Se il tuo sistema si basa su PostgreSQL e stai cercando soluzioni di clustering per l'alta disponibilità, vogliamo farti sapere in anticipo che è un compito complesso ma non impossibile da realizzare.
Considerando i tuoi requisiti di tolleranza ai guasti, ecco alcune soluzioni di clustering ad alta disponibilità tra cui scegliere che possono aiutarti.
PostgreSQL non supporta nativamente alcuna soluzione di clustering multi-master come MySQL o Oracle. Tuttavia, molti prodotti commerciali e comunitari offrono questa implementazione, inclusa la replica e il bilanciamento del carico per PostgreSQL.
Per iniziare, esaminiamo alcuni concetti di base:
Cos'è l'alta disponibilità?
L'elevata disponibilità si riferisce alla quantità di tempo in cui un servizio è disponibile ed è solitamente definita dal livello di prestazioni concordato dall'azienda.
La ridondanza è la base per l'elevata disponibilità; in caso di incidente, puoi continuare a utilizzare e ad accedere ai sistemi senza problemi.
Recupero continuo
Quando si verifica un incidente, se devi ripristinare un backup e quindi applicare i registri WAL (Write-Ahead Logging), il tempo di ripristino sarebbe molto elevato e non sarebbe altamente disponibile.
Tuttavia, se hai i backup e i log archiviati in un server di emergenza, puoi applicare i log non appena arrivano. Se i log vengono inviati e applicati ogni minuto, la base di emergenza si troverebbe in un ripristino continuo e avrebbe uno stato obsoleto per la produzione di al massimo un minuto.
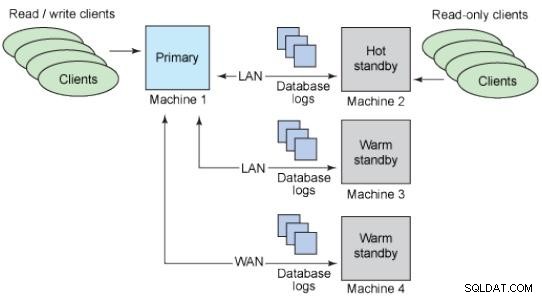
Database in standby
L'idea di un database in standby è conservare una copia di un database di produzione che ha sempre gli stessi dati ed è pronto per essere utilizzato in caso di incidente.
Ci sono diversi modi per classificare un database in standby.
Per la natura della replica:
-
Standby fisici:i blocchi del disco vengono copiati.
-
Standby logici:streaming delle modifiche ai dati.
Per la sincronicità delle transazioni:
-
Asincrono:esiste la possibilità di perdita di dati.
-
Sincrono:non c'è possibilità di perdita di dati; I commit nel master aspettano la risposta dello standby.
In base all'utilizzo:
-
Standby caldi:non supportano le connessioni.
-
Hot standbys:supporta connessioni di sola lettura.
Cluster
Un cluster è un gruppo di host che lavorano insieme e sono visti come uno. Ciò fornisce un modo per ottenere la scalabilità orizzontale e la possibilità di elaborare più lavoro aggiungendo server.
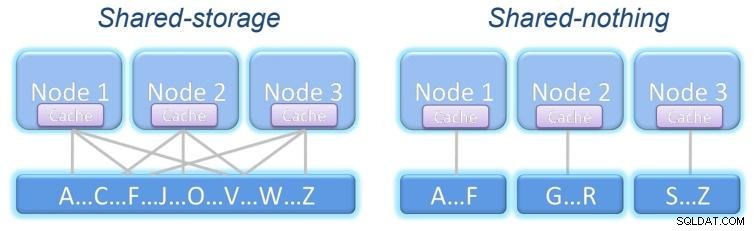
Può resistere al guasto di un nodo e continuare a lavorare in modo trasparente. A seconda di cosa è condiviso, ci sono due modelli di cluster:
-
Archiviazione condivisa:tutti i nodi accedono alla stessa memoria con le stesse informazioni.
-
Niente condiviso:ogni nodo ha la propria memoria, che può avere o meno le stesse informazioni dell'altro nodi, a seconda della struttura del nostro sistema.
Ora esaminiamo alcune delle opzioni di clustering che abbiamo in PostgreSQL.
