La replica transazionale di SQL Server è una delle tecniche di replica più comuni utilizzate per copiare o distribuire dati su più destinazioni.
Negli articoli precedenti abbiamo discusso della replica di SQL Server, come funziona internamente e come configurare la replica tramite la replica guidata o l'approccio T-SQL. Ora ci concentriamo sui problemi di replica SQL e sulla risoluzione dei problemi correttamente.
Problemi di replica SQL
La maggior parte dei clienti che utilizzano la replica transazionale di SQL Server si concentra principalmente sul raggiungimento di dati quasi in tempo reale disponibili nelle istanze del database dell'abbonato. Pertanto, il DBA che gestisce la replica dovrebbe essere a conoscenza di vari possibili problemi relativi alla replica SQL che potrebbero sorgere. Inoltre, il DBA deve essere in grado di risolvere questi problemi in breve tempo.
Possiamo classificare tutti i problemi di replica SQL nelle categorie seguenti (in base alla mia esperienza):
Problemi di configurazione
- Dimensione massima della replica del testo
- Servizio SQL Server Agent non impostato per l'avvio della modalità automatica
- Le istanze di replica non monitorate entrano in uno stato di Sottoscrizioni non inizializzate
- Problemi noti all'interno di SQL Server
Problemi di autorizzazione
- Problemi di autorizzazione dei processi di SQL Server Agent
- Le credenziali del lavoro di Snapshot Agent non possono accedere al percorso della cartella snapshot
- Le credenziali del lavoro dell'agente di lettura log non possono connettersi al database di pubblicazione/distribuzione
- Le credenziali del lavoro dell'agente di distribuzione non possono connettersi al database di distribuzione/abbonato
Problemi di connettività
- Il server dell'editore non è stato trovato o non era accessibile
- Il server di distribuzione non è stato trovato o non era accessibile
- Il server dell'abbonato non è stato trovato o non era accessibile
Problemi di integrità dei dati
- Errori di violazione della chiave primaria o della chiave univoca
- Errori di riga non trovata
- Errori di violazione di chiavi esterne o altri vincoli
Problemi di prestazioni
- Transazioni attive di lunga durata nel database dell'editore
- Operazioni di INSERT/UPDATE/DELETE in blocco sugli articoli
- Enormi modifiche ai dati all'interno di una singola transazione
- Blocchi nel database di distribuzione
Problemi relativi alla corruzione
- Corruzioni del database dell'editore
- Corruzioni del file di registro transazionale dell'editore
- Corruzioni del database di distribuzione
- Danneggiamento del database degli abbonati
Preparazione dell'ambiente DEMO
Prima di approfondire i dettagli sui problemi di replica SQL, dobbiamo preparare il nostro ambiente per la demo. Come discusso nei miei articoli precedenti, tutte le modifiche ai dati che si verificano nel database dell'abbonato in Replica transazionale non saranno visibili direttamente nel database dell'editore. Pertanto, apporteremo alcune modifiche direttamente nel database degli abbonati a scopo di apprendimento.
Si prega di prestare estrema attenzione e non modificare nulla nei database di produzione. Influirà sull'integrità dei dati dei database degli abbonati. Prenderò gli script di backup per ogni modifica eseguita e utilizzerò tali script per risolvere i problemi di replica SQL.
Modifica 1 – Inserimento di record nella tabella Person.ContactType
Prima di inserire i record in Person.ContacType tabella, diamo un'occhiata alla struttura della tabella, ad alcuni vincoli predefiniti e alle proprietà estese redatte nello script seguente:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Ho scelto questa tabella poiché ha meno colonne. È più conveniente per scopi di prova. Ora, controlliamo cosa abbiamo sulla sua struttura:
- ContactTypeId è definita come COLONNA IDENTITÀ – genererà automaticamente i valori della chiave primaria e NON PER LA REPLICA.
- NON PER LA REPLICA è una proprietà speciale che può essere utilizzata su vari tipi di oggetti come tabelle, vincoli come vincoli di chiave esterna, vincoli di controllo, trigger e colonne di identità su editore o abbonato mentre si utilizza solo una delle metodologie di replica. Consente al DBA di pianificare o implementare la replica per garantire che determinate funzionalità si comportino in modo diverso nell'editore/abbonato durante l'utilizzo della replica.
- Nel nostro caso, indichiamo a SQL Server di utilizzare i valori IDENTITY generati solo sul database Publisher. La proprietà IDENTITY non deve essere utilizzata su Person.ContactType tabella nel database dell'abbonato. Allo stesso modo, possiamo modificare i Vincoli o i Trigger per far sì che si comportino in modo diverso mentre Replica è configurata utilizzando questa opzione.
- Nella tabella sono disponibili altre 2 colonne NOT NULL.
- La tabella ha una chiave primaria definita su ContactTypeId . Solo per ricordare, la chiave primaria è un requisito obbligatorio per la replica. Senza di esso su una tabella, non saremmo in grado di replicare un articolo di tabella.
