In precedenza abbiamo pubblicato un blog in cui si discuteva del raggiungimento del failover e del failback di MySQL su Google Cloud Platform (GCP) e in questo blog vedremo come il suo rivale, Amazon Relational Database Service (RDS), gestisce il failover. Vedremo anche come eseguire un failback del tuo precedente nodo master, riportandolo al suo ordine originale come master.
Quando si confrontano i cloud pubblici giganti della tecnologia che supportano i servizi di database relazionali gestiti, Amazon è l'unico che offre un'opzione alternativa (insieme a MySQL/MariaDB, PostgreSQL, Oracle e SQL Server) per fornire un proprio tipo di gestione del database chiamato Amazon Aurora. Per coloro che non hanno familiarità con Aurora, è un motore di database relazionale completamente gestito compatibile con MySQL e PostgreSQL. Aurora fa parte del servizio di database gestito Amazon RDS, un servizio Web che semplifica la configurazione, il funzionamento e la scalabilità di un database relazionale nel cloud.
Perché dovresti eseguire il failover o il failback?
La progettazione di un sistema di grandi dimensioni che sia tollerante ai guasti, altamente disponibile, senza Single-Point-Of-Failure (SPOF) richiede test adeguati per determinare come reagirebbe quando le cose vanno male.
Se sei preoccupato per le prestazioni del tuo sistema quando risponde al rilevamento, isolamento e ripristino dei guasti (FDIR) del tuo sistema, il failover e il failback dovrebbero essere di grande importanza.
Failover del database in Amazon RDS
Il failover si verifica automaticamente (poiché il failover manuale è chiamato switchover). Come discusso in un blog precedente, la necessità di eseguire il failover si verifica quando il master del database corrente subisce un errore di rete o una chiusura anomala del sistema host. Il failover passa a uno stato di ridondanza stabile oa un server, sistema, componente hardware o rete in standby.
In Amazon RDS non è necessario, né è necessario monitorarlo da soli, poiché RDS è un servizio di database gestito (il che significa che Amazon gestisce il lavoro per te). Questo servizio gestisce cose come problemi hardware, backup e ripristino, aggiornamenti software, aggiornamenti di archiviazione e persino patch software. Ne parleremo più avanti in questo blog.
Failback del database in Amazon RDS
Nel blog precedente abbiamo anche spiegato il motivo per cui dovresti eseguire il failback. In un tipico ambiente replicato, il master deve essere sufficientemente potente da sopportare un carico enorme, soprattutto quando il requisito del carico di lavoro è elevato. La configurazione principale richiede specifiche hardware adeguate per garantire che possa elaborare scritture, generare eventi di replica, elaborare letture critiche e così via in modo stabile. Quando è richiesto il failover durante il ripristino di emergenza (o per la manutenzione), non è raro che quando si promuove un nuovo master si possa utilizzare hardware di qualità inferiore. Questa situazione potrebbe temporaneamente andare bene, ma a lungo termine, il master designato deve essere riportato per guidare la replica dopo che è stata considerata sana (o che la manutenzione è stata completata).
Contrariamente al failover, le operazioni di failback di solito si verificano in un ambiente controllato utilizzando il passaggio. Raramente viene fatto quando si è in modalità panico. Questo approccio offre ai tuoi ingegneri abbastanza tempo per pianificare attentamente e provare l'esercizio per garantire una transizione graduale. Il suo obiettivo principale è semplicemente riportare il buon vecchio master allo stato più recente e ripristinare la configurazione della replica alla sua topologia originale. Dal momento che abbiamo a che fare con Amazon RDS, non c'è davvero bisogno che tu sia eccessivamente preoccupato per questo tipo di problemi poiché si tratta di un servizio gestito con la maggior parte dei lavori gestiti da Amazon.
In che modo Amazon RDS gestisce il failover del database?
Quando si distribuiscono i nodi Amazon RDS, è possibile configurare il cluster di database con Multi-Availability Zone (AZ) o in una Single-Availability Zone. Controlliamo ciascuno di essi su come viene elaborato il failover.
Cos'è una configurazione Multi-AZ?
