Amazon Aurora Serverless fornisce un database relazionale on-demand, scalabile automaticamente e ad alta disponibilità che ti addebita solo quando è in uso. Fornisce un'opzione relativamente semplice ed economica per carichi di lavoro poco frequenti, intermittenti o imprevedibili. Ciò che lo rende possibile è che si avvia automaticamente, ridimensiona la capacità di calcolo in base all'utilizzo dell'applicazione e quindi si spegne quando non è più necessaria.
Il diagramma seguente mostra l'architettura di alto livello Aurora Serverless.
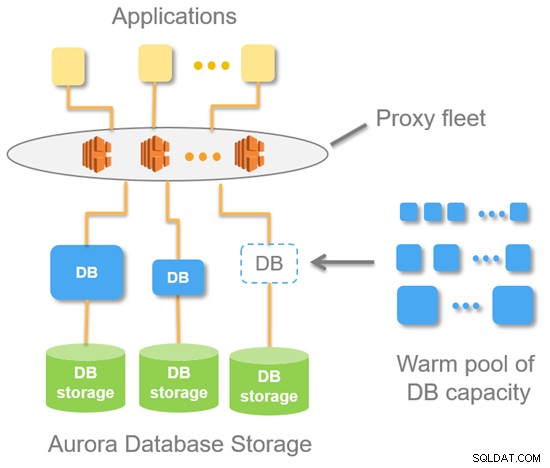
Con Aurora Serverless, ottieni un endpoint (invece di due endpoint per il DB con provisioning Aurora standard). Questo è fondamentalmente un record DNS costituito da una flotta di proxy che si trova sopra l'istanza del database. Da un server MySQL significa che le connessioni provengono sempre dal parco proxy.
Ridimensionamento automatico senza server di Aurora
Aurora Serverless è attualmente disponibile solo per MySQL 5.6. Fondamentalmente devi impostare l'unità di capacità minima e massima per il cluster di database. Ogni unità di capacità equivale a una specifica configurazione di calcolo e memoria. Aurora Serverless riduce le risorse per il cluster di database quando il suo carico di lavoro è al di sotto di queste soglie. Aurora Serverless può ridurre la capacità al minimo o aumentare la capacità fino all'unità di capacità massima.
Il cluster aumenterà automaticamente la scalabilità se viene soddisfatta una delle seguenti condizioni:
- L'utilizzo della CPU è superiore al 70% OPPURE
- Più del 90% delle connessioni viene utilizzato
Il cluster verrà ridimensionato automaticamente se vengono soddisfatte entrambe le seguenti condizioni:
- L'utilizzo della CPU scende al di sotto del 30% E
- Meno del 40% delle connessioni viene utilizzato.
Alcune delle cose importanti da sapere sul flusso di ridimensionamento automatico di Aurora:
- Aumenta la scalabilità solo quando rileva problemi di prestazioni che possono essere risolti aumentando la scalabilità.
- Dopo il ridimensionamento, il periodo di attesa per il ridimensionamento è di 15 minuti.
- Dopo il ridimensionamento, il periodo di attesa per il successivo ridimensionamento è di 310 secondi.
- Ridimensiona fino a capacità zero quando non ci sono connessioni per un periodo di 5 minuti.
Per impostazione predefinita, Aurora Serverless esegue il ridimensionamento automatico senza interruzioni, senza interrompere le connessioni attive del database al server. È in grado di determinare un punto di ridimensionamento (un momento in cui il database può avviare in sicurezza l'operazione di ridimensionamento). Nelle seguenti condizioni, tuttavia, Aurora Serverless potrebbe non essere in grado di trovare un punto di scalabilità:
- Sono in corso query o transazioni di lunga durata.
- Sono in uso tabelle temporanee o blocchi di tabella.
Se si verifica uno dei casi precedenti, Aurora Serverless continua a cercare di trovare un punto di ridimensionamento in modo da poter avviare l'operazione di ridimensionamento (a meno che "Forza ridimensionamento" non sia abilitato). Lo fa finché determina che il cluster di database deve essere ridimensionato.
