Percona XtraDB Cluster è una soluzione ad alta disponibilità molto nota nel mondo MySQL. Si basa su Galera Cluster e fornisce una replica virtualmente sincrona su più nodi. Come per ogni database, è fondamentale tenere traccia di ciò che sta accadendo nel sistema, se le prestazioni sono ai livelli previsti e, in caso negativo, qual è il collo di bottiglia. Questo è della massima importanza per essere in grado di reagire adeguatamente nella situazione in cui le prestazioni sono influenzate. Naturalmente, Percona XtraDB Cluster viene fornito con più metriche e non è sempre chiaro quali di esse siano le più importanti per tenere traccia dello stato del database. In questo blog discuteremo un paio delle metriche chiave da tenere d'occhio mentre lavori con PXC.
Per chiarire, ci concentreremo sulle metriche esclusive di PXC e Galera, non tratteremo le metriche per MySQL o InnoDB. Queste metriche sono state discusse nei nostri blog precedenti.
Diamo un'occhiata ad alcune delle informazioni più importanti che PXC ci presenta.
Controllo del flusso
Il controllo del flusso è praticamente la metrica più importante che puoi monitorare in qualsiasi cluster Galera, quindi facciamo un po' di background. Galera è un cluster multimaster, virtualmente sincrono. È possibile eseguire scritture su qualsiasi nodo del database che lo costituisce. Ogni scrittura deve essere inviata a tutti i nodi del cluster per garantire che possa essere applicata:questo processo è chiamato certificazione. Nessuna transazione può essere applicata prima che tutti i nodi concordino che può essere eseguito il commit. Se uno qualsiasi dei nodi ha problemi di prestazioni che lo rendono incapace di far fronte al traffico, inizierà a emettere messaggi di controllo del flusso che hanno lo scopo di informare il resto del cluster sui problemi di prestazioni e chiedere loro di ridurre il carico di lavoro e aiutare il ritardo nodo per raggiungere il resto del cluster.
Puoi tenere traccia di quando i nodi hanno dovuto introdurre una pausa artificiale per consentire ai loro peer in ritardo di recuperare il ritardo utilizzando la metrica in pausa del controllo del flusso (wsrep_flow_control_paused):

Puoi anche tenere traccia se il nodo sta inviando o ricevendo i messaggi di controllo del flusso (wsrep_flow_control_recv e wsrep_flow_control_sent).
Queste informazioni ti aiuteranno a capire meglio quale nodo non sta funzionando allo stesso modo livello come i suoi pari. Puoi quindi concentrarti su quel nodo e provare a capire qual è il problema e come rimuovere il collo di bottiglia.
Invia e ricevi code
Queste metriche sono in qualche modo correlate al controllo del flusso. Come abbiamo discusso, un nodo potrebbe essere in ritardo rispetto ad altri nodi nel cluster. Può essere causato da una divisione del carico di lavoro non uniforme o da altri motivi (alcuni processi in esecuzione in background, backup o alcune query personalizzate e pesanti). Prima che si attivi il controllo del flusso, i nodi in ritardo tenteranno di archiviare i set di scrittura in arrivo nella coda di ricezione (wsrep_local_recv_queue) sperando che l'impatto sulle prestazioni sia transitorio e sarà in grado di recuperare il ritardo molto presto. Solo se la coda diventa troppo grande (è governata dall'impostazione gcs.fc_limit), i messaggi di controllo del flusso iniziano a essere inviati attraverso il cluster.

Puoi pensare a una coda di ricezione come all'indicatore iniziale che mostra che c'è ci sono problemi con le prestazioni e il controllo del flusso potrebbe intervenire.