Ora, INSERISCI un record di esempio in Persona .Tipo di contatto tabella nella AdventureWorks_REPL banca dati:
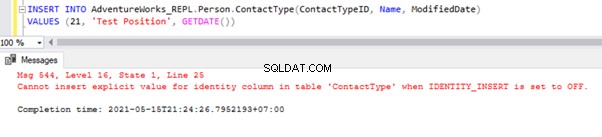
L'INSERT diretto sulla tabella avrà esito negativo nel database dell'abbonato perché la proprietà Identity è disabilitata solo per la replica dall'opzione NON PER LA REPLICA. Ogni volta che eseguiamo l'operazione INSERT manualmente, dobbiamo comunque utilizzare l'opzione SET IDENTITY_INSERT in questo modo:
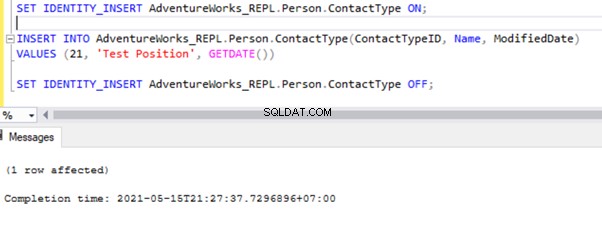
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Dopo aver aggiunto l'opzione SET IDENTITY_INSERT, possiamo INSERT record correttamente in Person.ContactType tabella.
L'esecuzione della SELECT sulla tabella mostra il record appena inserito:
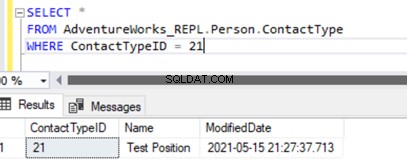
Abbiamo aggiunto un nuovo record solo al database degli abbonati che non è disponibile nel database dell'editore su Person.ContactType tabella.
L'esecuzione di un SELECT sulla stessa tabella del database di Publisher non mostra alcun record. Pertanto, tutte le modifiche apportate al database dell'abbonato non vengono replicate nel database dell'editore.
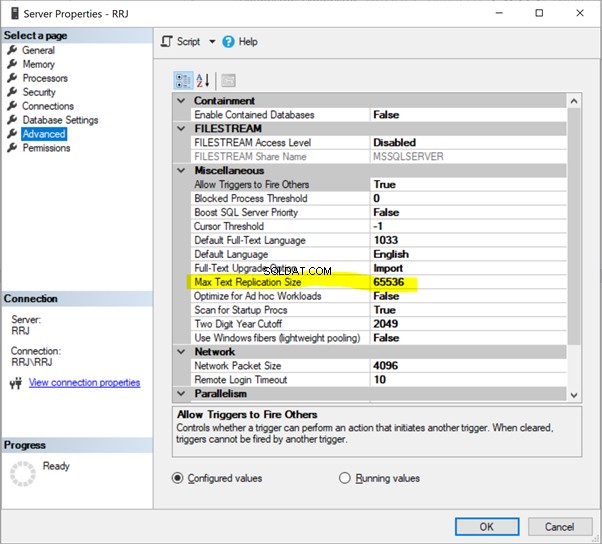
Modifica 2 – Eliminazione di 2 record dalla tabella Person.ContactType
Ci atteniamo al nostro familiare Person.ContactType tavolo. Prima di eliminare i record dal database dell'abbonato, è necessario verificare se tali record esistono sia nell'editore che nell'abbonato. Vedi sotto:
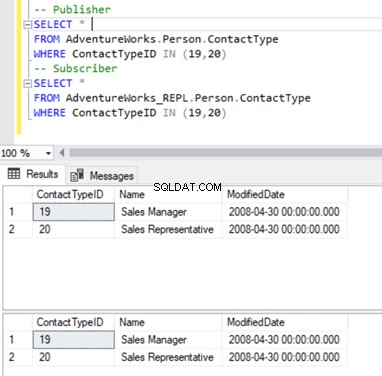
Ora possiamo eliminare questi 2 ContactTypeId utilizzando la seguente istruzione:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Lo script sopra ci consente di eliminare 2 record da Person.ContactType tabella nel database degli abbonati:
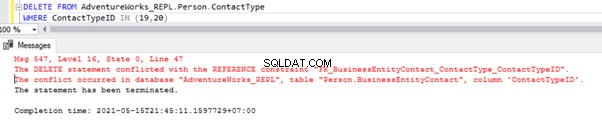
Abbiamo il riferimento alla chiave esterna che impedisce l'eliminazione di questi 2 record da Person.ContactType tavolo. Possiamo gestire questo scenario disabilitando temporaneamente il vincolo di chiave esterna sulla tabella figlio. Lo script è qui sotto:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Una volta disabilitate le chiavi esterne, possiamo eliminare correttamente i record da Person.ContactType tabella:
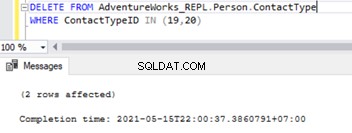
Ciò ha anche modificato il vincolo di riferimento della chiave esterna nelle 2 tabelle. Possiamo provare a simulare i problemi di replica SQL in base a questo scenario.
Nel nostro scenario attuale, sappiamo che Person.ContactType la tabella non disponeva di dati sincronizzati tra l'editore e l'abbonato.
Credimi, in pochi ambienti di produzione, gli sviluppatori o i DBA eseguono alcune correzioni dei dati sul database degli abbonati. come tutte le modifiche eseguite in precedenza, hanno causato problemi di integrità dei dati nei database dell'editore e dell'abbonato nella stessa tabella. Come DBA, ho bisogno di un meccanismo più semplice per verificare questo tipo di discrepanze. Altrimenti, renderebbe la vita del DBA patetica.
Ecco la soluzione di Microsoft che ci consente di verificare le discrepanze di dati tra le tabelle nell'editore e nell'abbonato. Sì, hai indovinato. È l'utilità TableDiff di cui abbiamo discusso negli articoli precedenti.
