Ci sono state molte discussioni su In-Memory OLTP (la funzionalità precedentemente nota come "Hekaton") e su come può aiutare carichi di lavoro molto specifici e ad alto volume. Nel mezzo di un'altra conversazione, mi è capitato di notare qualcosa in CREATE TYPE documentazione per SQL Server 2014 che mi ha fatto pensare che potrebbe esserci un caso d'uso più generale:

Aggiunte relativamente silenziose e non annunciate alla documentazione CREATE TYPE
Sulla base del diagramma di sintassi, sembra che i parametri con valori di tabella (TVP) possano essere ottimizzati per la memoria, proprio come possono fare le tabelle permanenti. E con ciò, le ruote hanno subito iniziato a girare.
Una cosa per cui ho usato TVP è aiutare i clienti a eliminare i costosi metodi di divisione delle stringhe in T-SQL o CLR (vedi sfondo nei post precedenti qui, qui e qui). Nei miei test, l'utilizzo di un normale TVP ha superato i modelli equivalenti utilizzando le funzioni di divisione CLR o T-SQL di un margine significativo (25-50%). Logicamente mi chiedevo:ci sarebbe un guadagno in termini di prestazioni da un TVP ottimizzato per la memoria?
C'è stata una certa apprensione per In-Memory OLTP in generale, perché ci sono molte limitazioni e lacune nelle funzionalità, è necessario un filegroup separato per i dati ottimizzati per la memoria, è necessario spostare intere tabelle in memoria ottimizzata e il miglior vantaggio è in genere ottenuto creando anche stored procedure compilate in modo nativo (che hanno il proprio insieme di limitazioni). Come dimostrerò, supponendo che il tipo di tabella contenga semplici strutture di dati (ad es. che rappresentano un insieme di numeri interi o stringhe), l'utilizzo di questa tecnologia solo per i TVP ne elimina alcuni di questi problemi.
Il test
Avrai comunque bisogno di un filegroup ottimizzato per la memoria anche se non creerai tabelle permanenti ottimizzate per la memoria. Quindi creiamo un nuovo database con la struttura appropriata in atto:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Ora possiamo creare un tipo di tabella normale, come faremmo oggi, e un tipo di tabella ottimizzato per la memoria con un indice hash non cluster e un conteggio dei bucket che ho estratto dall'aria (ulteriori informazioni sul calcolo dei requisiti di memoria e sul conteggio dei bucket in il mondo reale qui):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Se lo provi in un database che non ha un filegroup ottimizzato per la memoria, riceverai questo messaggio di errore, proprio come se provassi a creare una normale tabella ottimizzata per la memoria:
Msg 41337, livello 16, stato 0, riga 9Il filegroup MEMORY_OPTIMIZED_DATA non esiste o è vuoto. Non è possibile creare tabelle ottimizzate per la memoria per un database finché non dispone di un filegroup MEMORY_OPTIMIZED_DATA non vuoto.
Per testare una query su una tabella normale, non ottimizzata per la memoria, ho semplicemente inserito alcuni dati in una nuova tabella dal database di esempio AdventureWorks2012, utilizzando SELECT INTO per ignorare tutti quei fastidiosi vincoli, indici e proprietà estese, quindi ho creato un indice cluster sulla colonna su cui sapevo che avrei cercato (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
Successivamente ho creato quattro stored procedure:due per ogni tipo di tabella; ciascuno usando EXISTS e JOIN approcci (di solito mi piace esaminare entrambi, anche se preferisco EXISTS; più avanti vedrai perché non volevo limitare i miei test solo a EXISTS ). In questo caso, assegno semplicemente una riga arbitraria a una variabile, in modo da poter osservare conteggi di esecuzione elevati senza occuparmi di set di risultati e altri output e sovraccarico:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
Successivamente, dovevo simulare il tipo di query che in genere viene contro questo tipo di tabella e richiede in primo luogo un TVP o un modello simile. Immagina un modulo con un menu a discesa o un insieme di caselle di controllo contenenti un elenco di prodotti e l'utente può selezionare i 20 o 50 o 200 che desidera confrontare, elencare, cosa hai. I valori non saranno in un bel set contiguo; in genere saranno sparsi ovunque (se fosse un intervallo prevedibilmente contiguo, la query sarebbe molto più semplice:valori iniziali e finali). Quindi ho appena scelto 20 valori arbitrari dalla tabella (cercando di rimanere al di sotto, diciamo, del 5% della dimensione della tabella), ordinati in modo casuale. Un modo semplice per creare un VALUES riutilizzabile una clausola come questa è la seguente:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; I risultati (il tuo quasi sicuramente varierà):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735 ),(441),(409),(454),(780),(966),(988),(512),
A differenza di un INSERT...SELECT diretto , questo rende abbastanza facile manipolare quell'output in un'istruzione riutilizzabile per popolare ripetutamente i nostri TVP con gli stessi valori e durante più iterazioni di test:
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
Se eseguiamo questo batch utilizzando SQL Sentry Plan Explorer, i piani risultanti mostrano una grande differenza:il TVP in memoria è in grado di utilizzare un join di loop nidificato e 20 ricerche di indici cluster a riga singola, rispetto a un merge join alimentato da 502 righe da una scansione dell'indice cluster per il TVP classico. E in questo caso, EXISTS e JOIN hanno prodotto piani identici. Questo potrebbe dare suggerimenti con un numero di valori molto più elevato, ma continuiamo con l'ipotesi che il numero di valori sarà inferiore al 5% della dimensione della tabella:
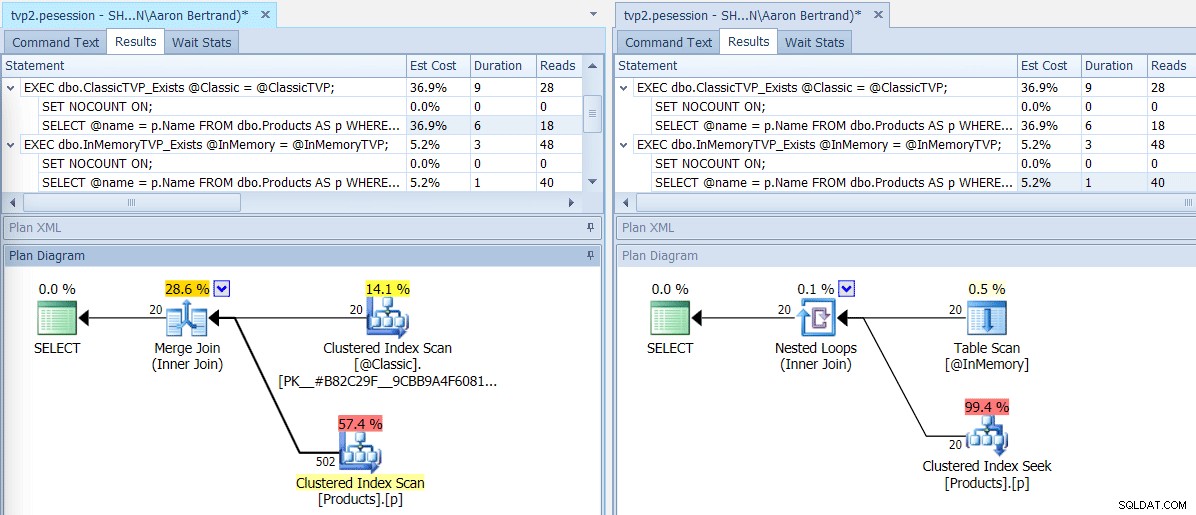 Piani per TVP classici e in memoria
Piani per TVP classici e in memoria
 Suggerimenti per gli operatori di scansione/ricerca, che evidenziano le principali differenze – Classico a sinistra, In- Memoria a destra
Suggerimenti per gli operatori di scansione/ricerca, che evidenziano le principali differenze – Classico a sinistra, In- Memoria a destra
Ora cosa significa questo su larga scala? Disattiviamo qualsiasi raccolta showplan e modifichiamo leggermente lo script di test per eseguire ciascuna procedura 100.000 volte, acquisendo manualmente il runtime cumulativo:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
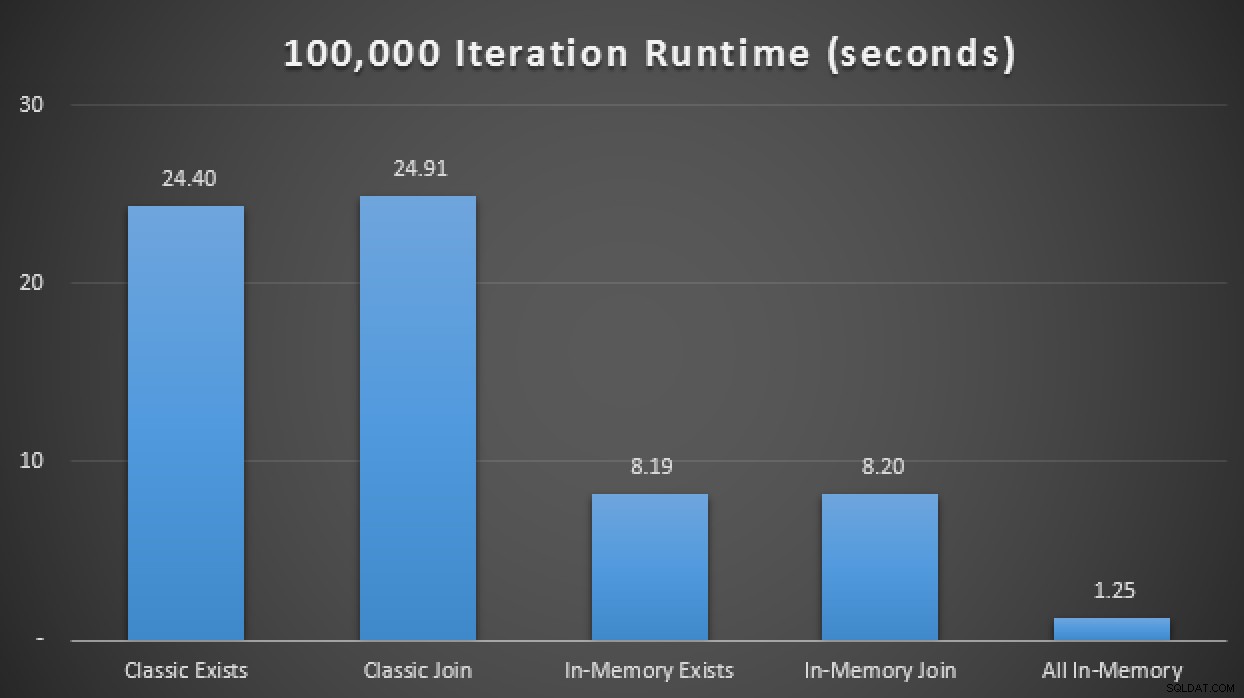
SELECT SYSDATETIME(); Nei risultati, con una media di oltre 10 esecuzioni, vediamo che, almeno in questo test case limitato, l'utilizzo di un tipo di tabella ottimizzato per la memoria ha prodotto un miglioramento di circa 3 volte rispetto alla metrica delle prestazioni probabilmente più critica in OLTP (durata del runtime):
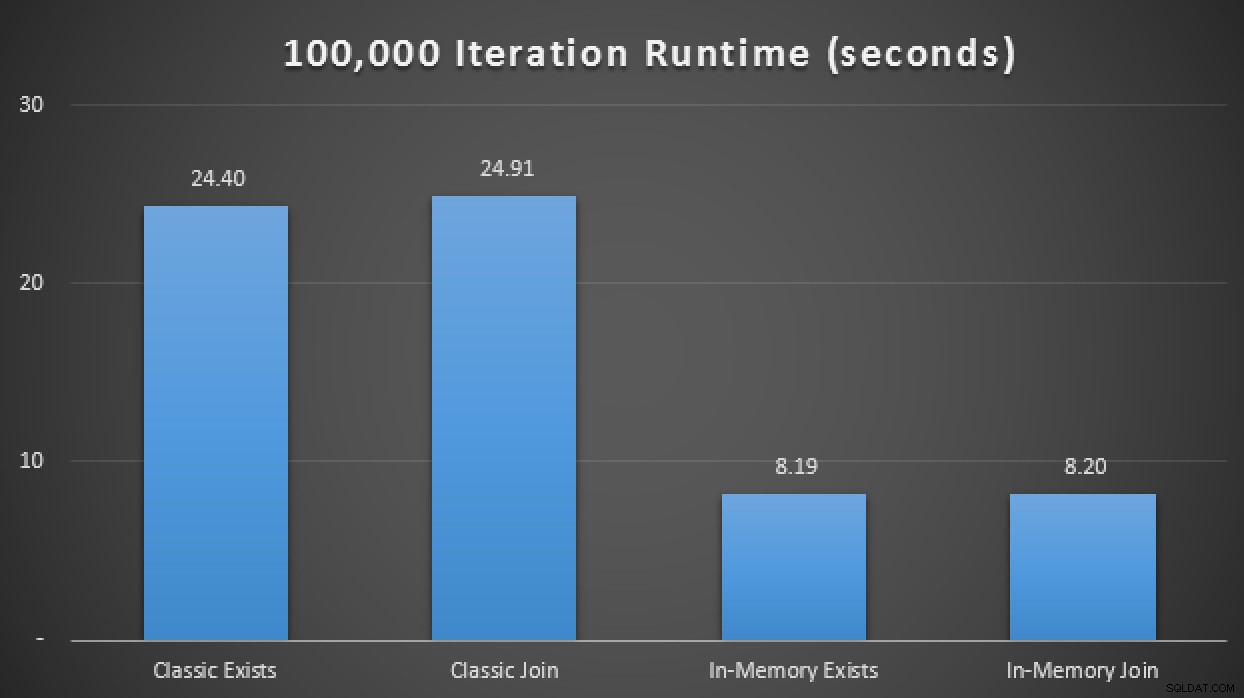
Risultati di runtime che mostrano un miglioramento di 3 volte con i TVP in memoria
In-Memory + In-Memory + In-Memory:Inizio In-Memory
Ora che abbiamo visto cosa possiamo fare semplicemente cambiando il nostro tipo di tabella normale in un tipo di tabella ottimizzato per la memoria, vediamo se possiamo spremere altre prestazioni da questo stesso modello di query quando applichiamo il trifecta:un in-memory tabella, utilizzando una stored procedure ottimizzata per la memoria compilata in modo nativo, che accetta una tabella in memoria come parametro con valori di tabella.
Per prima cosa, dobbiamo creare una nuova copia della tabella e popolarla dalla tabella locale che abbiamo già creato:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