Quando si verifica una catastrofe o un disastro, come interruzioni non pianificate o disastri naturali in cui sono interessate le istanze del database, Amazon RDS passa automaticamente a una replica in standby in un'altra zona di disponibilità. Questa AZ si trova in genere in un altro ramo del data center, spesso lontano dalla zona di disponibilità corrente in cui si trovano le istanze. Queste AZ sono strutture all'avanguardia e ad alta disponibilità che proteggono le tue istanze di database. I tempi di failover dipendono dal completamento dell'installazione, che spesso si basa sulle dimensioni e sull'attività del database, nonché su altre condizioni presenti nel momento in cui l'istanza database principale è diventata non disponibile.
I tempi di failover sono in genere di 60-120 secondi. Tuttavia, possono essere più lunghi, poiché transazioni di grandi dimensioni o un lungo processo di ripristino possono aumentare i tempi di failover. Al termine del failover, potrebbe essere necessario del tempo aggiuntivo prima che la console RDS (UI) rifletta la nuova zona di disponibilità.
Cos'è un'impostazione AZ singola?
Le configurazioni Single-AZ devono essere utilizzate per le istanze del database solo se l'RTO (Recovery Time Objective) e l'RPO (Recovery Point Objective) sono sufficientemente alti da consentirlo. L'utilizzo di una singola AZ comporta dei rischi, ad esempio lunghi tempi di inattività che potrebbero interrompere le operazioni aziendali.
Scenari di errore RDS comuni
La quantità di tempo di inattività dipende dal tipo di guasto. Esaminiamo cosa sono e come viene gestito il ripristino dell'istanza.
Istanza ripristinabile non riuscita
Un errore dell'istanza Amazon RDS si verifica quando l'istanza EC2 sottostante subisce un errore. Al verificarsi, AWS attiverà una notifica di evento e ti invierà un avviso utilizzando Amazon RDS Event Notifications. Questo sistema utilizza AWS Simple Notification Service (SNS) come elaboratore di avvisi.
RDS proverà automaticamente ad avviare una nuova istanza nella stessa zona di disponibilità, collegare il volume EBS e tentare il ripristino. In questo scenario, RTO è in genere inferiore a 30 minuti. RPO è zero perché è stato possibile recuperare il volume EBS. Il volume EBS si trova in una singola zona di disponibilità e questo tipo di ripristino si verifica nella stessa zona di disponibilità dell'istanza originale.
Errori dell'istanza non ripristinabile o errori del volume EBS
Per il ripristino dell'istanza RDS non riuscito (o se il volume EBS sottostante subisce un errore di perdita di dati) è necessario il ripristino point-in-time (PITR). PITR non è gestito automaticamente da Amazon, quindi è necessario creare uno script per automatizzarlo (utilizzando AWS Lambda) o farlo manualmente.
La tempistica RTO richiede l'avvio di una nuova istanza Amazon RDS, che avrà un nuovo nome DNS una volta creata, e quindi l'applicazione di tutte le modifiche dall'ultimo backup.
L'RPO è in genere di 5 minuti, ma puoi trovarlo chiamando RDS:describe-db-instances:LatestRestorableTime. Il tempo può variare da 10 minuti a ore a seconda del numero di log da applicare. Può essere determinato solo mediante test poiché dipende dalle dimensioni del database, dal numero di modifiche apportate dall'ultimo backup e dai livelli di carico di lavoro sul database. Poiché i backup e i registri delle transazioni sono archiviati in Amazon S3, questo ripristino può avvenire in qualsiasi zona di disponibilità supportata nella regione.
Una volta creata la nuova istanza, dovrai aggiornare il nome dell'endpoint del tuo client. Hai anche la possibilità di rinominarlo con il nome dell'endpoint della vecchia istanza database (ma ciò richiede di eliminare la vecchia istanza non riuscita), ma ciò rende impossibile determinare la causa principale del problema.
Interruzioni della zona di disponibilità
Le interruzioni della zona di disponibilità possono essere temporanee e rare, tuttavia, se l'errore AZ è più permanente, l'istanza verrà impostata su uno stato di errore. Il ripristino funzionerebbe come descritto in precedenza e una nuova istanza potrebbe essere creata in una diversa AZ, utilizzando il ripristino point-in-time. Questo passaggio deve essere eseguito manualmente o tramite script. La strategia per questo tipo di scenario di ripristino dovrebbe far parte dei tuoi piani di ripristino di emergenza (DR) più ampi.