Osservazione del comportamento di ridimensionamento automatico di Aurora
Si noti che in Aurora Serverless è possibile modificare solo un numero limitato di parametri e max_connections non è uno di questi. Per tutti gli altri parametri di configurazione, i cluster Aurora MySQL Serverless utilizzano i valori predefiniti. Per max_connections, è controllato dinamicamente da Aurora Serverless utilizzando la seguente formula:
max_connections =GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})
Dove, log è log2 (log base-2) e "DBInstanceClassMemory" è il numero di byte di memoria allocati alla classe dell'istanza database associata all'istanza database corrente, meno la memoria utilizzata dai processi Amazon RDS che gestiscono l'istanza. È piuttosto difficile predeterminare il valore che Aurora utilizzerà, quindi è bene fare alcuni test per capire come questo valore viene ridimensionato di conseguenza.
Ecco il nostro riepilogo della distribuzione di Aurora Serverless per questo test:
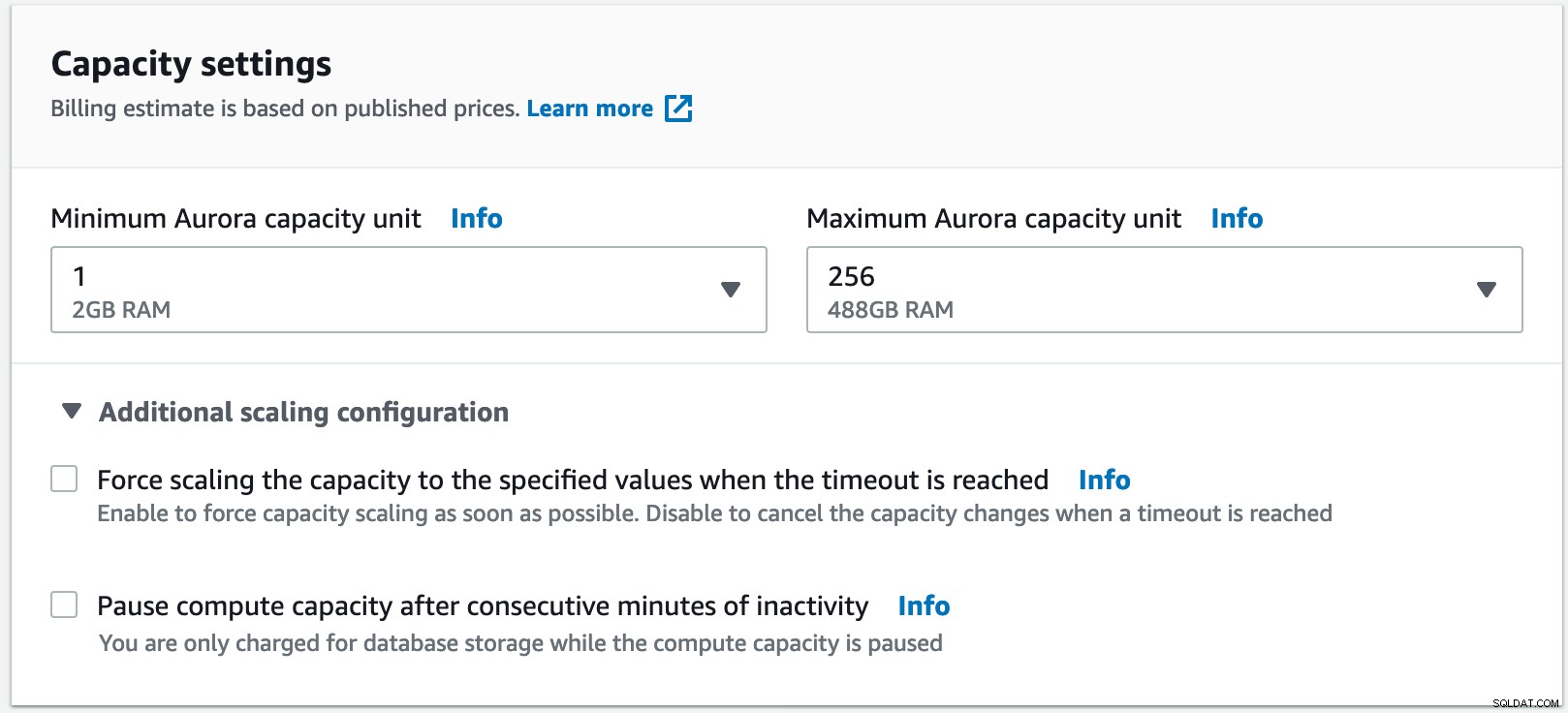
Per questo esempio ho selezionato un minimo di 1 unità di capacità Aurora, che equivale a 2 GB di RAM fino al massimo di 256 unità di capacità con 488 GB di RAM.