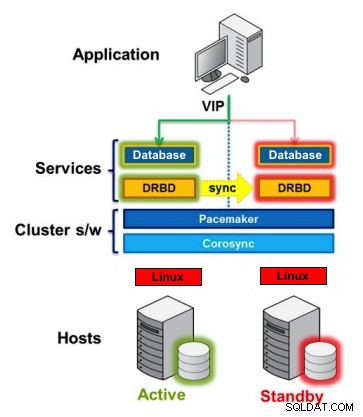
Dispositivo a blocchi replicato distribuito
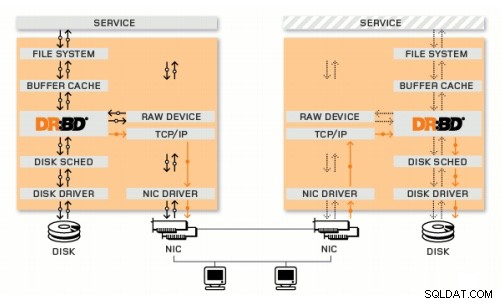
DRBD è un modulo del kernel Linux che implementa la replica sincrona a blocchi utilizzando la rete. In realtà non implementa un cluster e non gestisce il failover o il monitoraggio. Hai bisogno di un software complementare per questo, ad esempio Corosync + Pacemaker + DRBD.
Esempio:
-
Corosync:gestisce i messaggi tra host.
-
Pacemaker:avvia e interrompe i servizi, assicurandosi che vengano eseguiti solo su un host.
-
DRBD:sincronizza i dati a livello di dispositivi a blocchi.
Controllo cluster
ClusterControl è un software di gestione e automazione senza agenti per cluster di database. Aiuta a distribuire, monitorare, gestire e ridimensionare il server/cluster di database direttamente dalla sua interfaccia utente. Può gestire la maggior parte delle attività di amministrazione richieste per mantenere i server di database oi cluster.
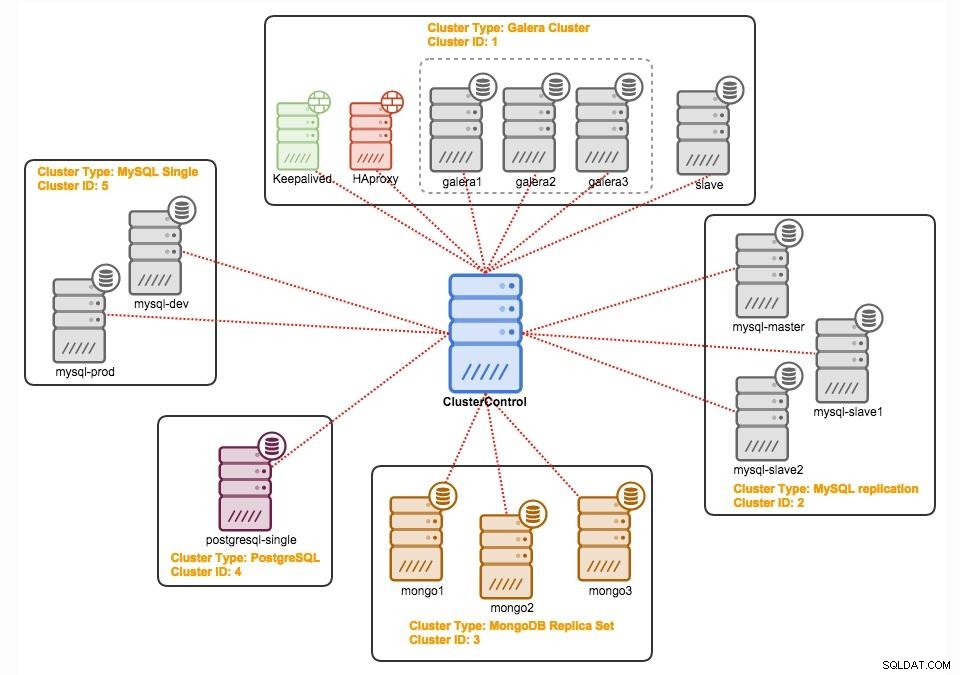
Con ClusterControl puoi:
-
Distribuisci database standalone, replicati o raggruppati nello stack tecnologico di tua scelta.