Se l'errore della zona di disponibilità è temporaneo, il database sarà inattivo ma rimarrà nello stato disponibile. Sei responsabile del monitoraggio a livello di applicazione (utilizzando strumenti di Amazon o di terze parti) per rilevare questo tipo di scenario. In questo caso, puoi attendere il ripristino della zona di disponibilità oppure puoi scegliere di ripristinare l'istanza in un'altra zona di disponibilità con un ripristino point-in-time.
L'RTO sarebbe il tempo necessario per avviare una nuova istanza RDS e quindi applicare tutte le modifiche dall'ultimo backup. L'RPO potrebbe essere più lungo, fino al momento in cui si è verificato l'errore della zona di disponibilità.
Test di failover e failback su Amazon RDS
Abbiamo creato e configurato Amazon RDS Aurora utilizzando db.r4.large con una distribuzione Multi-AZ (che creerà una replica/lettore Aurora in una diversa AZ) accessibile solo tramite EC2. Dovrai assicurarti di scegliere questa opzione al momento della creazione se intendi utilizzare Amazon RDS come meccanismo di failover.
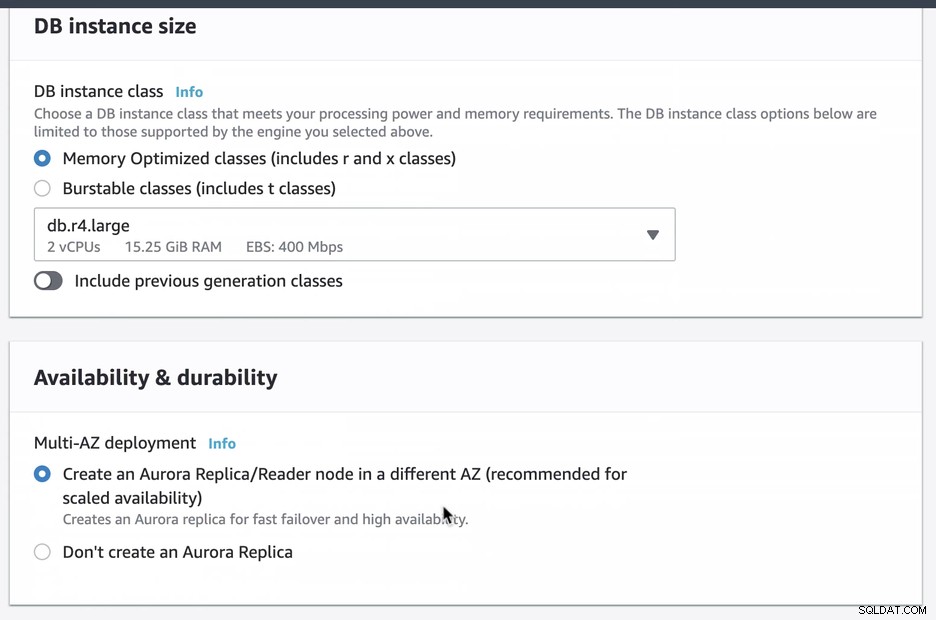
Durante il provisioning della nostra istanza RDS, ci sono voluti circa 11 minuti prima le istanze sono diventate disponibili e accessibili. Di seguito è riportato uno screenshot dei nodi disponibili in RDS dopo la creazione:
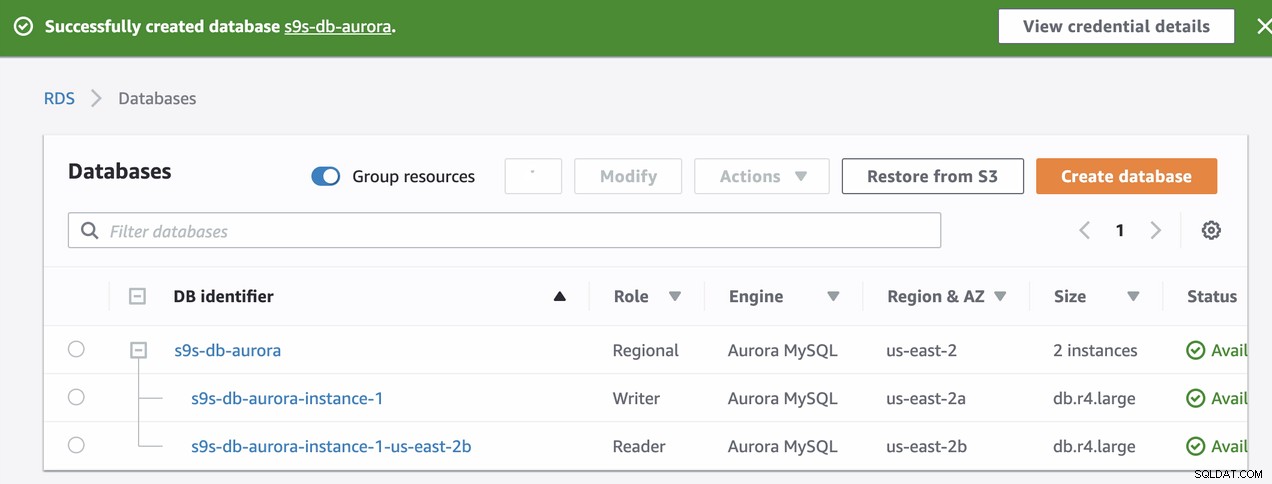
Questi due nodi avranno i loro nomi di endpoint designati, che verranno utilizzare per connettersi dal punto di vista del cliente. Verificalo prima e controlla il nome host sottostante per ciascuno di questi nodi. Per verificare, puoi eseguire questo comando bash di seguito e sostituire i nomi host/endpoint di conseguenza:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Il risultato chiarisce come segue,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulare il failover di Amazon RDS
Ora simuliamo un arresto anomalo per simulare un failover per l'istanza del writer Amazon RDS Aurora, che è s9s-db-aurora-instance-1 con l'endpoint s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
