Al giorno d'oggi esistono numerosi fornitori di servizi cloud. Possono essere piccoli o grandi, locali o con data center sparsi in tutto il mondo. Molti di questi fornitori di servizi cloud offrono una sorta di soluzione di database relazionale gestito. I database supportati tendono ad essere MySQL o PostgreSQL o qualche altro tipo di database relazionale.
Quando si progetta qualsiasi tipo di infrastruttura di database è importante comprendere le esigenze della propria azienda e decidere quale tipo di disponibilità si dovrebbe ottenere.
In questo post del blog esamineremo le opzioni di alta disponibilità per le soluzioni basate su MySQL da uno dei più grandi fornitori di servizi cloud:Google Cloud Platform.
Distribuzione di un ambiente a disponibilità elevata utilizzando l'istanza SQL GCP
Per questo blog vogliamo un ambiente molto semplice:un database, con forse una o due repliche. Vogliamo essere in grado di eseguire facilmente il failover e ripristinare le operazioni il prima possibile in caso di errore del master. Utilizzeremo MySQL 5.7 come versione preferita e inizieremo con la procedura guidata di distribuzione dell'istanza:
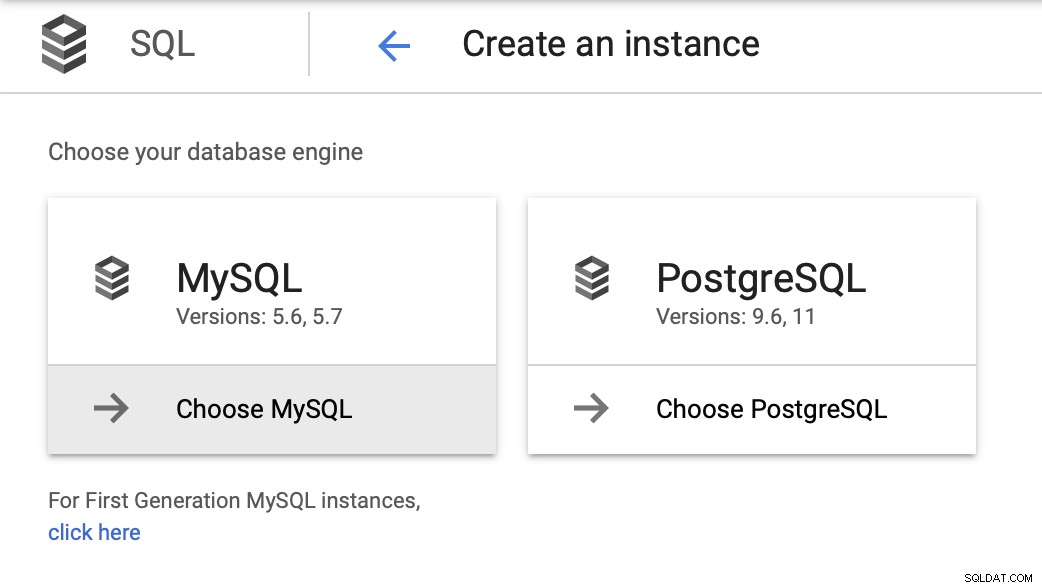
Dobbiamo quindi creare la password di root, impostare il nome dell'istanza e determinare dove dovrebbe essere posizionato:
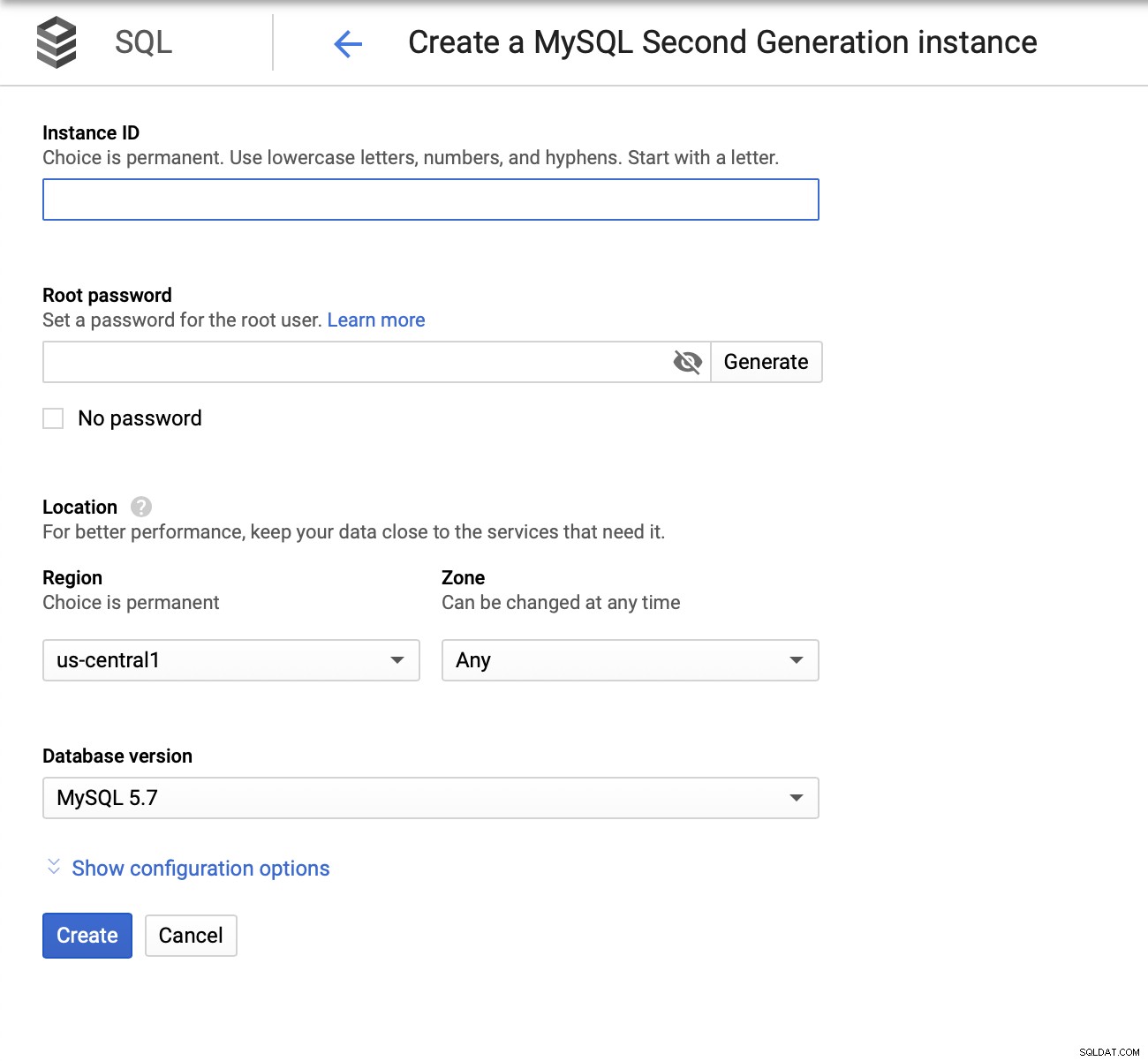
In seguito, esamineremo le opzioni di configurazione:
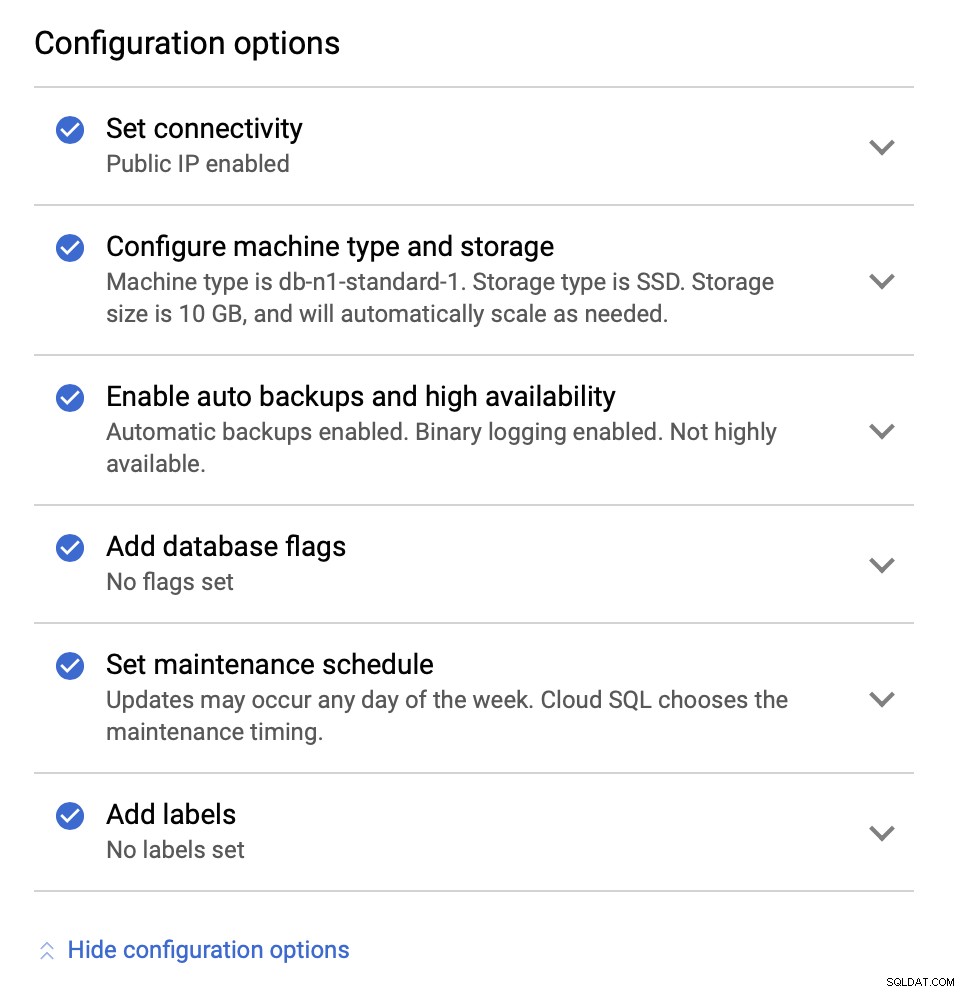
Possiamo apportare modifiche in termini di dimensione dell'istanza (andremo con db-n1-standard-4), archiviazione e programma di manutenzione. La cosa più importante per noi in questa configurazione sono le opzioni di disponibilità elevata:
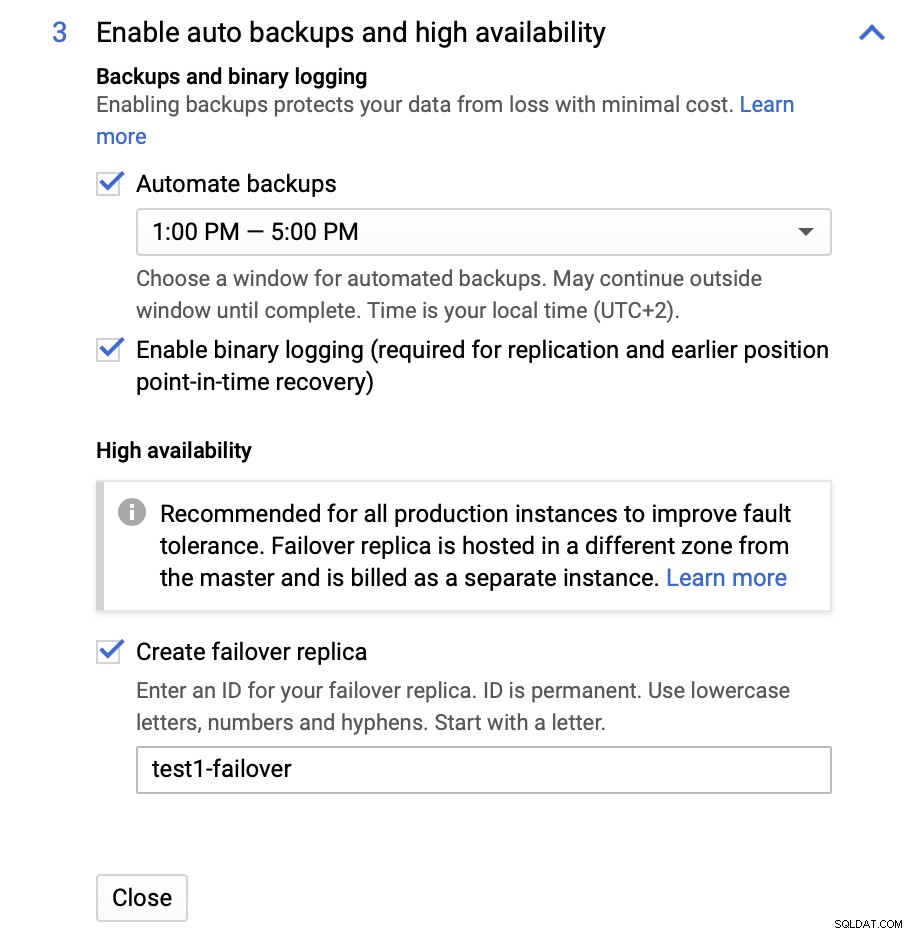
Qui possiamo scegliere di creare una replica di failover. Questa replica verrà promossa a master in caso di errore del master originale.