Utilità TableDiff
L'utilità TableDiff viene utilizzata principalmente negli ambienti di replica. Possiamo anche usarlo per altri casi in cui è necessario confrontare 2 tabelle di SQL Server per la non convergenza. Possiamo confrontarli e identificare le differenze tra queste 2 tabelle. Quindi l'utilità aiuta a sincronizzare la Destinazione tabella alla Fonte tabella generando gli script INSERT/UPDATE/DELETE necessari.
TableDiff è un programma autonomo tablediff.exe installato per impostazione predefinita in C:\Programmi\Microsoft SQL Server\130\COM una volta installati i componenti di replica. Si noti che il percorso predefinito può variare in base ai parametri di installazione di SQL Server. Il numero 130 nel percorso indica la versione di SQL Server (SQL Server 2016). Di conseguenza, varierà per ogni versione diversa dell'installazione di SQL Server.
È possibile accedere all'utilità TableDiff tramite il prompt dei comandi o solo da file batch. L'utilità non ha una procedura guidata o una GUI di fantasia da utilizzare. La sintassi dettagliata dell'utilità TableDiff è nell'articolo MSDN. Il nostro attuale articolo si concentra solo su alcune opzioni necessarie.
Per confrontare 2 tabelle utilizzando l'utilità TableDiff, è necessario fornire i dettagli obbligatori per le tabelle di origine e di destinazione, come il nome del server di origine, il nome del database di origine, il nome dello schema di origine, il nome della tabella di origine, il nome del server di destinazione, il nome del database di destinazione, la destinazione Nome schema e Nome tabella di destinazione.
Proviamo a testare TableDiff con Person.ContactType tabella con differenze tra l'editore e l'abbonato.
Aprire il prompt dei comandi e passare al percorso dell'utilità TableDiff (se tale percorso non è stato aggiunto alle variabili di ambiente).
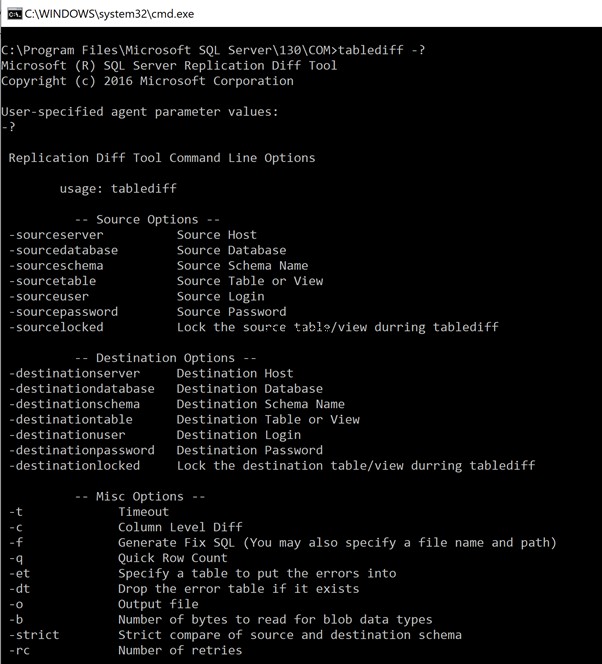
Per visualizzare l'elenco di tutti i parametri disponibili, digitare il comando “tablediff-?” per elencare tutte le opzioni e i parametri disponibili. I risultati sono di seguito:
Controlliamo la Persona.ContactType tabella nei nostri database publisher e abbonati eseguendo il comando seguente:
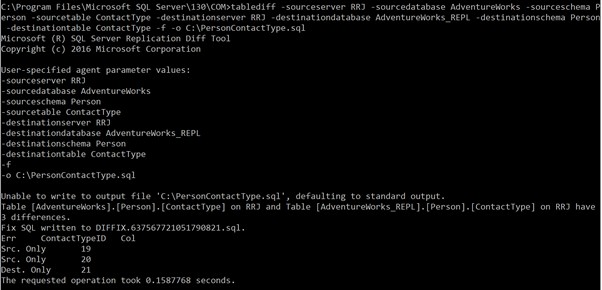
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeNota che non ho fornito sourceuser , password sorgente , utente di destinazione e password di destinazione poiché il mio login di Windows ha accesso alle tabelle. Se desideri utilizzare le credenziali SQL anziché l'autenticazione di Windows, i parametri sopra indicati sono obbligatori per accedere alle tabelle per il confronto . In caso contrario, riceverai errori.
I risultati della corretta esecuzione del comando:
Mostra che abbiamo 3 discrepanze. Uno è un nuovo record nel database di destinazione e due record non sono disponibili nel database di destinazione.
Ora, diamo una rapida occhiata alle Varie opzioni disponibili per l'utilità TableDiff.
- -et – registra il riepilogo dei risultati nella tabella di destinazione
- -dt – elimina la tabella di destinazione dei risultati se esiste già
- -f – genera uno script DML T-SQL con istruzioni INSERT/UPDATE/DELETE per portare la tabella di destinazione alla convergenza con la tabella di origine.
- -o – nome del file di output se l'opzione -f viene utilizzato per generare il file di convergenza.
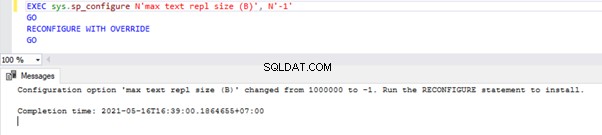
Creeremo un file di convergenza con -f e -o opzioni al nostro comando precedente:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlIl file di convergenza è stato creato correttamente:
Come puoi vedere, la creazione di un nuovo file nella cartella principale dell'unità C:non è consentita per motivi di sicurezza. Quindi, mostra un messaggio di errore e crea il file di output FILE DIFFIX.*.sql nella cartella dell'utilità TableDiff. Quando apriamo quel file, possiamo vedere i dettagli seguenti:

Gli script INSERT sono stati creati per i 2 record eliminati e gli script DELETE sono stati creati per i record appena inseriti nel database dell'abbonato. Lo strumento si preoccupa anche di utilizzare le opzioni IDENTITY_INSERT come richiesto per la Destinazione tavolo. Pertanto, questo strumento sarà di grande utilità ogni volta che un DBA deve sincronizzare due tabelle.