Per fare ciò, connettiti alla tua istanza di writer utilizzando il prompt dei comandi del client mysql e quindi esegui la sintassi seguente:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];L'emissione di questo comando ha il rilevamento del ripristino di Amazon RDS e agisce abbastanza rapidamente. Sebbene la query sia a scopo di test, potrebbe differire quando questa occorrenza si verifica in un evento fattuale. Potresti essere interessato a saperne di più sul test di un arresto anomalo di un'istanza nella loro documentazione. Guarda come finiamo qui sotto:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)L'esecuzione del comando SQL sopra significa che deve simulare un errore del disco per almeno 3 minuti. Ho monitorato il momento per iniziare la simulazione e ci sono voluti circa 18 secondi prima che iniziasse il failover.
Vedi sotto come RDS gestisce l'errore di simulazione e il failover,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+I risultati di questa simulazione sono piuttosto interessanti. Prendiamo questo uno alla volta.
- Intorno alle 10:06:29, ho iniziato a eseguire la query di simulazione come indicato sopra.
- Intorno alle 10:06:44, mostra che l'endpoint s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com con nome host assegnato di ip-10-20-1- 139 dove in effetti è l'istanza di sola lettura, è diventato inaccessibile tuttavia il comando di simulazione è stato eseguito sotto l'istanza di lettura-scrittura.
- Intorno alle 10:06:51, mostra che l'endpoint s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com con nome host assegnato di ip-10-20-1- 139 è attivo ma è contrassegnato come stato di lettura-scrittura. Tieni presente che la variabile innodb_read_only, per le istanze gestite di Aurora MySQL, questo è il suo identificatore per determinare se l'host è un nodo di lettura-scrittura o di sola lettura e Aurora funziona anche solo sul motore di archiviazione InnoDB per le istanze comptable MySQL.
- Intorno alle 10:07:13, l'ordine è cambiato. Ciò significa che il failover è stato eseguito e le istanze sono state assegnate agli endpoint designati.