Dopo aver distribuito l'installazione, aggiungiamo uno slave di replica:
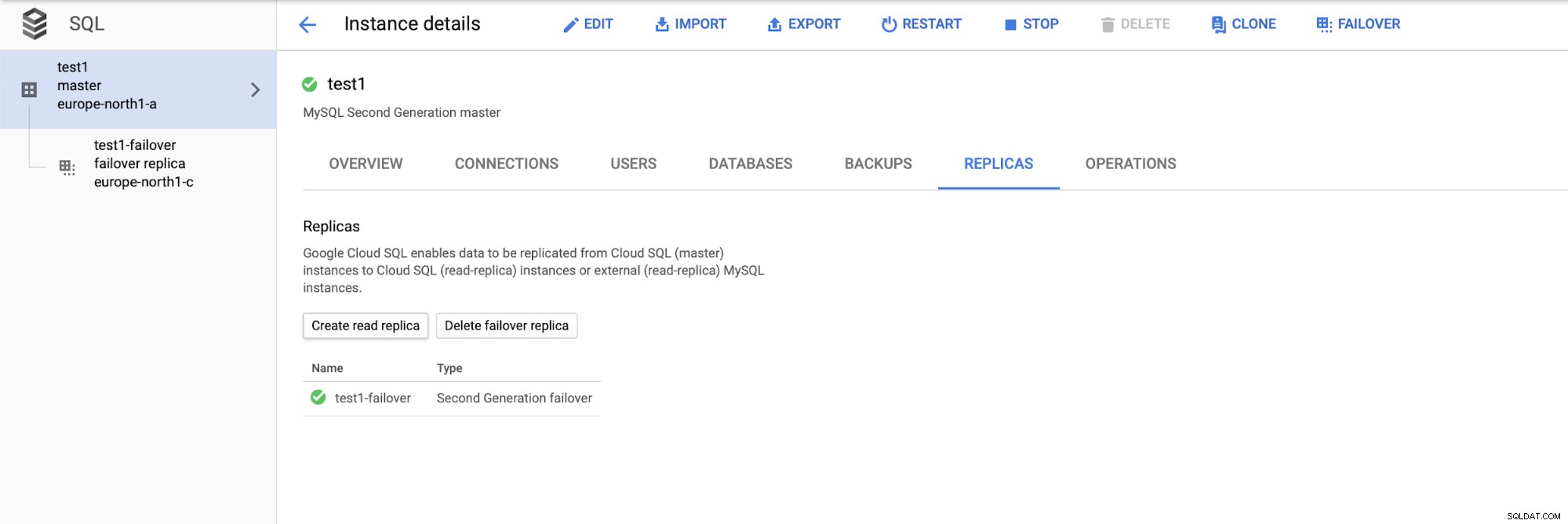
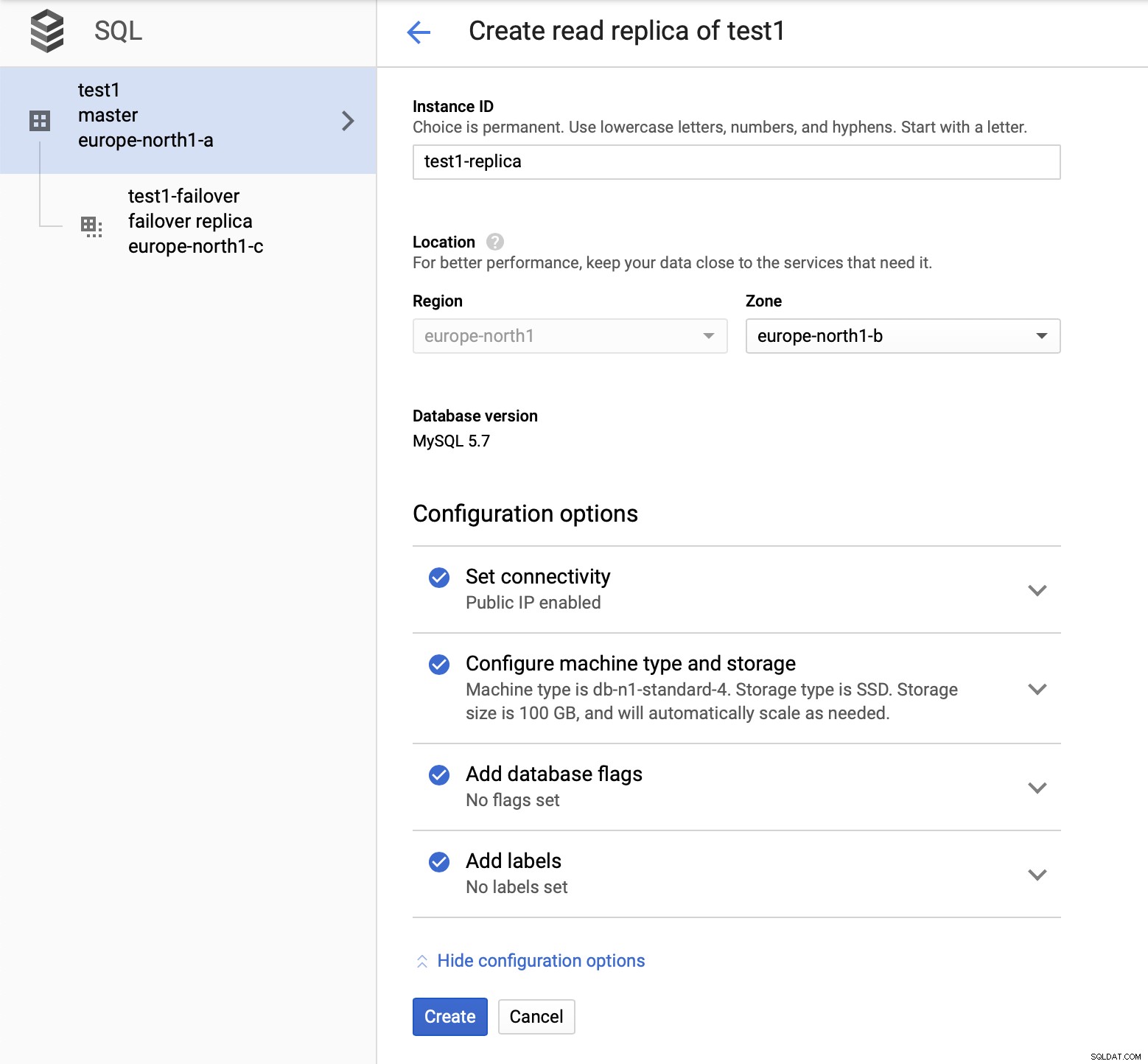
Una volta terminato il processo di aggiunta della replica, siamo pronti per alcuni prove. Eseguiremo il carico di lavoro di prova utilizzando Sysbench sul nostro master, replica di failover e replica di lettura per vedere come funzionerà. Eseguiremo tre istanze di Sysbench, utilizzando gli endpoint per tutti e tre i tipi di nodi.