Nel nostro caso, non eseguirò gli script, poiché abbiamo bisogno di queste varianze per simulare i nostri problemi di replica SQL.
Vantaggi dell'utilità TableDiff
- TableDiff è un'utilità gratuita inclusa nell'installazione dei componenti di replica di SQL Server da utilizzare per il confronto o la convergenza delle tabelle.
- Gli script di creazione della convergenza possono essere creati senza intervento manuale.
Limitazioni dell'utilità TableDiff
- L'utilità TableDiff può essere eseguita solo dal prompt dei comandi o dal file batch.
- Dal prompt dei comandi, puoi eseguire un solo confronto di tabelle alla volta, a meno che tu non abbia più prompt dei comandi aperti in parallelo per confrontare più tabelle.
- La tabella Source da confrontare utilizzando l'utilità TableDiff richiede una chiave primaria o una colonna Identity definita oppure la colonna ROWGUID disponibile per eseguire il confronto riga per riga. Se il -rigoroso viene utilizzata l'opzione, la tabella Destinazione richiede anche una chiave primaria, o una colonna Identità, o la colonna ROWGUID disponibile.
- Se la tabella di origine o di destinazione contiene sql_variant datatype, non puoi utilizzare l'utilità TableDiff per confrontarlo.
- È possibile notare problemi di prestazioni durante l'esecuzione dell'utilità TableDiff su tabelle contenenti record di grandi dimensioni, poiché eseguirà il confronto riga per riga su queste tabelle.
- Gli script di convergenza creati dall'utilità TableDiff non includono le colonne del tipo di dati dei caratteri BLOB, come varchar(max) , nvarchar(max) , varbinary(max) , testo , ntext o immagine colonne e xml o timestamp colonne. Quindi, hai bisogno di approcci alternativi per gestire le tabelle con queste colonne di tipi di dati.
Tuttavia, anche con queste limitazioni, l'utilità TableDiff può essere utilizzata in qualsiasi tabella di SQL Server per una rapida verifica dei dati o un controllo della convergenza. Tuttavia, puoi anche acquistare un buon strumento di terze parti.
Ora, consideriamo in dettaglio i vari problemi di replica SQL.
Problemi di configurazione
In base alla mia esperienza, ho classificato le opzioni di configurazione della replica spesso perse che possono causare problemi critici di replica SQL come Configurazione problemi. Alcuni di loro sono sotto.
Dimensione massima della replica del testo
Dimensione massima della replica del testo fa riferimento alla dimensione massima della replica del testo in byte . Si applica a tutti i tipi di dati come char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, eimmagine .
SQL Server ha un'opzione predefinita per limitare la lunghezza massima della colonna del tipo di dati della stringa (in byte) da replicare come 65536 byte.
È necessario valutare attentamente la dimensione massima della replica del testo ogni volta che la replica è configurata per un database. Per questo, dobbiamo controllare tutte le colonne del tipo di dati sopra e identificare il massimo possibile di byte che verranno trasferiti tramite la replica.
La modifica del valore in -1 indica che non ci sono limiti. Tuttavia, ti consigliamo di valutare la lunghezza massima della stringa e di configurare tale valore.
Possiamo configurare Max Text Repl Size usando SSMS o T-SQL.
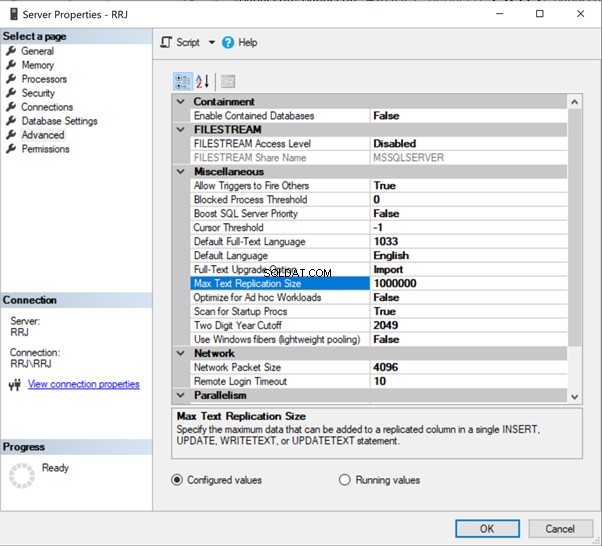
In SSMS, fai clic con il pulsante destro del mouse su Nome server> Proprietà > Avanzate :
Basta fare clic su 65536 per modificarlo. Per i test, ho cambiato 65536 in 1000000 e ho fatto clic su OK :
Per configurare l'opzione Max Text Repl Size tramite T-SQL, apri una nuova finestra di query ed esegui lo script seguente sul database master:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Questa query consentirà a Replication di non limitare la dimensione delle colonne del tipo di dati sopra.
Per verificare, possiamo eseguire una SELECT su sys.configurations DMV e controlla value_in_use colonna come di seguito:

Servizio SQL Server Agent non impostato per l'avvio della modalità automatica
La replica si basa sugli agenti di replica che vengono eseguiti come processi di SQL Server Agent. Pertanto, qualsiasi problema con alcuni servizi di SQL Server Agent avrà un impatto diretto sulla funzionalità di replica.