Controlla il risultato di seguito mostrato nella console RDS:
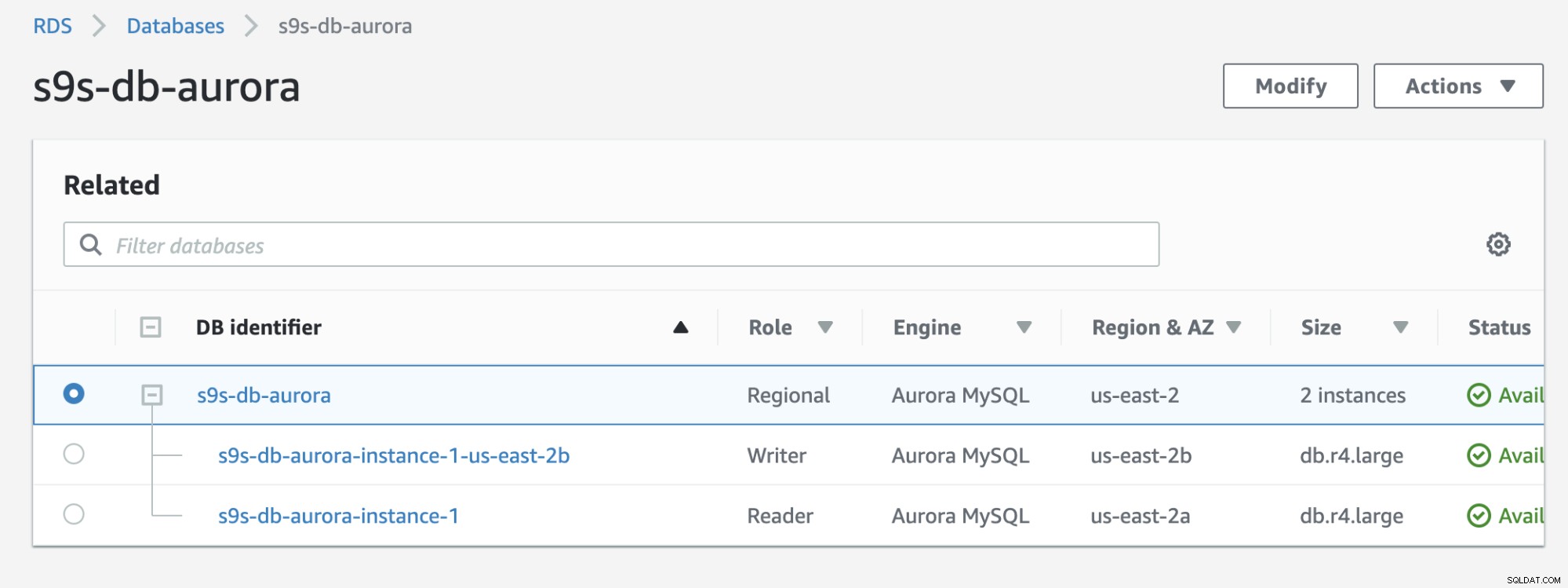
Se si confronta con il precedente, s9s-db-aurora- instance-1 era un lettore, ma poi promosso come scrittore dopo il failover. Il processo, incluso il test, ha richiesto circa 44 secondi per completare l'attività, ma il failover mostra completato in quasi 30 secondi. È impressionante e veloce per un failover, soprattutto considerando che si tratta di un database di servizi gestiti; il che significa che non devi preoccuparti di problemi hardware o di manutenzione.
Esecuzione di un failback in Amazon RDS
Il failback in Amazon RDS è piuttosto semplice. Prima di esaminarlo, aggiungiamo una nuova replica del lettore. Abbiamo bisogno di un'opzione per testare e identificare da quale nodo AWS RDS sceglierebbe quando tenta di eseguire il failback al master desiderato (o il failback al master precedente) e per vedere se seleziona il nodo giusto in base alla priorità. L'elenco corrente delle istanze al momento e i relativi endpoint sono mostrati di seguito.