-
Automatizzazione di failover, ripristino e attività quotidiane in modo uniforme su database poliglotti e infrastrutture dinamiche.
-
Crea backup completi o incrementali manualmente o pianificali.
-
Esegui un monitoraggio unificato e completo in tempo reale dell'intero database e dell'infrastruttura del server.
-
Aggiungi o rimuovi facilmente un nodo con una sola azione.
-
Clona il tuo cluster su un altro data center/fornitore cloud
Se si verifica un incidente su PostgreSQL, il tuo nodo Standby può essere promosso automaticamente a Primario.
Si tratta di uno strumento completo che offre la gestione e l'automazione complete del ciclo di vita attraverso un'unica lastra di vetro. ClusterControl fornisce anche una versione di prova gratuita di 30 giorni in modo da poterla valutare senza alcun vincolo.
Rubyrep
Rubyrep è una soluzione che fornisce replica asincrona, multimaster, multipiattaforma (implementata in Ruby o JRuby) e multi-DBMS (MySQL o PostgreSQL).
Si basa su trigger e non supporta DDL, utenti o sovvenzioni. La semplicità di utilizzo e amministrazione è il suo obiettivo primario.
Alcune funzionalità includono:
-
Configurazione semplice
-
Installazione semplice
-
Indipendente dalla piattaforma, dal design del tavolo indipendente.
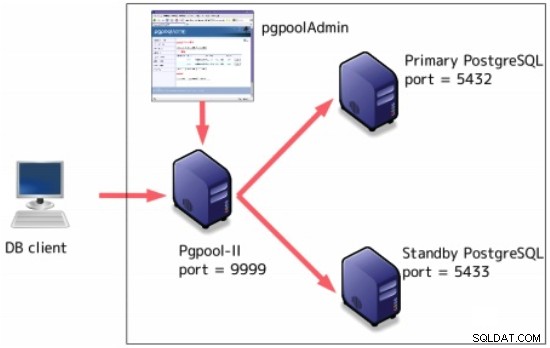
Pgpool-II
Pgpool-II è un middleware che funziona tra i server PostgreSQL e un client di database PostgreSQL.
Alcune funzionalità includono:
-
Pool di connessione
-
Replica
-
Bilanciamento del carico
-
Failover automatico
-
Query parallele
Può essere configurato in aggiunta alla replica in streaming:
Bucardo
Bucardo offre la replica master-slave a cascata asincrona, basata su righe, utilizzando trigger e accodamento nel database, e la replica master-master asincrona, basata su righe, utilizzando trigger e risoluzione dei conflitti personalizzata.
Bucardo richiede un database dedicato e funziona come un demone Perl che comunica con questo database e tutti gli altri database coinvolti nella replica. Può funzionare come multi-master o multi-slave.
La replica master-slave coinvolge una o più sorgenti che vanno a uno o più target. L'origine deve essere PostgreSQL, ma le destinazioni possono essere PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite o MongoDB.
Alcune funzionalità includono:
-
Bilanciamento del carico
-
Gli schiavi non sono vincolati e possono essere scritti
-
Replica parziale
-
Replica su richiesta (le modifiche possono essere inviate automaticamente o quando lo si desidera)
-
Gli slave possono essere "preriscaldati" per una rapida configurazione
Inconvenienti:
-
Impossibile gestire DDL
-
Impossibile gestire oggetti di grandi dimensioni
-
Impossibile replicare in modo incrementale tabelle senza una chiave univoca
-
Non funzionerà su versioni precedenti a Postgres 8
Postgres-XC
Postgres-XC è un progetto open source per fornire una soluzione cluster PostgreSQL scalabile in scrittura, sincrona, simmetrica e trasparente. È una raccolta di componenti di database strettamente accoppiati che possono essere installati in più di un hardware o macchina virtuale.
Scalabile in scrittura significa che Postgres-XC può essere configurato con tutti i server di database che vuoi e gestire molte più scritture (aggiornamento delle istruzioni SQL) rispetto a quanto può fare un singolo server di database.
