Continuo una serie di articoli sulle basi di EXPLAIN in PostgreSQL, che è una breve recensione di Understanding EXPLAIN di Guillaume Lelarge.
Per comprendere meglio il problema, consiglio vivamente di rivedere l'originale "Understanding EXPLAIN" di Guillaume Lelarge e leggi il mio primo e il secondo articolo.
ORDINA PER
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

All'inizio, esegui una scansione sequenziale (Seq Scan) della tabella foo e quindi esegui l'ordinamento (Sort). Il segno -> del comando EXPLAIN indica la gerarchia dei passi (nodo). Prima viene eseguito il passaggio, maggiore sarà il rientro.
La chiave di ordinamento è una condizione di ordinamento.
Metodo di ordinamento:unione esterna Disco un file temporaneo sul disco con una capacità di 4592 kB viene utilizzato durante l'ordinamento.
Verifica con l'opzione BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
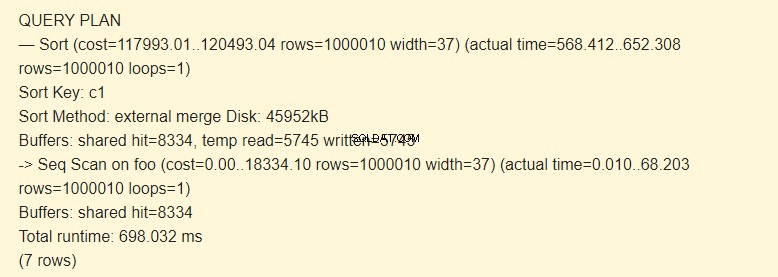
In effetti, la riga temp read=5745 scritta=5745 significa che 45960 Kb (5745 blocchi da 8 Kb ciascuno) sono stati memorizzati e letti nel file temporaneo. Le operazioni con 8334 blocchi sono state eseguite nella cache.
Le operazioni con il file system sono più lente delle operazioni nella RAM.
Proviamo ad aumentare la capacità di memoria di work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Metodo di ordinamento:quicksort Memoria:102702kB – l'intero ordinamento è stato eseguito nella RAM.
L'indice è il seguente:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

È rimasta solo la scansione dell'indice, che ha influito in modo significativo sulla velocità della query.
LIMITE
Elimina l'indice creato in precedenza:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
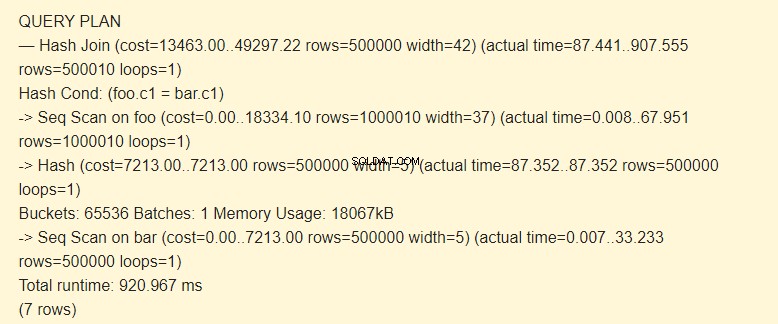
Come previsto, vengono utilizzati Seq Scan e Filter.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan legge le righe della tabella e le confronta (Filtro) con la condizione. Non appena ci sono 10 record che soddisfano la condizione, la scansione terminerà. Nel nostro caso, per ottenere 10 righe di risultati, abbiamo dovuto leggere solo 3063 record anziché l'intera tabella. 3053 righe di questo numero sono state rifiutate (righe rimosse dal filtro).
Lo stesso accade con Scansione indice.
ISCRIVITI
Crea una nuova tabella e genera statistiche per essa:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
La query per due tabelle è la seguente:
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
In primo luogo, la scansione sequenziale (Seq Scan) legge la tabella a barre. Viene calcolato un hash (Hash) per ogni riga.
Quindi, esegue la scansione della tabella foo e, per ogni riga, viene calcolato un hash che viene confrontato (Hash Join) con l'hash della tabella della barra dalla condizione Hash Cond. Se corrispondono, viene emessa una stringa risultante.
18067kB di memoria vengono utilizzati per memorizzare gli hash per la barra.
Aggiungi l'indice:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

L'hash non è più utilizzato. Unisci Join e Index Scan sugli indici di entrambe le tabelle migliorano notevolmente le prestazioni.
UNISCI A SINISTRA:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
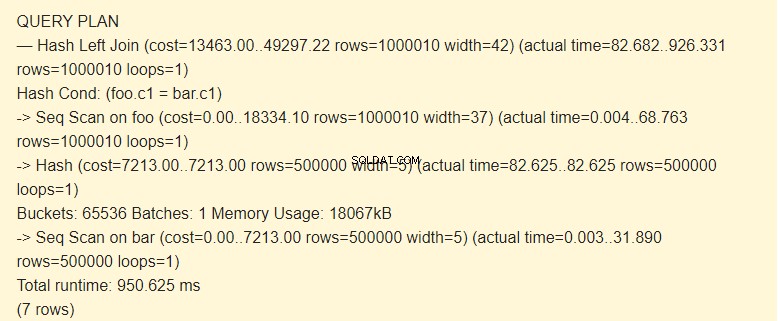
Scansione sequenziale?
Vediamo che risultato avremo se disabilitiamo Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Secondo lo scheduler, l'utilizzo degli indici è più costoso dell'utilizzo degli hash. Ciò è possibile con una quantità sufficientemente grande di memoria allocata. Ti ricordi che abbiamo aumentato work_mem?
Tuttavia, se non si dispone di memoria sufficiente, lo scheduler si comporterà in modo diverso:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Se disabilitiamo la scansione dell'indice, quale risultato verrà visualizzato EXPLAIN?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
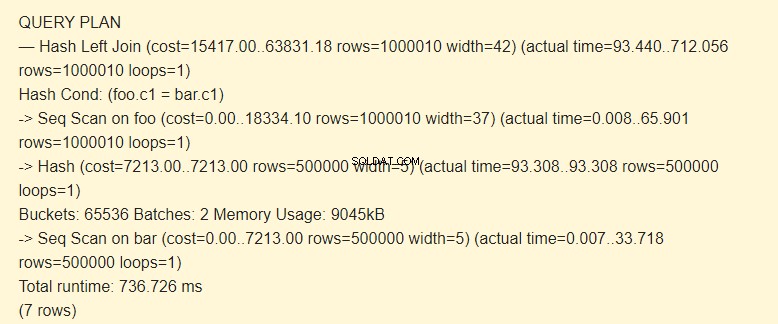
Lotti:2 ha aumentato il costo. L'intero hash non rientrava nella memoria; abbiamo dovuto dividerlo in due pacchetti da 9045kB.
Grazie per aver letto i miei articoli! Spero siano stati utili. In caso di commenti o feedback, non esitare a farmelo sapere.