È necessario assicurarsi che la modalità di avvio di SQL Server e SQL Server Agent Services siano impostati su Automatico. Se impostato su Manuale, dovremmo configurare alcuni avvisi. Avrebbero notificato al DBA o agli amministratori del server di avviare il servizio SQL Server Agent quando il server riavvia quelli pianificati o non pianificati.
In caso contrario, la replica potrebbe non essere in esecuzione per molto tempo, il che influisce anche su altri processi di SQL Server Agent.
Le istanze di replica non monitorate entrano in uno stato di abbonamenti non inizializzati
Analogamente al monitoraggio del servizio SQL Server Agent, la configurazione del servizio di posta elettronica database in qualsiasi istanza di SQL Server svolge un ruolo fondamentale nell'avvisare tempestivamente DBA o la persona configurata. Per eventuali errori o problemi relativi ai processi, i processi di SQL Server Agent come l'agente di lettura log o l'agente di distribuzione possono essere configurati per inviare avvisi a DBA o al rispettivo membro del team tramite posta elettronica. L'errore dell'esecuzione del processo dell'agente di replica può portare agli scenari seguenti:
Mancata esecuzione del processo dell'agente di lettura log . Il file di registro delle transazioni del database di Publisher verrà riutilizzato solo dopo il comando contrassegnato per la replica viene letto dall'agente di lettura log e inviato correttamente al database di distribuzione. Altrimenti, il log_reuse_wait_desc colonna di sys.databases mostrerà il valore come Replica, indicando che il registro del database non può essere riutilizzato finché non trasferisce correttamente le modifiche al database di distribuzione. Pertanto, la mancata esecuzione dell'agente di lettura del registro continuerà ad aumentare le dimensioni del file di registro transazionale del database di Publisher e si verificheranno problemi di prestazioni durante il backup completo o problemi di spazio su disco nell'istanza del database di Publisher.
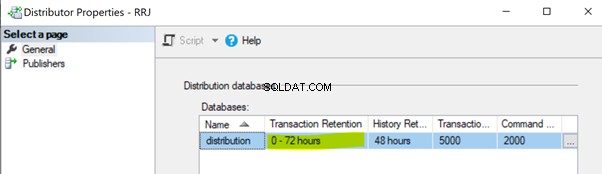
Mancata esecuzione del lavoro di agente di distribuzione. Il lavoro dell'agente di distribuzione legge i dati dal database di distribuzione e li invia al database dell'abbonato. Quindi contrassegna quei record per l'eliminazione nel database di distribuzione. Se il processo dell'agente di distribuzione non è in esecuzione, aumenterà le dimensioni del database di distribuzione causando problemi di prestazioni alle prestazioni complessive della replica. Per impostazione predefinita, il database di distribuzione è configurato per conservare i record per un massimo di 0-72 ore, come illustrato nella proprietà Conservazione transazione riportata di seguito. Se la replica non riesce per più di 72 ore, l'abbonamento corrispondente verrà contrassegnato come non inizializzato, costringendoci a riconfigurare l'abbonamento o a generare un nuovo snapshot per far funzionare nuovamente la replica.
Mancata esecuzione della pulizia della distribuzione:processo di distribuzione . Il processo di pulizia della distribuzione è responsabile dell'eliminazione di tutti i record replicati dal database di distribuzione per mantenere sotto controllo le dimensioni del database di distribuzione. La mancata esecuzione di questo processo porta all'aumento delle dimensioni del database di distribuzione con conseguenti problemi di prestazioni di replica.
Per assicurarci di non riscontrare nessuno di questi problemi non monitorati, Database Mail deve essere configurato per segnalare tutti gli errori di lavoro oi tentativi ai rispettivi membri del team per un'azione tempestiva.
Problemi noti all'interno di SQL Server
Alcune versioni di SQL Server hanno problemi di replica noti nella versione RTM o nelle versioni precedenti. Questi problemi sono stati risolti nei successivi Service Pack o CU Pack. Pertanto, si consiglia di applicare gli ultimi Service Pack o CU Pack una volta disponibili per tutto SQL Server dopo averli testati nell'ambiente QA. Anche se questa è una raccomandazione generale per i server che eseguono SQL Server, è applicabile anche per la replica.
Problemi di autorizzazione
In un ambiente con la replica transazionale di SQL Server configurata, possiamo osservare frequentemente i problemi di autorizzazione. Potremmo affrontarli durante il periodo della configurazione della replica o di qualsiasi attività di manutenzione sull'editore, sul distributore o sulle istanze del database dell'abbonato. Ne risulta la perdita di credenziali o autorizzazioni. Osserviamo ora alcuni frequenti problemi di autorizzazione relativi alla replica.
Problemi di autorizzazione dei processi di SQL Server Agent
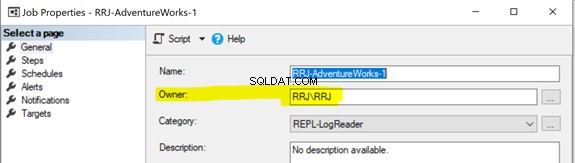
Tutti gli agenti di replica utilizzano i processi di SQL Server Agent. Ogni processo di SQL Server Agent correlato allo snapshot o all'agente di lettura log o alla distribuzione viene eseguito con alcune credenziali di accesso di Windows o SQL, come illustrato di seguito:
Per avviare un processo di SQL Server Agent, è necessario possedere il SQLAgentOperatorRole per avviare tutti i processi o SQLAgentUserRole o il SQLAgentReaderRole per avviare lavori di tua proprietà. Se un lavoro non può essere avviato correttamente, controlla se il proprietario del lavoro dispone dei diritti necessari per eseguire quel lavoro.