I test sono stati eseguiti utilizzando sysbench, inviando semplicemente più thread fino a raggiungere il limite delle connessioni al database MySQL. Il nostro primo tentativo di inviare 128 connessioni al database simultanee contemporaneamente è andato in errore:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=128 \
--delete_inserts=5 \
--time=360 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runIl comando precedente ha restituito immediatamente l'errore 'Troppe connessioni':
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsGuardando le impostazioni di max_connection, abbiamo ottenuto quanto segue:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
| ip-10-2-56-105 | 90 |
+----------------+-------------------+Si scopre che il valore iniziale di max_connections per la nostra istanza Aurora con una capacità di un DB (2 GB di RAM) è 90. Questo è in realtà molto inferiore al nostro valore previsto se calcolato utilizzando la formula fornita per stimare il valore max_connections:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+Ciò significa semplicemente che DBInstanceClassMemory non è uguale alla memoria effettiva per l'istanza Aurora. Deve essere molto più basso. Secondo questo thread di discussione, il valore della variabile viene regolato per tenere conto della memoria già in uso per i servizi del sistema operativo e il demone di gestione RDS.
Tuttavia, la modifica del valore max_connections predefinito con qualcosa di più alto non ci aiuterà poiché questo valore è controllato dinamicamente dal cluster Aurora Serverless. Pertanto, abbiamo dovuto ridurre il valore dei thread iniziali di sysbench a 84 perché i thread interni di Aurora hanno già riservato da 4 a 5 connessioni tramite 'rdsadmin'@'localhost'. Inoltre, abbiamo anche bisogno di una connessione aggiuntiva per i nostri scopi di gestione e monitoraggio.
Quindi abbiamo invece eseguito il seguente comando (con --threads=84):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=84 \
--delete_inserts=5 \
--time=600 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runDopo che il test precedente è stato completato in 10 minuti (--time=600), abbiamo eseguito di nuovo lo stesso comando e in questo momento, alcune delle variabili e dello stato importanti sono cambiati come mostrato di seguito:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Nota che max_connections ora è raddoppiato fino a 180, con un nome host diverso e tempi di attività ridotti come se il server fosse appena iniziato. Dal punto di vista dell'applicazione, sembra che un'altra "istanza di database più grande" abbia preso il controllo dell'endpoint e configurato con una variabile max_connections diversa. Guardando l'evento Aurora, è successo quanto segue:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Quindi, abbiamo attivato lo stesso comando sysbench, creando altre 84 connessioni all'endpoint del database. Dopo il completamento dello stress test generato, il server scala automaticamente fino a 4 DB di capacità, come mostrato di seguito:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+Puoi dirlo guardando il diverso hostname, max_connection e valore di uptime rispetto al precedente. Un'altra istanza più grande ha "assunto" il ruolo dell'istanza precedente, in cui la capacità del database era pari a 2. Il punto di ridimensionamento effettivo è quando il carico del server stava diminuendo e quasi raggiungendo il livello minimo. Nel nostro test, se mantenessimo la connessione piena e il carico del database costantemente elevato, il ridimensionamento automatico non avrebbe luogo.
Guardando entrambi gli screenshot qui sotto, possiamo dire che il ridimensionamento avviene solo quando il nostro Sysbench ha completato il suo stress test per 600 secondi perché questo è il punto più sicuro per eseguire il ridimensionamento automatico.