Quindi attiveremo il failover manuale tramite l'interfaccia utente:
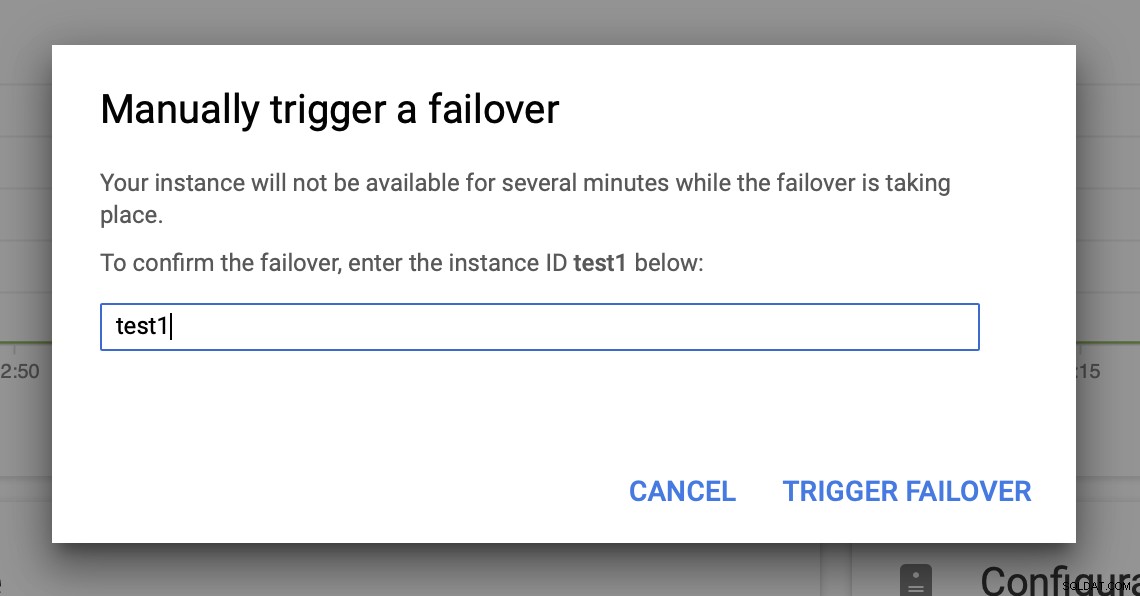
Test del failover MySQL su Google Cloud Platform?
Sono arrivato a questo punto senza alcuna conoscenza dettagliata di come funzionano i nodi SQL in GCP. Tuttavia, avevo alcune aspettative basate sulla precedente esperienza con MySQL e su ciò che ho visto negli altri provider di servizi cloud. Per cominciare, il failover al nodo di failover dovrebbe essere molto rapido. Quello che vorremmo è mantenere disponibili gli slave di replica, senza la necessità di una ricostruzione. Vorremmo anche vedere quanto velocemente possiamo eseguire il failover una seconda volta (poiché non è raro che il problema si propaghi da un database all'altro).
Cosa abbiamo determinato durante i nostri test...
- Durante il failover, il master è tornato disponibile in 75 - 80 secondi.
- La replica di failover non è stata disponibile per 5-6 minuti.