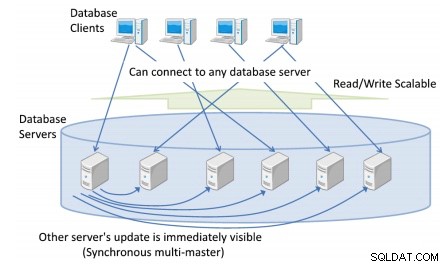
Puoi avere più di un server di database a cui si connettono i client, fornendo un'unica vista coerente a livello di cluster del database.
Qualsiasi aggiornamento del database da qualsiasi server di database è immediatamente visibile a qualsiasi altra transazione in esecuzione su master diversi.
Trasparente significa che non devi preoccuparti di come i tuoi dati vengono archiviati internamente in più di un server di database.
Puoi configurare Postgres-XC per l'esecuzione su più server. I tuoi dati vengono archiviati in modo distribuito, partizionato o replicato, come da te scelto per ogni tabella. Quando esegui query, Postgres-XC determina dove sono archiviati i dati di destinazione ed invia le query corrispondenti ai server contenenti i dati di destinazione.
Città
Citus è un sostituto drop-in di PostgreSQL con funzionalità integrate di alta disponibilità come lo sharding automatico e la replica. Citus esegue lo shard del database e replica più copie di ogni shard nel cluster di nodi delle materie prime. Se un nodo nel cluster diventa non disponibile, Citus reindirizza in modo trasparente eventuali scritture o query a uno degli altri nodi che ospitano una copia dello shard interessato.
Alcune funzionalità includono:
-
Sharding logico automatico
-
Replica integrata
-
Replica basata su data center per il ripristino di emergenza
-
Tolleranza agli errori mid-query con bilanciamento del carico avanzato
Puoi aumentare il tempo di attività delle tue applicazioni in tempo reale basate su PostgreSQL e ridurre al minimo l'impatto dei guasti hardware sulle prestazioni. Puoi raggiungere questo obiettivo con gli strumenti di alta disponibilità integrati che riducono al minimo gli interventi manuali costosi e soggetti a errori.
PostgresXL
PostgresXL è una soluzione di clustering multi-master condivisa che può distribuire in modo trasparente una tabella su un insieme di nodi ed eseguire query in parallelo con quei nodi. Ha un componente aggiuntivo chiamato Global Transaction Manager (GTM) per fornire una visione coerente a livello globale del cluster.
PostgresXL è un cluster di database SQL open source scalabile orizzontalmente, abbastanza flessibile da gestire carichi di lavoro di database variabili:
-
Carichi di lavoro ad alta intensità di scrittura OLTP
-
Business Intelligence che richiede il parallelismo MPP
-
Datastore operativo
-
Negozio valori-chiave
-
GIS Geospatial
-
Ambienti con carichi di lavoro misti
-
Ambienti ospitati da provider multi-tenant

Componenti:
-
Global Transaction Monitor (GTM):il Global Transaction Monitor garantisce la coerenza delle transazioni a livello di cluster.
-
Coordinatore:il Coordinatore gestisce le sessioni utente e interagisce con GTM e i nodi di dati.
-
Nodo di dati:il nodo di dati è dove vengono archiviati i dati effettivi.
Conclusione
Ci sono molti altri prodotti disponibili per implementare il tuo ambiente ad alta disponibilità per PostgreSQL, ma devi stare attento a:
-
Nuovi prodotti, non sufficientemente testati
-
Progetti fuori produzione
-
Limitazioni
-
Costi di licenza
-
Implementazioni molto complesse
-
Soluzioni non sicure
Quando selezioni la soluzione che utilizzerai, tieni conto anche della tua infrastruttura. Se si dispone di un solo server delle applicazioni, indipendentemente da quanto è stata configurata l'elevata disponibilità dei database, se il server delle applicazioni si guasta, non si è accessibili. Devi analizzare bene i singoli punti di guasto nell'infrastruttura e cercare di risolverli.
Tenendo conto di questi punti, puoi trovare una soluzione cluster ad alta disponibilità che si adatta alle tue esigenze e requisiti, senza problemi. Se stai cercando risorse HA aggiuntive per il tuo database PG, dai un'occhiata a questo post sulla distribuzione di PostgreSQL per l'alta disponibilità.
Per rimanere aggiornato sulle soluzioni di gestione dei database e sulle best practice, seguici su Twitter e LinkedIn e iscriviti alla nostra newsletter.