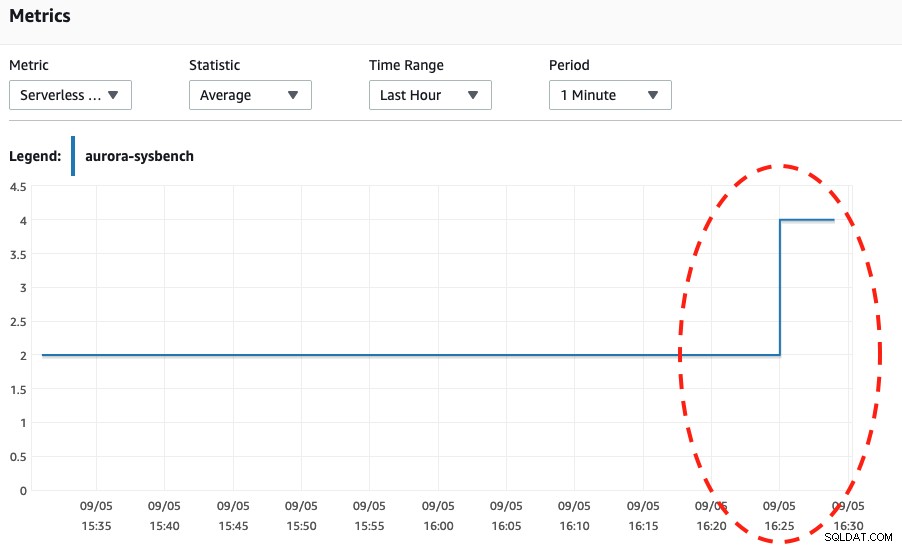 Capacità database serverless Utilizzo della CPU
Capacità database serverless Utilizzo della CPU 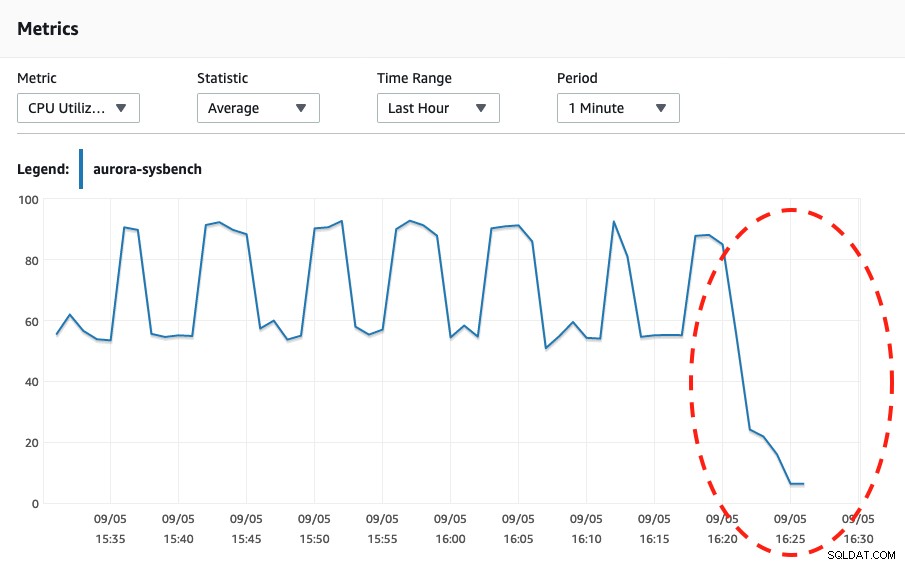 Utilizzo della CPU
Utilizzo della CPU Guardando gli eventi di Aurora, si sono verificati i seguenti eventi:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Infine, abbiamo generato molte più connessioni fino a quasi 270 e aspettiamo fino al termine, per entrare nella capacità di 8 DB:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
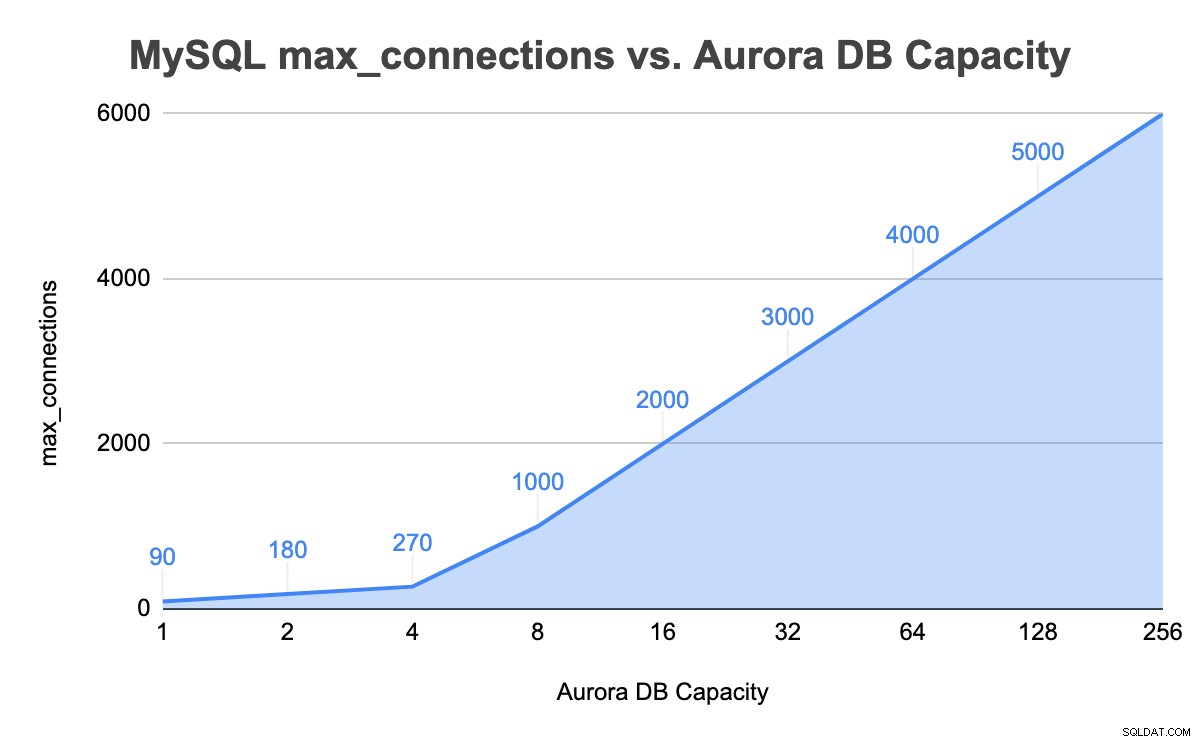
+---------------+-----------------+-------------------+--------+Nell'istanza di 8 unità di capacità, il valore MySQL max_connections è ora 1000. Abbiamo ripetuto passaggi simili massimizzando le connessioni al database e fino al limite di 256 unità di capacità. La tabella seguente riassume l'unità di capacità complessiva del DB rispetto al valore max_connections nei nostri test fino alla capacità massima del DB:
Ridimensionamento forzato
Come accennato in precedenza, Aurora Serverless eseguirà il ridimensionamento automatico solo quando è sicuro farlo. Tuttavia, l'utente ha la possibilità di forzare l'esecuzione immediata del ridimensionamento della capacità del database selezionando la casella di controllo Forza ridimensionamento sotto l'opzione "Configurazione ridimensionamento aggiuntivo":
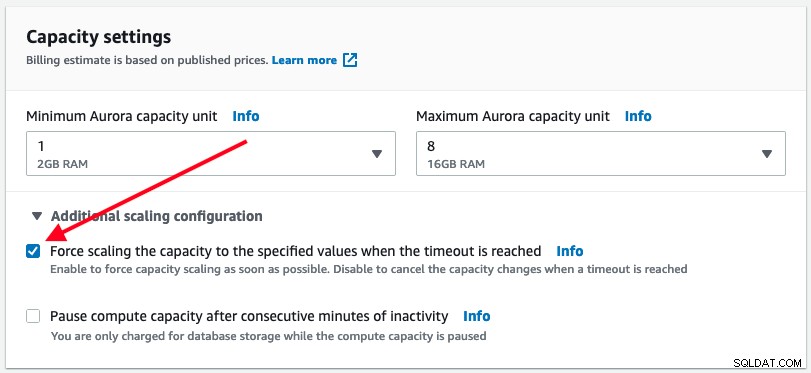