D'altra parte, la coda di invio (wsrep_local_send_queue) ti dirà che il nodo non è in grado di inviare i set di scrittura ad altri membri del cluster, il che potrebbe indicare problemi con la connettività di rete (spingendo i set di scrittura su la rete non è molto dispendiosa in termini di risorse).
Metriche di parallelizzazione
Il cluster Percona XtraDB può essere configurato per utilizzare più thread per applicare i set di scrittura in ingresso:consente di gestire meglio più thread che si connettono al cluster ed emettono scritture contemporaneamente. Ci sono due metriche principali che potresti voler tenere d'occhio.
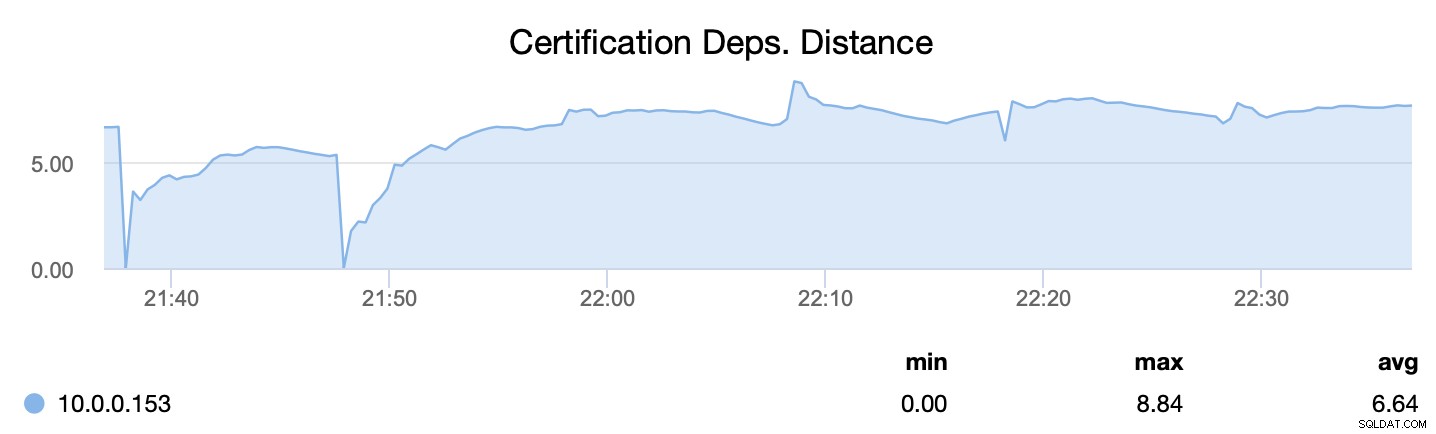
In primo luogo, wsrep_cert_deps_distance, ci dice qual è il potenziale di parallelizzazione:quanti writeset possono, potenzialmente, essere applicati contemporaneamente. Sulla base di questo valore è possibile configurare il numero di thread slave paralleli (wsrep_slave_threads) che funzioneranno sull'applicazione dei writeset in entrata. La regola pratica è che non ha senso configurare più thread del valore di wsrep_cert_deps_distance.
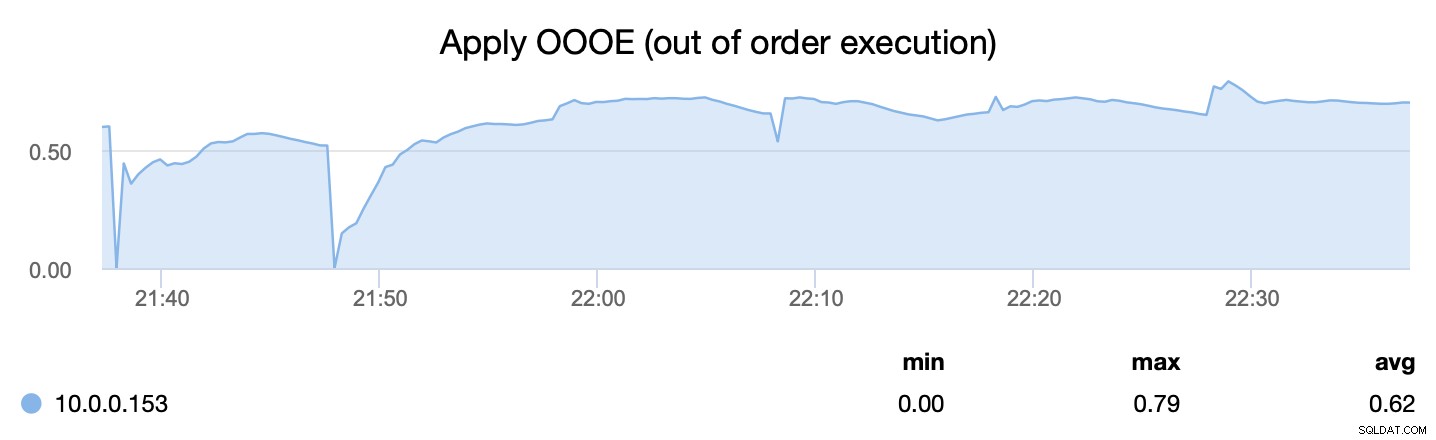
La seconda metrica, d'altra parte, ci dice con quanta efficienza siamo stati in grado di parallelizzare il processo di applicazione dei set di scritture - wsrep_apply_oooe ci dice quanto spesso l'applicatore ha iniziato ad applicare i set di scritture fuori ordine (il che indica una migliore parallelizzazione ).
Conclusione
Come puoi vedere, ci sono un paio di parametri che vale la pena esaminare in Percona XtraDB Cluster. Naturalmente, come abbiamo affermato all'inizio di questo blog, si tratta di metriche strettamente correlate a PXC e Galera Cluster in generale.
Dovresti anche tenere d'occhio le normali metriche MySQL e InnoDB per avere una migliore comprensione dello stato del tuo database. E ricorda, puoi monitorare questa tecnologia gratuitamente utilizzando ClusterControl Community Edition.