Successivamente, creiamo una stored procedure compilata in modo nativo che prende il nostro tipo di tabella ottimizzato per la memoria esistente come TVP:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Un paio di avvertimenti. Non è possibile utilizzare un tipo di tabella normale non ottimizzato per la memoria come parametro per una stored procedure compilata in modo nativo. Se proviamo, otteniamo:
Msg 41323, livello 16, stato 1, procedura InMemoryProcedureIl tipo di tabella 'dbo.ClassicTVP' non è un tipo di tabella ottimizzato per la memoria e non può essere utilizzato in una stored procedure compilata in modo nativo.
Inoltre, non possiamo usare EXISTS modello anche qui; quando proviamo, otteniamo:
Le sottoquery (query nidificate all'interno di un'altra query) non sono supportate con le stored procedure compilate in modo nativo.
Ci sono molti altri avvertimenti e limitazioni con In-Memory OLTP e stored procedure compilate in modo nativo, volevo solo condividere un paio di cose che potrebbero sembrare ovviamente mancanti dal test.
Quindi, aggiungendo questa nuova stored procedure compilata in modo nativo alla matrice di test sopra, ho scoperto che, ancora una volta, con una media di oltre 10 esecuzioni, ha eseguito le 100.000 iterazioni in soli 1,25 secondi. Ciò rappresenta all'incirca un miglioramento di 20 volte rispetto ai TVP normali e un miglioramento di 6-7 volte rispetto ai TVP in memoria che utilizzano tabelle e procedure tradizionali:
Risultati di runtime che mostrano miglioramenti fino a 20 volte con In-Memory ovunque
Conclusione
Se stai utilizzando TVP ora o stai utilizzando modelli che potrebbero essere sostituiti da TVP, devi assolutamente considerare di aggiungere TVP ottimizzati per la memoria ai tuoi piani di test, ma tieni presente che potresti non vedere gli stessi miglioramenti nel tuo scenario. (E, naturalmente, tenendo presente che i TVP in generale hanno molti avvertimenti e limitazioni, e non sono nemmeno appropriati per tutti gli scenari. Erland Sommarskog ha un ottimo articolo sui TVP di oggi qui.)
In effetti potresti vedere che alla fascia bassa del volume e della concorrenza non c'è differenza, ma per favore prova su scala realistica. Questo è stato un test molto semplice e artificioso su un laptop moderno con un singolo SSD, ma quando si parla di volume reale e/o di dischi meccanici spinti, queste caratteristiche prestazionali potrebbero avere molto più peso. È in arrivo un follow-up con alcune dimostrazioni su dimensioni di dati più grandi.