- La replica di lettura era disponibile durante il processo di failover, ma è diventata non disponibile per 55 - 60 secondi dopo che la replica di failover è diventata disponibile
Di cosa non siamo sicuri...
Cosa succede quando la replica di failover non è disponibile? In base al tempo, sembra che la replica di failover venga ricostruita. Questo ha senso, ma il tempo di ripristino sarebbe fortemente correlato alle dimensioni dell'istanza (in particolare alle prestazioni di I/O) e alle dimensioni del file di dati.
Cosa sta succedendo con la replica di lettura dopo che la replica di failover sarebbe stata ricostruita? In origine, la replica di lettura era collegata al master. Quando il master ha avuto esito negativo, ci si aspetterebbe che la replica di lettura fornisca una vista obsoleta del set di dati. Una volta visualizzato il nuovo master, dovrebbe riconnettersi tramite la replica all'istanza (che era una replica di failover e che è stata promossa a master). Non è necessario un minuto di inattività durante l'esecuzione di CHANGE MASTER.
Ancora più importante, durante il processo di failover non c'è modo di eseguire un altro failover (il che ha senso):
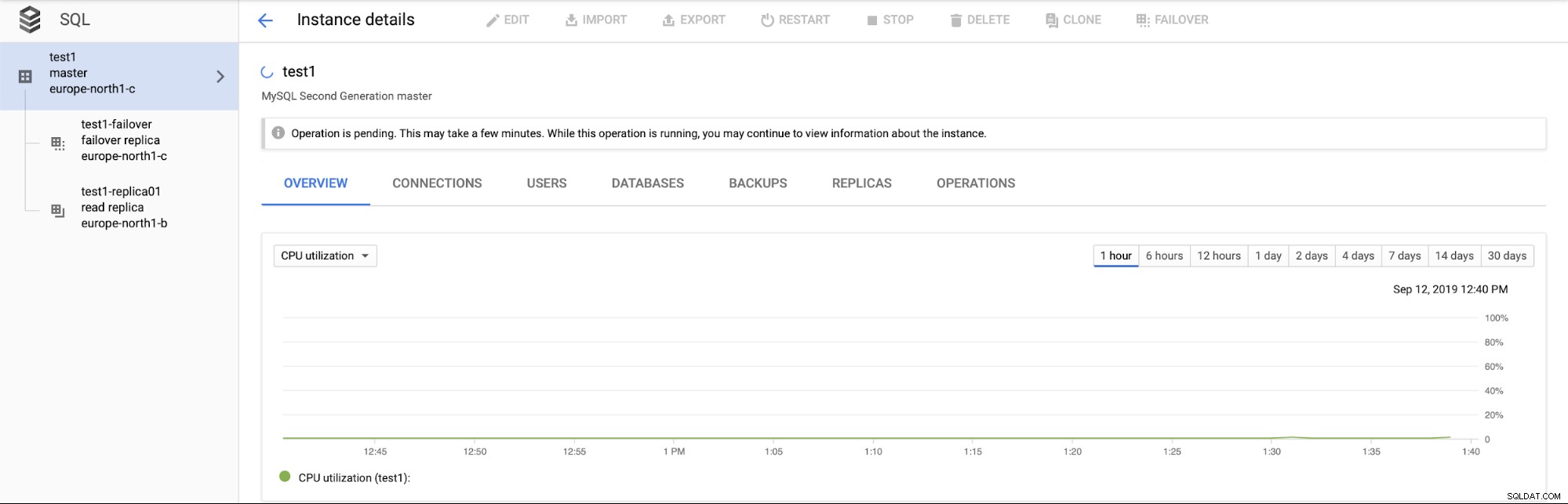
Non è inoltre possibile promuovere la replica di lettura (il che non ha necessariamente senso - ci aspetteremmo di poter promuovere le repliche di lettura in qualsiasi momento).