Quando il ridimensionamento forzato è abilitato, il ridimensionamento avviene non appena il timeout è raggiunto che è di 300 secondi. Questo comportamento può causare l'interruzione del database dall'applicazione in cui le connessioni attive al database potrebbero essere interrotte. Abbiamo osservato il seguente errore quando si verificava il ridimensionamento automatico forzato dopo il raggiungimento del timeout:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.Quanto sopra significa semplicemente che, invece di trovare il momento giusto per aumentare, Aurora Serverless forza la sostituzione dell'istanza immediatamente dopo che raggiunge il suo timeout, causando l'interruzione e il rollback delle transazioni. Riprovare la query interrotta per la seconda volta risolverà probabilmente il problema. Questa configurazione può essere utilizzata se la tua applicazione è resiliente alle interruzioni di connessione.
Riepilogo
La scalabilità automatica Amazon Aurora Serverless è una soluzione di scalabilità verticale, in cui un'istanza più potente prende il posto di un'istanza inferiore, utilizzando in modo efficiente la tecnologia di storage condivisa Aurora sottostante. Per impostazione predefinita, l'operazione di ridimensionamento automatico viene eseguita senza interruzioni, per cui Aurora trova un punto di ridimensionamento sicuro per eseguire il cambio di istanza. Si ha la possibilità di forzare il ridimensionamento automatico con il rischio che le connessioni al database attive vengano eliminate.