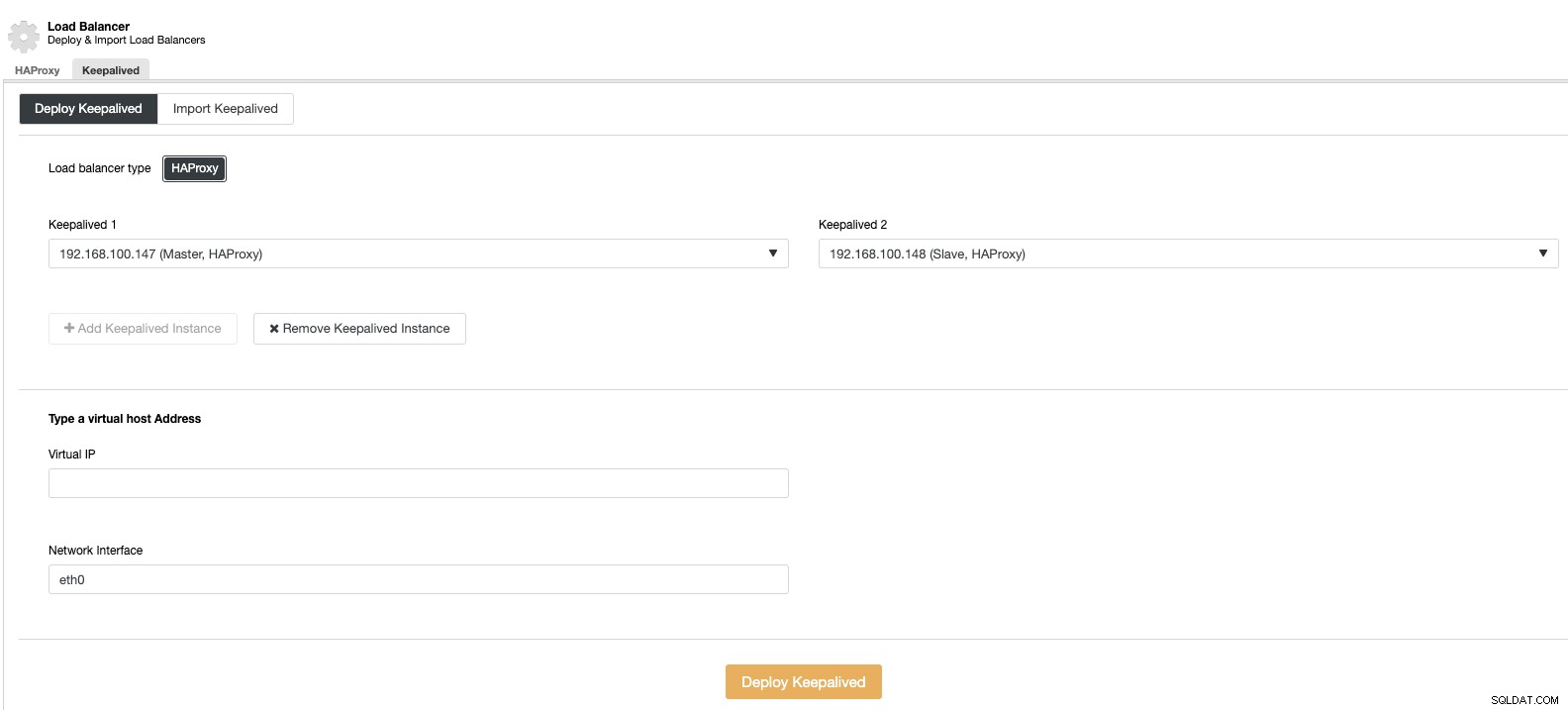
E poi, nella stessa sezione del servizio di bilanciamento del carico, possiamo aggiungere un servizio Keepalived in esecuzione sui nodi del servizio di bilanciamento del carico per migliorare il nostro ambiente ad alta disponibilità.
Ridimensionamento verticale
Per il ridimensionamento verticale, con ClusterControl possiamo monitorare i nostri nodi di database sia dal sistema operativo che dal lato database. Possiamo controllare alcune metriche come l'utilizzo della CPU, la memoria, le connessioni, le query principali, le query in esecuzione e altro ancora. Possiamo anche abilitare la sezione Dashboard, che ci consente di vedere le metriche in modo più dettagliato e in modo più semplice le nostre metriche.