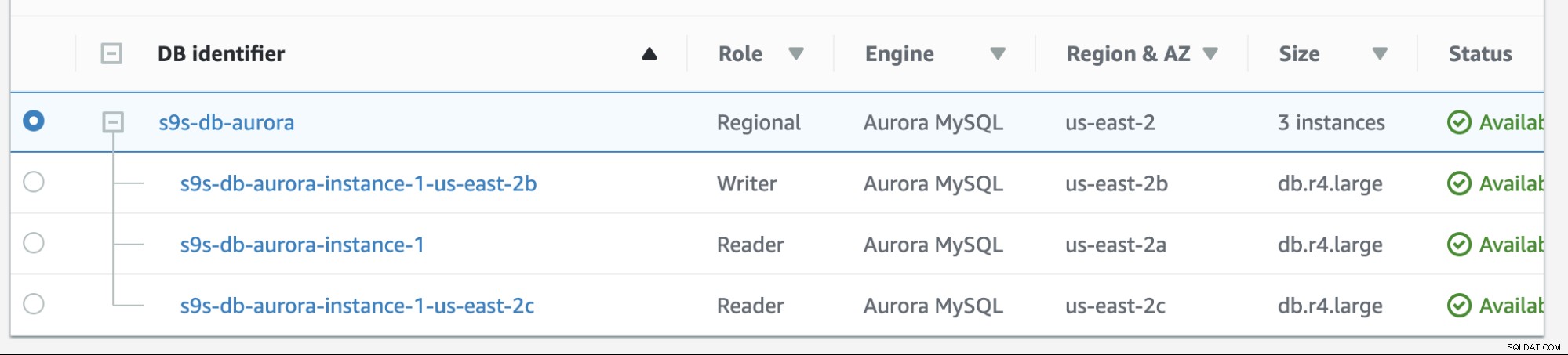

La nuova replica si trova su us-east-2c AZ con nome host db di ip-10-20-2-239.
Proveremo a eseguire un failback utilizzando l'istanza s9s-db-aurora-instance-1 come destinazione di failback desiderata. In questa configurazione abbiamo due istanze di lettura. Per garantire che il nodo corretto venga prelevato durante il failover, sarà necessario stabilire se la priorità o la disponibilità sono in primo piano (livello 0> livello 1> livello 2 e così via fino al livello 15). Questo può essere fatto modificando l'istanza o durante la creazione della replica.
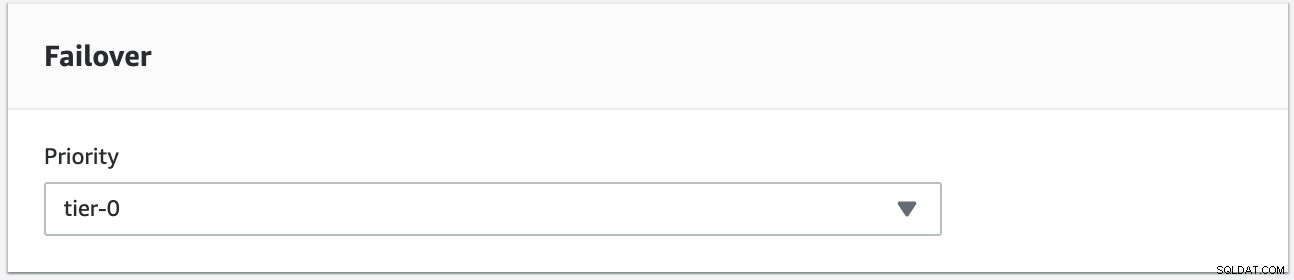
Puoi verificarlo nella tua console RDS.
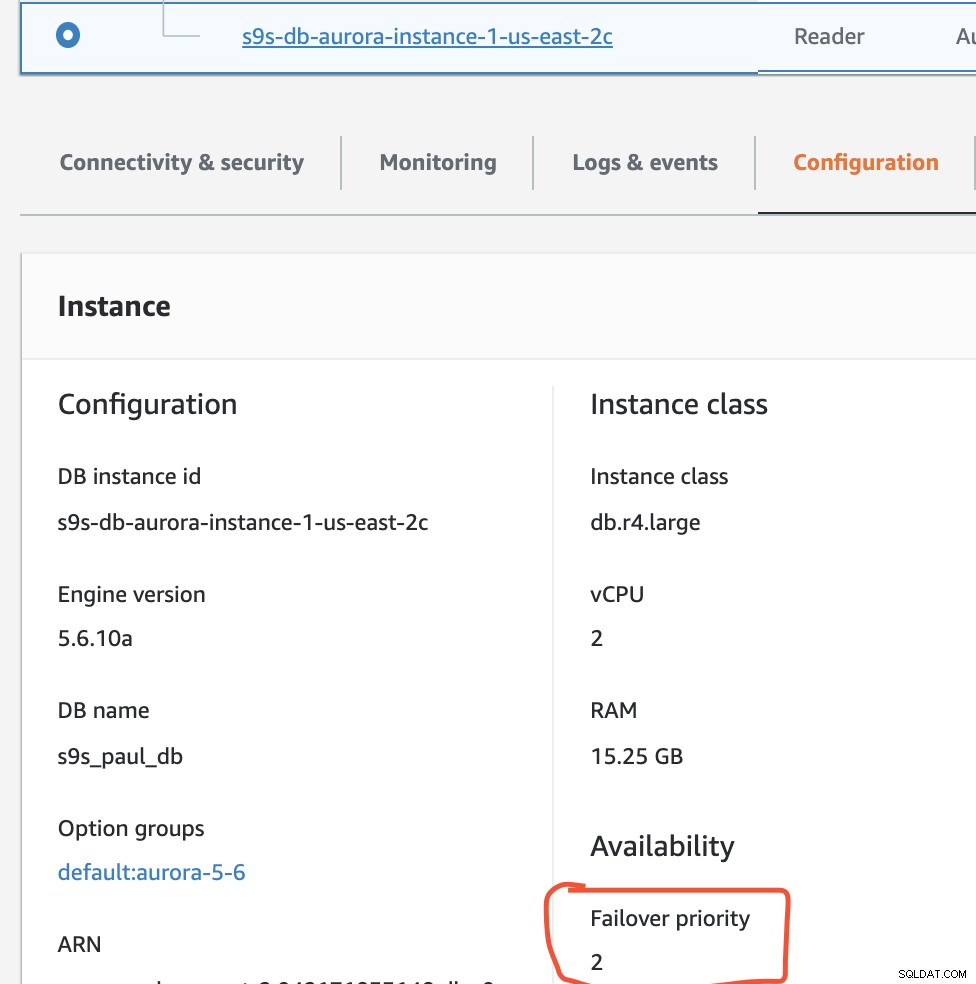
In questa configurazione s9s-db-aurora-instance-1 ha la priorità =0 (ed è una replica di lettura), s9s-db-aurora-instance-1-us-east-2b ha priorità =1 (ed è lo scrittore corrente) e s9s-db-aurora-instance-1-us- east-2c ha priorità =2 (ed è anche una replica di lettura). Vediamo cosa succede quando proviamo a eseguire il failback.
Puoi monitorare lo stato usando questo comando.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Dopo che il failover è stato attivato, verrà eseguito il failback sulla destinazione desiderata, ovvero il nodo s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Il tentativo di failback è iniziato alle 13:30:59 e si è concluso intorno alle 13:31:38 (30 secondi più vicini). Finisce per circa 32 secondi in questo test, che è ancora veloce.