È importante notare che fare affidamento sulle repliche di lettura per fornire un'elevata disponibilità (senza creare una replica di failover) non è una soluzione praticabile. È possibile promuovere una replica di lettura in modo che diventi un master, tuttavia verrà creato un nuovo cluster; staccato dal resto dei nodi.
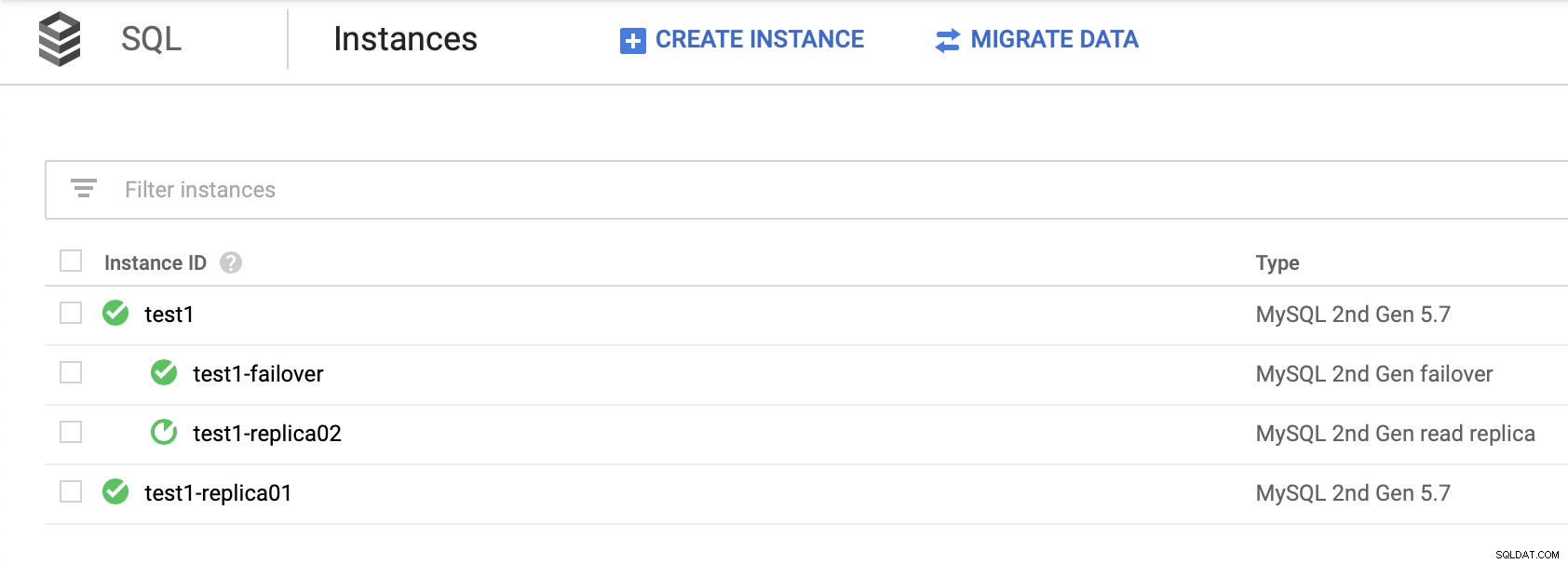
Non c'è modo di asservire le altre repliche dal nuovo cluster. L'unico modo per farlo sarebbe creare nuove repliche, ma questo è un processo che richiede tempo. Inoltre è praticamente inutilizzabile, il che rende la replica di failover l'unica opzione reale per l'elevata disponibilità per i nodi SQL in Google Cloud Platform.
Conclusione
Sebbene sia possibile creare un ambiente ad alta disponibilità per i nodi SQL in GCP, il master non sarà disponibile per circa un minuto e mezzo. L'intero processo (inclusa la ricostruzione della replica di failover e alcune azioni sulle repliche di lettura) ha richiesto diversi minuti. Durante questo periodo non siamo stati in grado di attivare un failover aggiuntivo, né di promuovere una replica di lettura.
Ci sono utenti GCP là fuori? Come stai raggiungendo un'elevata disponibilità?