Perché ci vuole così tanto tempo per eseguire una query? Perché non ci sono indici? È probabile che tu abbia sentito parlare di EXPLAIN in PostgreSQL. Tuttavia, ci sono ancora molte persone che non hanno idea di come usarlo. Spero che questo articolo possa aiutare gli utenti ad affrontare questo fantastico strumento.
Questo articolo è la revisione dell'autore di Understanding EXPLAIN di Guillaume Lelarge. Dal momento che ho perso alcune informazioni, ti consiglio vivamente di familiarizzare con l'originale.
Il diavolo non è nero come è dipinto
È importante comprendere la logica del kernel PostgreSQL per ottimizzare le query. Proverò a spiegare. Non è davvero così complicato.
EXPLAIN mostra le informazioni necessarie che spiegano cosa fa il kernel per ogni specifica query.
Diamo un'occhiata a cosa mostra il comando EXPLAIN e capiamo cosa succede esattamente all'interno di PostgreSQL. Puoi applicare queste informazioni a PostgreSQL 9.2 e versioni successive.
I nostri compiti:
- Scopri come leggere e comprendere l'output del comando EXPLAIN
- Capire cosa succede in PostgreSQL quando viene eseguita una query
Primi passi
Ci eserciteremo su una tabella di prova con un milione di righe.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Prova a leggere i dati
EXPLAIN SELECT * FROM foo;
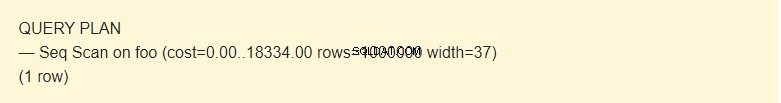
È possibile leggere i dati da una tabella in diversi modi. Nel nostro caso, EXPLAIN notifica che viene utilizzata una Seq Scan, una lettura sequenziale, blocco per blocco, di dati di una tabella Foo.
Qual è il costo ?
Ebbene, non è un tempo, ma un concetto pensato per stimare il costo di un'operazione. Il primo valore 0,00 è il costo per ottenere la prima riga. Il secondo valore 18334.00 è il costo per ottenere tutte le righe.
Righe sono il numero approssimativo di righe restituite quando viene eseguita un'operazione Seq Scan. Lo scheduler restituisce questo valore. Nel mio caso, corrisponde al numero effettivo di righe nella tabella.
Larghezza è una dimensione media di una riga in byte.
Proviamo ad aggiungere 10 righe.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

Il valore delle righe non è stato modificato. La statistica della tabella è vecchia. Per aggiornare le statistiche, chiama il comando ANALIZZA.
Ora, righe visualizzare il numero corretto di righe.
Cosa succede durante l'esecuzione di ANALIZZA?
- A caso, un numero di righe viene selezionato e letto dalla tabella.
- Vengono raccolte le statistiche dei valori per ogni colonna.
Il numero di righe ANALYZE lette dipende dal parametro default_statistics_target.
Dati effettivi
Tutto ciò che abbiamo visto sopra nell'output del comando EXPLAIN è ciò che il pianificatore si aspetta di ottenere. Proviamo a confrontarli con i risultati sui dati effettivi. Per fare ciò, usa EXPLAIN (ANALYZE).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Tale query verrà effettivamente eseguita. Quindi, se esegui EXPLAIN (ANALYZE) per le istruzioni INSERT, DELETE o UPDATE, i tuoi dati verranno modificati. Stai attento! In questi casi, utilizzare il comando ROLLBACK.
Il comando visualizza i seguenti parametri aggiuntivi:
- Il tempo effettivo è il tempo effettivo in millisecondi spesi per ottenere rispettivamente la prima riga e tutte le righe.
- righe è il numero effettivo di righe ricevute con Seq Scan.
- loops è il numero di volte in cui è stata eseguita l'operazione Seq Scan.
- Il tempo di esecuzione totale è il tempo totale di esecuzione della query.
Ulteriori letture:
Ottimizzazione delle query in PostgreSQL. SPIEGAZIONE Nozioni di base – Parte 2
Ottimizzazione delle query in PostgreSQL. SPIEGAZIONE Nozioni di base – Parte 3