Ho verificato il failover/failback più volte e ha costantemente scambiato il suo stato di lettura-scrittura tra le istanze s9s-db-aurora-instance-1 e s9s-db-aurora-instance-1- us-est-2b. Ciò lascia s9s-db-aurora-instance-1-us-east-2c non selezionato a meno che entrambi i nodi non stiano riscontrando problemi (il che è molto raro poiché si trovano tutti in AZ diversi).
Durante i tentativi di failover/failback, RDS va a un ritmo di transizione rapido durante il failover a circa 15 - 25 secondi (che è molto veloce). Tieni presente che non abbiamo enormi file di dati archiviati in questa istanza, ma è comunque abbastanza impressionante considerando che non c'è nient'altro da gestire.
Conclusione
L'esecuzione di un Single-AZ introduce pericolo durante l'esecuzione di un failover. Amazon RDS ti consente di modificare e convertire la tua configurazione Single-AZ in una configurazione compatibile con Multi-AZ, anche se ciò aggiungerà alcuni costi per te. Single-AZ può andare bene se sei d'accordo con un tempo RTO e RPO più elevati, ma sicuramente non è raccomandato per applicazioni aziendali ad alto traffico, mission-critical.
Con Multi-AZ, puoi automatizzare il failover e il failback su Amazon RDS, dedicando il tuo tempo all'ottimizzazione o all'ottimizzazione delle query. Ciò risolve molti problemi affrontati da DevOps o DBA.
Sebbene Amazon RDS possa causare un dilemma in alcune organizzazioni (poiché non è indipendente dalla piattaforma), è comunque degno di considerazione; soprattutto se la tua applicazione richiede un piano di ripristino di emergenza a lungo termine e non vuoi perdere tempo a preoccuparti dell'hardware e della pianificazione della capacità.