Le credenziali del lavoro dell'agente snapshot non possono accedere al percorso della cartella snapshot
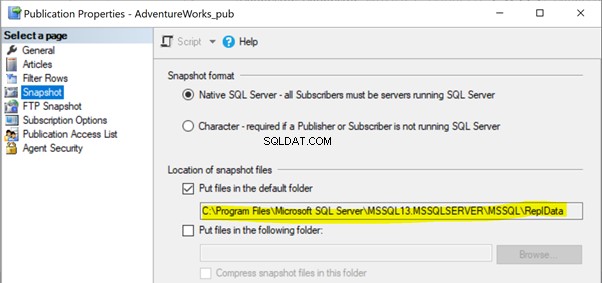
Nei nostri articoli precedenti, abbiamo notato che l'esecuzione dell'agente snapshot creava lo snapshot degli articoli nel percorso della cartella locale o condivisa da propagare al database dell'abbonato tramite l'agente di distribuzione. La posizione del percorso dell'istantanea può essere identificata nelle Proprietà della pubblicazione > Istantanea :
Se l'agente snapshot non ha accesso a questa posizione dei file snapshot, potremmo ricevere l'errore:
L'accesso al percorso 'C:\Programmi\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\AAAAMMDDHHMISS\' è negato.
Per risolvere il problema, è meglio concedere l'accesso completo al percorso della cartella C:\Programmi\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ per l'account con cui viene eseguito l'agente snapshot. Nella nostra configurazione, utilizziamo l'account SQL Server Agent e il servizio SQL Server Agent è in esecuzione con l'account RRJ\RRJ.
Le credenziali di lavoro dell'agente di lettura log non possono connettersi al database di pubblicazione/distribuzione
Log Reader Agent si connette al database di Publisher per eseguire sp_replcmds procedura per cercare le transazioni contrassegnate per la replica dai registri transazionali del database di Publisher.
Se il proprietario del database del database dell'editore non è impostato correttamente, potremmo ricevere i seguenti errori:
Il processo non ha potuto eseguire "sp_replcmds" su "RRJ.
Oppure
Impossibile eseguire come entità database perché l'entità "dbo" non esiste, questo tipo di entità non può essere rappresentato o non si dispone dell'autorizzazione.
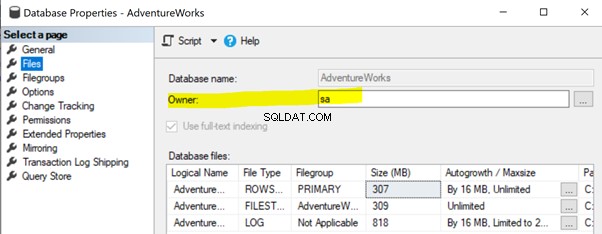
Per risolvere questo problema, assicurati che la proprietà del proprietario del database del database di Publisher sia impostata su sa o un altro account valido (vedi sotto).
Fare clic con il pulsante destro del mouse su Editore database (AdventureWorks )> Proprietà > File . Assicurati che il Proprietario il campo è impostato su sa o qualsiasi login valido e non vuoto .
Se si verificano problemi di autorizzazione durante la connessione all'editore o al database di distribuzione, controlla le credenziali utilizzate per l'agente di lettura log e concedi loro le autorizzazioni per accedere a tali database.
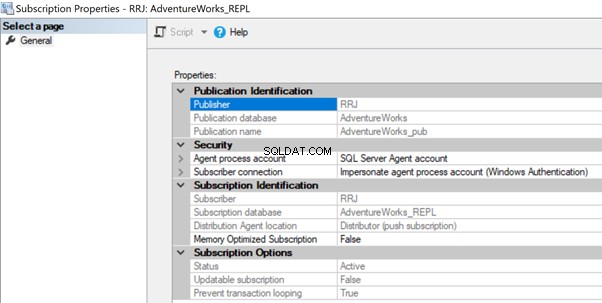
Le credenziali di lavoro dell'agente di distribuzione non possono connettersi al database di distribuzione/abbonato
L'agente di distribuzione potrebbe avere problemi di autorizzazione se all'account non è consentito accedere al database di distribuzione o connettersi al database dell'abbonato. In questo caso, potremmo ricevere i seguenti errori:
Impossibile avviare l'esecuzione del passaggio 2 (motivo:errore nell'autenticazione del proxy RRJ\RRJ, errore di sistema:il nome utente o la password non sono corretti.)
Il processo non ha potuto connettersi all'abbonato "RRJ.
Accesso non riuscito per l'utente "RRJ\RRJ".
Per risolverlo, controlla l'account utilizzato nelle Proprietà dell'abbonamento e assicurati che disponga delle autorizzazioni necessarie per connettersi al database di distribuzione o abbonato.
Problemi di connettività
Di solito configuriamo la replica transazionale su server all'interno della stessa rete o in posizioni geograficamente distribuite. Se il database di distribuzione si trova su un server dedicato diverso dall'editore o dall'abbonato, diventa soggetto a perdite di pacchetti di rete:problemi di connettività.
