Nel mio articolo precedente, abbiamo iniziato a descrivere le basi del comando EXPLAIN e abbiamo analizzato cosa accade in PostgreSQL durante l'esecuzione di una query.
Continuerò a scrivere sulle basi di EXPLAIN in PostgreSQL. Le informazioni sono una breve rassegna di Understanding EXPLAIN di Guillaume Lelarge. Consiglio vivamente di leggere l'originale poiché alcune informazioni sono perse.
Cache
Cosa succede a livello fisico durante l'esecuzione della nostra query? Scopriamolo. Ho distribuito il mio server su Ubuntu 13.10 e ho utilizzato cache del disco a livello di sistema operativo.
Arresto PostgreSQL, confermo le modifiche al file system, svuoto la cache ed eseguo PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Quando la cache viene svuotata, esegui la query con l'opzione BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Leggiamo la tabella per blocchi. La cache è vuota. Abbiamo dovuto accedere a 8334 blocchi per leggere l'intera tabella dal disco.
Buffer:la lettura condivisa è il numero di blocchi che PostgreSQL legge dal disco.
Esegui la query precedente
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffer:l'hit condiviso è il numero di blocchi recuperati dalla cache di PostgreSQL.
Con ogni query, PostgreSQL preleva sempre più dati dalla cache, riempiendo così la propria cache.
Le operazioni di lettura della cache sono più veloci delle operazioni di lettura del disco. Puoi vedere questa tendenza monitorando il valore di runtime totale.
La dimensione della memoria cache è definita dalla costante shared_buffers nel file postgresql.conf.
DOVE
Aggiungi la condizione alla query
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Non ci sono indici sulla tabella. Durante l'esecuzione della query, ogni record della tabella viene scansionato in sequenza (Seq Scan) e confrontato con la condizione c1> 500. Se la condizione è soddisfatta, il record viene aggiunto al risultato. In caso contrario, viene scartato. Il filtro indica questo comportamento, così come il valore del costo aumenta.
Il numero stimato di righe diminuisce.
L'articolo originale spiega perché il costo assume questo valore e come viene calcolato il numero stimato di righe.
È ora di creare indici.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Il numero stimato di righe è cambiato. E l'indice?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Vengono filtrate solo 510 righe di oltre 1 milione. PostgreSQL ha dovuto leggere più del 99,9% della tabella.
Forzeremo l'utilizzo dell'indice disabilitando Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

In Index Scan e Index Cond, viene utilizzato l'indice foo_c1_idx invece di Filter.
Quando si seleziona l'intera tabella, l'utilizzo dell'indice aumenterà il costo e il tempo per eseguire la query.
Abilita scansione sequenziale:
SET enable_seqscan TO on;
Modifica la query:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
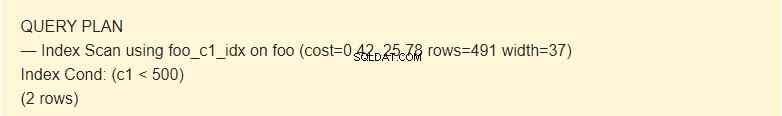
Qui il pianificatore utilizza l'indice.
Ora complichiamo il valore aggiungendo il campo di testo.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Come puoi vedere, l'indice foo_c1_idx viene utilizzato per c1 <500. Per eseguire c2 ~~ 'abcd%'::text, usa il filtro.
Va notato che il formato POSIX dell'operatore LIKE viene utilizzato nell'output dei risultati. Se nella condizione è presente solo il campo di testo:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan viene applicato.
Costruisci l'indice per c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

L'indice non viene applicato perché il mio database per i campi di prova utilizza la codifica UTF-8.
Quando si costruisce l'indice, è necessario specificare la classe dell'operatore text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Grande! Ha funzionato!
Bitmap Index Scan utilizza l'indice foo_c2_idx1 per determinare i record di cui abbiamo bisogno. Quindi, PostgreSQL passa alla tabella (Bitmap Heap Scan) per assicurarsi che questi record esistano effettivamente. Questo comportamento si riferisce al controllo delle versioni di PostgreSQL.
Se selezioni solo il campo, su cui è costruito l'indice, invece dell'intera riga:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

La scansione dell'indice verrà eseguita più velocemente rispetto alla scansione dell'indice poiché non è necessario leggere la riga della tabella:larghezza=4.
Conclusione
- Seq Scan legge l'intera tabella
- Scansione indice utilizza l'indice per le istruzioni WHERE e legge la tabella quando si selezionano le righe
- La scansione dell'indice bitmap utilizza la scansione dell'indice e il controllo della selezione tramite la tabella. Efficace per un gran numero di righe.
- Index Only Scan è il blocco più veloce, che legge solo l'indice.
Ulteriori letture:
Ottimizzazione delle query in PostgreSQL. SPIEGAZIONE Nozioni di base – Parte 3