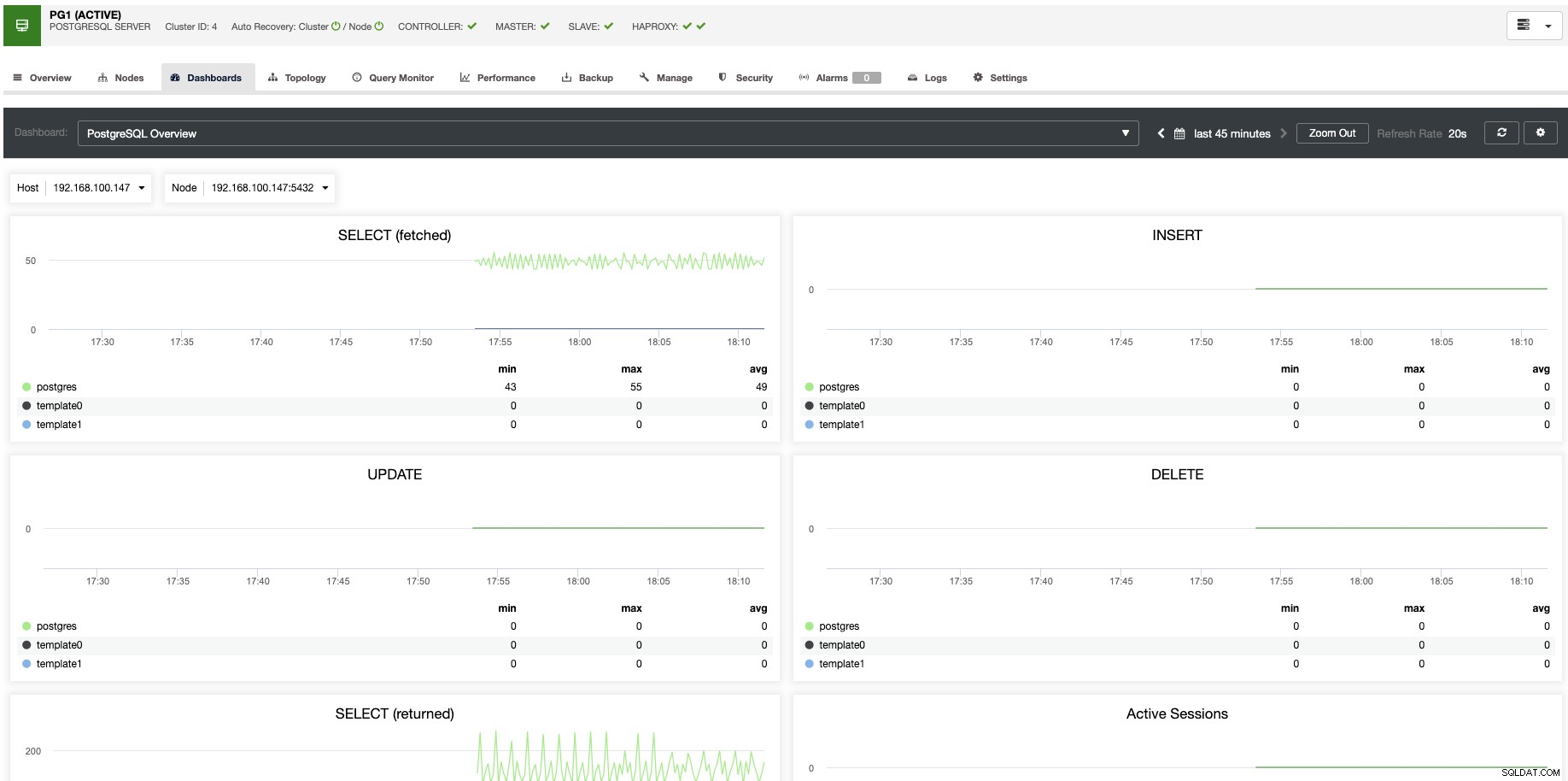
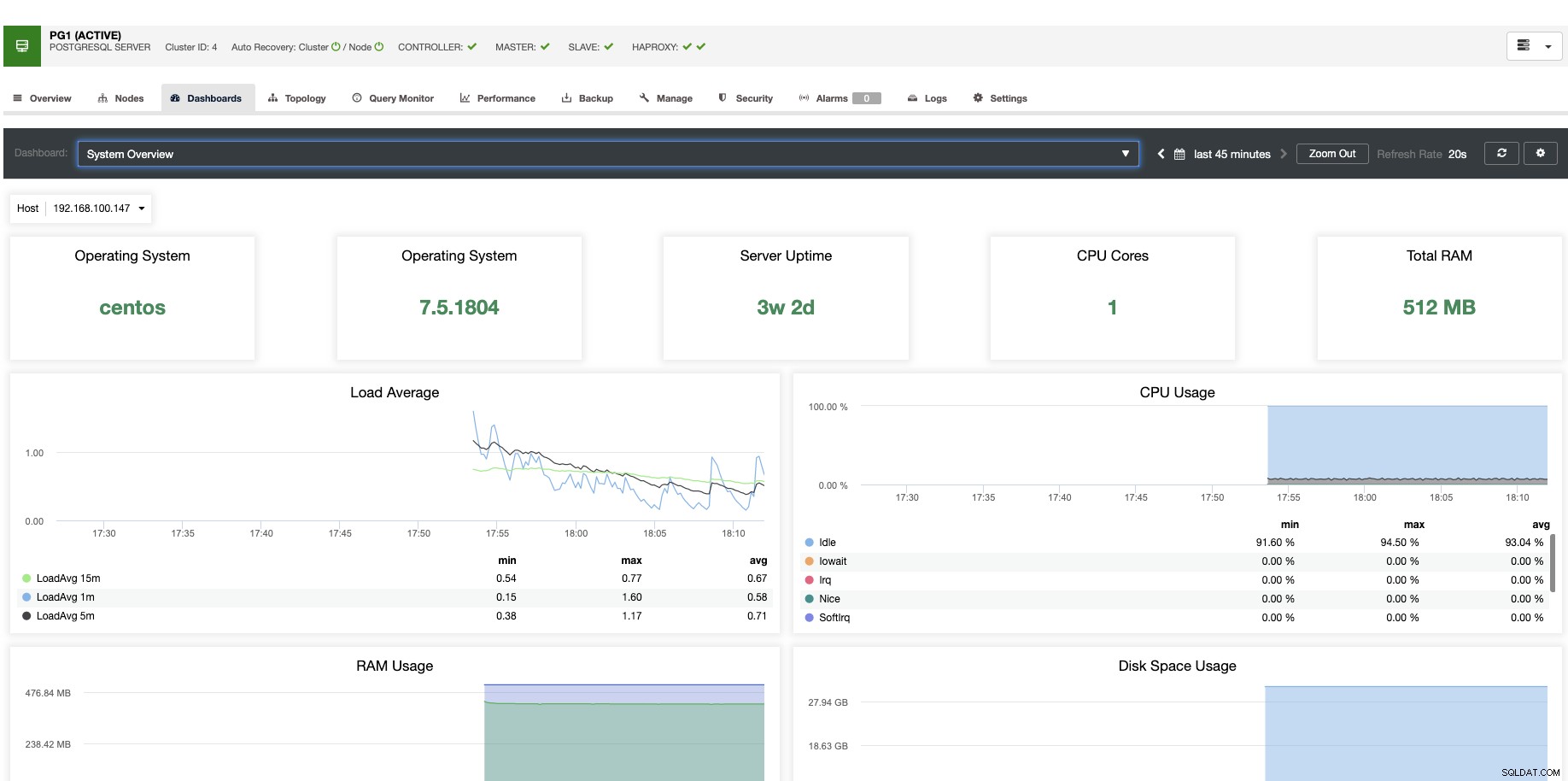
Da ClusterControl puoi anche eseguire diverse attività di gestione come Reboot Host, Rebuild Replication Slave o Promuovi Slave, con un clic.
Conclusione
La scalabilità orizzontale dei database PostgreSQL può richiedere molto tempo. Dobbiamo sapere di cosa abbiamo bisogno per ridimensionare e qual è il modo migliore per farlo. In definitiva, la gestione e il ridimensionamento manuale dei cluster diventa piuttosto oneroso oltre un certo punto, quindi la maggior parte si rivolge a strumenti come il nostro.
Se scegli il percorso manuale, controlla quando considerare l'aggiunta di un nodo aggiuntivo al tuo cluster. Vuoi evitare il fastidio? Valuta ClusterControl gratuitamente per 30 giorni per vedere come le sue funzionalità rendono semplice ed efficiente la gestione dell'open source su larga scala.
Comunque tu voglia gestire e ridimensionare i tuoi database, seguici su Twitter o LinkedIn o iscriviti alla nostra newsletter per ricevere le ultime notizie e le migliori pratiche quando gestisci un'infrastruttura di database basata su open source, e ci vediamo presto!