In caso di tali problemi, gli agenti di replica (lettore log o agente di distribuzione) possono segnalare i seguenti errori:
Il server dell'editore non è stato trovato o non era accessibile
Il server di distribuzione non è stato trovato o non era accessibile
Il server dell'abbonato non è stato trovato o non era accessibile
Per risolvere questi problemi, potremmo provare a connetterci al database dell'editore, del distributore o dell'abbonato in SSMS per verificare se siamo in grado di connetterci a queste istanze di SQL Server senza problemi o meno.
Se i problemi di connettività si verificano frequentemente, possiamo provare a eseguire il ping del server continuamente per identificare eventuali perdite di pacchetti. Inoltre, dobbiamo collaborare con i membri del team necessari per risolvere questi problemi e rendere operativo il server affinché Replication riprenda il trasferimento dei dati.
Problemi di integrità dei dati
Poiché la replica transazionale è un meccanismo unidirezionale, eventuali modifiche ai dati che si verificano sull'abbonato (manualmente o dall'applicazione) non si rifletteranno sull'editore. Potrebbe causare differenze nei dati tra l'editore e l'abbonato.
Esaminiamo i problemi relativi all'integrità dei dati e vediamo come risolverli. Nota che abbiamo inserito un record in Person.ContactType tabella ed eliminato 2 record da Person.ContactType tabella nel database dell'abbonato. Utilizzeremo questi 3 record per trovare gli errori.
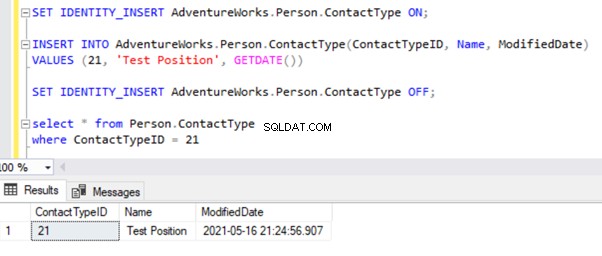
La chiave primaria o gli errori di violazione della chiave univoca
Testerò il record INSERT su Person.ContactType tavolo. Inseriamo quel record nel database dell'editore e vediamo cosa succede:
Avvia Replication Monitor per vedere come va. Otteniamo l'errore:
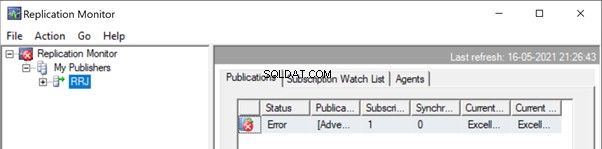
Editore in espansione e Pubblicazione , otteniamo i seguenti dettagli:
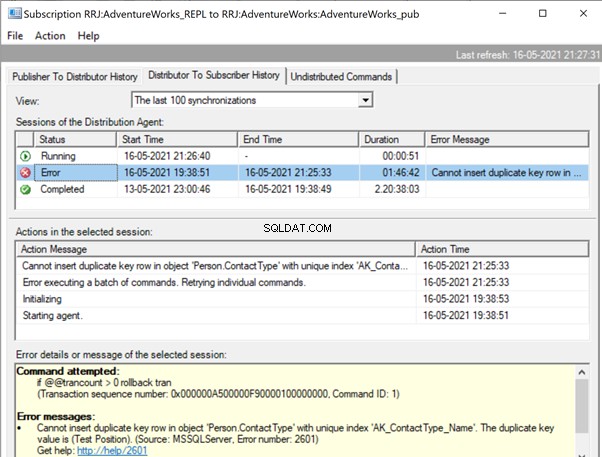
Se abbiamo configurato gli avvisi di replica e assegnato alle rispettive persone la ricezione dell'avviso e-mail, riceveremo le notifiche e-mail appropriate con il messaggio di errore:Impossibile inserire una riga di chiave duplicata nell'oggetto 'Person.ContactType' con indice univoco 'AK_ContactType_Name ' . Il valore della chiave duplicata è (Posizione di test). (Fonte:MSSQLServer, numero di errore:2601)
Per risolvere il problema relativo alle violazioni della chiave univoca o ai problemi della chiave primaria, abbiamo diverse opzioni:
- Analizza perché si è verificato questo errore, come il record era disponibile nel database dell'iscritto e chi lo ha inserito per quali motivi. Identifica se era necessario o meno.
- Aggiungi gli skiperror parametro al profilo dell'agente di distribuzione per ignorare Errore numero 2601 o Errore numero 2627 in caso di violazione della Chiave Primaria.
Nel nostro caso, abbiamo inserito di proposito dei dati per ricevere questo errore. Per gestire questo problema, elimina il record inserito manualmente per continuare a replicare le modifiche ricevute dall'editore.
DELETE from Person.ContactType
where ContactTypeID = 21
Per studiare altre opzioni e confrontare le differenze tra questi due approcci, sto saltando la prima opzione (che è efficiente e consigliata) e procedo alla seconda opzione aggiungendo gli -skiperrors parametro al lavoro dell'agente di distribuzione.
Possiamo implementarlo modificando il Lavoro dell'agente di distribuzione > Passaggi > fai clic su 2 Fase del lavoro denominata Esegui agente > fai clic su Modifica per visualizzare il comando disponibile:
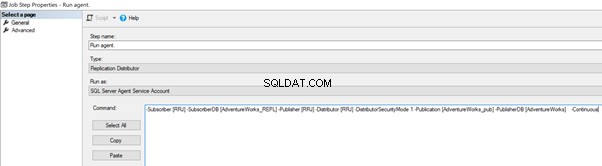
Ora aggiungi -SkipErrors 2601 parola chiave alla fine (2601 è il numero di errore:possiamo saltare qualsiasi numero di errore ricevuto come parte della replica) e fare clic su OK .
