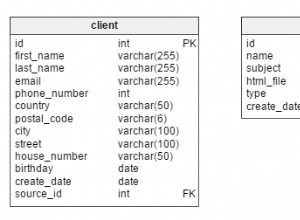
Le ricerche full-text in linguaggio naturale di MySQL mirano a confrontare le query di ricerca con un corpus per trovare le corrispondenze più rilevanti. Quindi supponiamo di avere un articolo che contiene "I love pie" e di avere i documenti d1, d2, d3 (il database nel tuo caso). I documenti 1 e 2 riguardano rispettivamente lo sport e la religione e il documento 3 riguarda il cibo. La tua domanda,
Restituirà d3, e poi d2, d1 (ordine casuale di d2,d1 a seconda di quale è più uguale all'articolo) perché d3 corrisponde meglio all'articolo.
L'algoritmo sottostante utilizzato da MYSQL è probabilmente l'algoritmo tf-idf, dove tf sta per frequenza del termine e idf per frequenza inversa del documento. tf è come si dice, solo il numero di volte in cui una parola w in un articolo ricorre in un documento. idf si basa su quanti documenti si trova la parola. Quindi le parole che ricorrono in molti documenti non contribuiscono a decidere il documento più rappresentativo. Il prodotto di tf*idf produce un punteggio, maggiore è la migliore rappresentazione della parola in un documento. Quindi 'torta' si verificherà solo nel documento d3 e avrà quindi un tf alto e un idf alto (poiché è l'inverso). Considerando che 'the' avrà un tf alto ma un idf basso che eliminerà il tf e darà un punteggio basso.
La modalità MYSQL Natural Language include anche una serie di stopword (the, a, some etc) e rimuove le parole che sono meno di 4 lettere. Che può essere visto nel link che hai fornito.