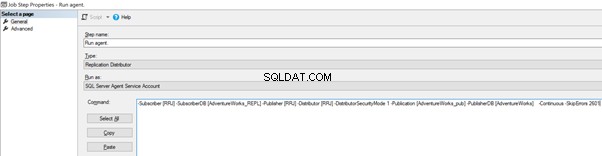
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
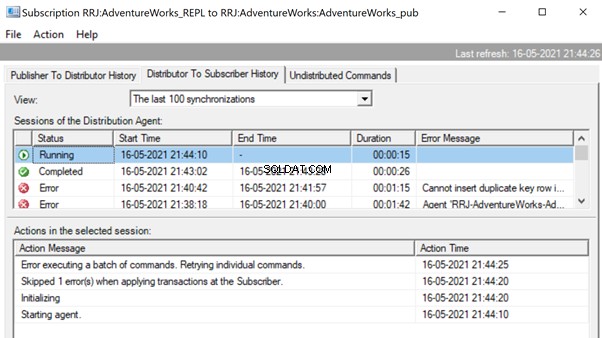
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
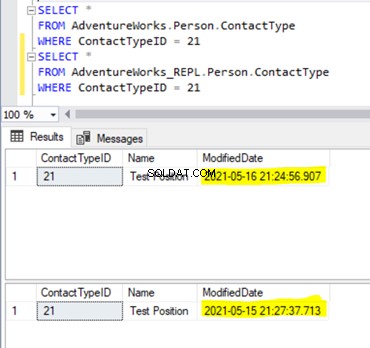
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors comando.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
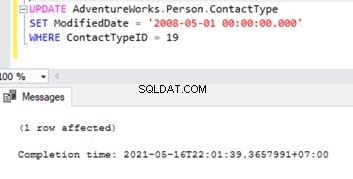
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
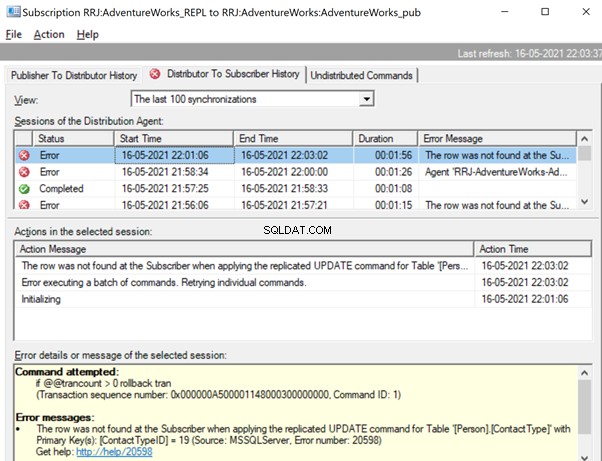
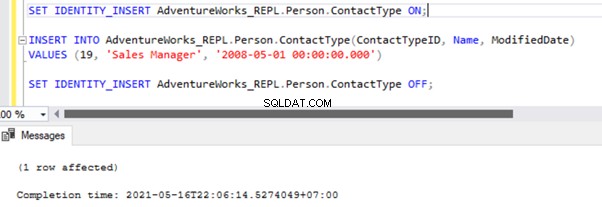
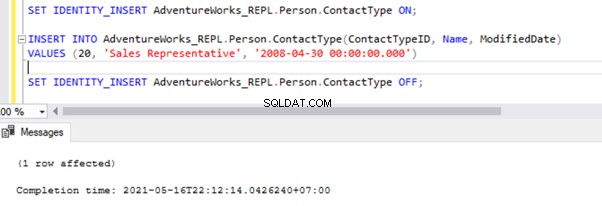
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors option. Instead, we’ll apply the INSERT approach.
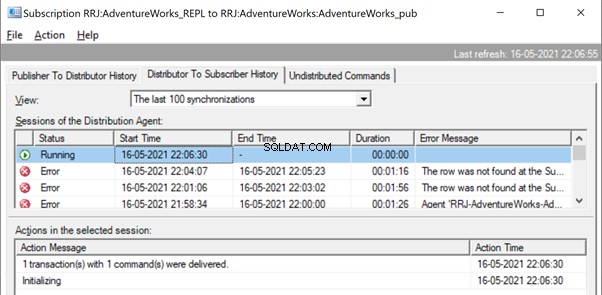
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
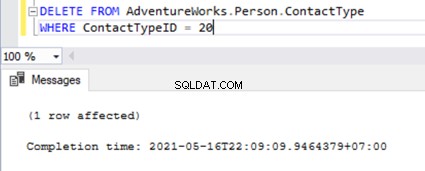
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
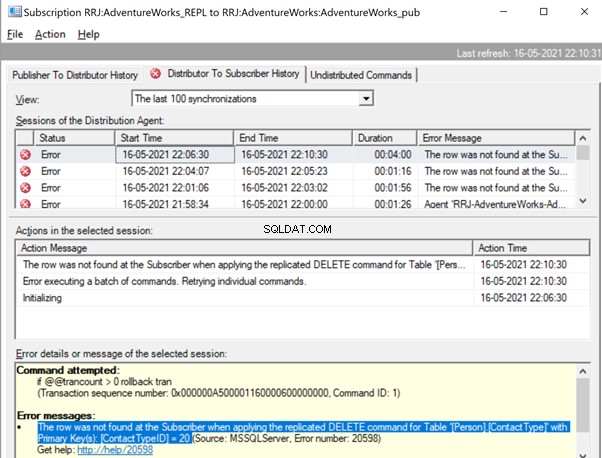
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Conclusion
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.